







 XTREME 是一个大规模的多语言多任务基准,旨在评估 NLP 模型的跨语言泛化能力。它涵盖 40 种语言和 9 项推理任务,包括句子分类、结构化预测等。XTREME 使用零样本设置,通过预训练、微调和跨语言迁移学习来测试模型性能,尤其关注那些未被充分研究的语言。实验结果显示,尽管有进步,但模型在非英语任务上仍有很大提升空间,尤其是在结构化预测和问答任务上。
XTREME 是一个大规模的多语言多任务基准,旨在评估 NLP 模型的跨语言泛化能力。它涵盖 40 种语言和 9 项推理任务,包括句子分类、结构化预测等。XTREME 使用零样本设置,通过预训练、微调和跨语言迁移学习来测试模型性能,尤其关注那些未被充分研究的语言。实验结果显示,尽管有进步,但模型在非英语任务上仍有很大提升空间,尤其是在结构化预测和问答任务上。
文 / Google Research 高级软件工程师 Melvin Johnson 与 DeepMind 研究员 Sebastian Ruder
自然语言处理 (NLP) 面临的主要挑战之一在于:构建的系统不仅要能在英语环境中运行,而且还需能适用于全球 所有 语言(约有 6900 种)。幸运的是,尽管全球大多数语言都 存在语料数据稀疏的问题,没有足够的数据可用于单独训练稳健的模型,但许多语言都有着大量相同的基底结构 (Underlying Structure)。如在词汇层面,不同语言之间常存在不少同源词,例如,英语的 “desk” 和德语的 “Tisch” 均源自拉丁文 “discus”。同样,许多语言也以类似的方式来标注语义角色,例如,中文和土耳其语均使用后置词来标注时空关系。
在 NLP 中,大多都采用在训练中利用多种不同语言的共享结构的方法来解决数据稀疏性问题。根据以往的经验来看,这些方法大多专注于使用多种语言执行特定任务。而过去几年间,在深度学习技术进步的推动下,尝试通过学习 通用多语言表示法 (例如,mBERT、XLM、XLM-R)的训练方法有所增加,这些方法旨在捕获可在多种语言之间共享的且可用于多种任务的知识。但在实践过程中,此类方法主要集中用于评估少量任务,以及语言学层面上有相似性的语言上。
为鼓励更多关于多语言学习的研究的开展,我们推出用于评估跨语言泛化的大规模多语言多任务基准 XTREME (XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization),此基准包括了 40 种类型多样的语言(涵盖 12 个语系),且包括九项推理任务,这些任务需要共同对不同级别的语法或语义进行推理。XTREME 使用的基准语言旨在最大化提升语言多样性、现有任务的覆盖范围以及训练数据的可用性。
用于评估跨语言泛化的大规模多语言多任务基准 XTREME
https://arxiv.org/abs/2003.11080
在这些语言中,包括许多尚未得到充分研究的语言,例如德拉维语系的泰米尔语(印度南部、斯里兰卡和新加坡使用的语言),泰卢固语和马拉雅拉姆语(主要在印度南部使用的语言)以及尼日尔-刚果语系的斯瓦希里语和约鲁巴语(来自非洲)。如需相关代码和数据(包括用于运行各种基准的示例),请参阅此处 (https://github.com/google-research/xtreme)。
XTREME 任务和语言
XTREME 中的任务涵盖一系列范式,如句子分类、结构化预测、句子检索和问答系统。因此,为了使模型在 XTREME 基准中获得成功,它们必须学习可泛化到多种标准跨语言迁移环境的表示法。
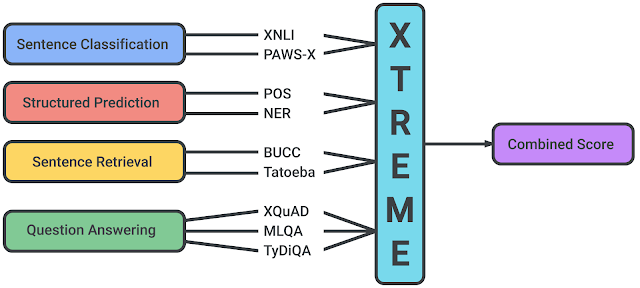
XTREME 基准支持的任务
每个任务都包含一个 40 种语言的子集。为获取
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 59
59

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









