







作者:wjmishuai
出处: http://blog.csdn.net/wjmishuai/article/details/50854155
1.引言
本文中介绍的人脸识别系统是基于这两篇论文:
《Very deep convolutional networks for large-scale image recognition》
2.关于深度学习的简要介绍
3. 人脸识别系统的原理
一张人脸图片是由基本的edge构成。但是更结构化,更复杂,具有概念性的特征如何表示?这就需要更高层次的特征表示,比如V2,V4。因此V1是像素级特征。V2看V1是像素级的,层次递进,高层表达由低层表达的组合而成。专业点说就是基basis。V1取提出的basis是边缘,然后V2层是V1层这些basis的组合,这时候V2区得到的又是高一层的basis。即上一层的basis组合的结果,上上层又是上一层的组合basis……

直观上说,就是找到make sense的小patch再将其进行combine,就得到了上一层的feature,递归地向上learning feature。
在不同object上做training是,所得的edge basis 是非常相似的,但object parts和models 就会completely different了(那咱们分辨car或者face是不是容易多了):

从文本来说,一个doc表示什么意思?我们描述一件事情,用什么来表示比较合适?用一个一个字嘛,我看不是,字就是像素级别了,起码应该是term,换句话说每个doc都由term构成,但这样表示概念的能力就够了嘛,可能也不够,需要再上一步,达到topic级,有了topic,再到doc就合理。但每个层次的数量差距很大,比如doc表示的概念->topic(千-万量级)->term(10万量级)->word(百万量级)
VGG_Face 网络的配置,列出了每一层滤波器的大小和数量,并且指明了步长和padding的方式:
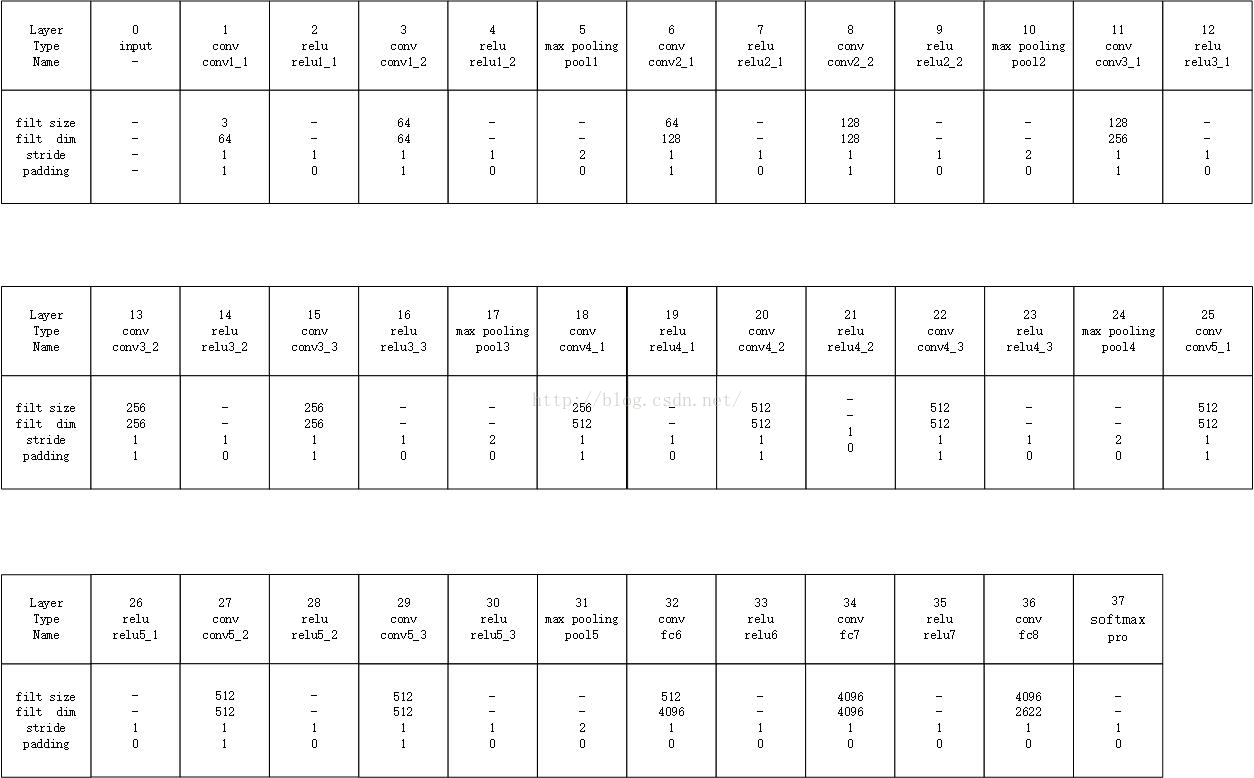
相关参数的介绍:http://blog.csdn.net/wjmishuai/article/details/50890214
4. 模型的训练过程
如果没有实验条件的话,不建议训练vgg_net。时间太长了,除非你有泰坦x显卡或者更好的显卡,这里给出训练的过程(基于caffe框架),有条件的可以做一下:
5.预训练好的模型
我们这里直接给出训练好的人脸识别模型:链接:http://pan.baidu.com/s/1qX4Ozc4 密码:3arl















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









