







Access 作为桌面型数据库,基本功能之一就是提供数据查询。查询要用到结构化查询语言,即 SQL(Structured Query Language)。
SQL 语法有两种标准(美国国标):ANSI-89 和 ANSI-92。ANSI-89 SQL,也叫做 Microsoft Jet SQL 和 ANSI SQL,是传统的 Jet SQL 语法;ANSI-92 SQL 有新的和不同的保留字,语法规则和通配符(Wildcard)。也就是说,ANSI-89 和 ANSI-92 是不兼容的。
对于SQL 这两种不兼容的标准,在 Access 2003 的数据库中(指 MDB 文件),我们可以设置该数据库查询时支持哪种标准,也称为设置 Access 数据库(MDB)的 ANSI SQL 查询模式。
改变 Access 数据库的 ANSI SQL 查询模式时要当心。SQL 语言的这两种规范,在保留字,通配符和数据类型方面都有所不同。改变查询模式后,现有的查询可能会无法运行或不能返回期望的结果。
用下面的步骤改变当前数据库的 ANSI SQL 查询模式:
- 点击 Tools 菜单-> Options,在打开的对话框中点击 Tables/Queries 选项卡。
- 在对话框的右下角,勾上 This database 复选框将查询模式设为 ANSI-92 SQL。清除 This database 复选框则表示查询时采用 ANSI-89 SQL 语法规范。
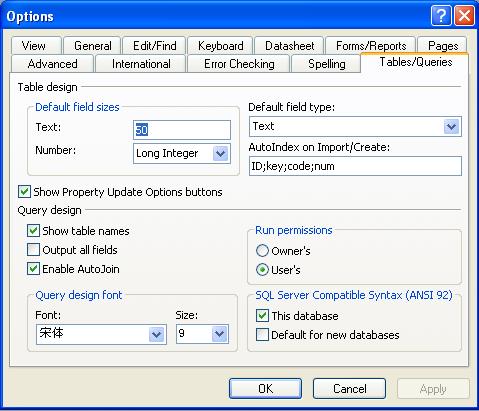
注意: Microsoft Access 会关闭,压缩并重新打开数据库以使新设置生效。
Access 2003 能保存成 2002-2003 和 2000 两种文件格式。保存成 Access 2000 文件格式,Access 2000 程序也可以打开该文件;如果保存成 Access 2002-2003 文件格式,Access 2000 程序就不能打开该文件了,只有 Access 2002 及后继版本的程序才能打开。对于 2000 这种文件格式,上图中 Default for new databases 选项是灰掉的不能选的。也就是说,如果新建的数据库文件是 Access 2000 文件格式,无法默认设置为 ANSI-92 查询模式,ANSI-89 查询模式是唯一可用的默认选项。而对于Access 2002-2003 文件格式,我们可以设置 ANSI-89 或 ANSI-92 是新建 Access 数据库时的默认设置。
评论:既然 Access 2000 文件格式的数据库在创建后可以用上面讲的方法修改查询模式为 ANSI-92 ,禁止 Access 2003 程序默认设置 ANSI-92 有什么意义呢?
既然Access 2000 文件格式不能自定义默认配置(只能是ANSI-89) ,我们先看看怎么样在新建 Access 数据库时默认为Access 2002-2003 文件格式。
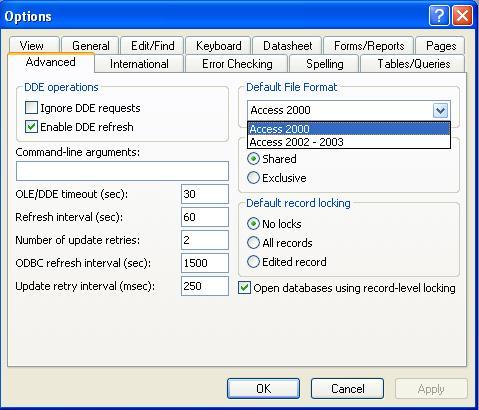
- 点击 Tools 菜单-> Options,在打开的对话框中点击 Advanced 选项卡。
- 从 Default File Format 下拉列表框里选择 Access 2002 - 2003。
- 再点击 Tables/Queries 选项框。
- 勾上 Default for new databases 复选框将 ANSI-92 设为默认查询模式;清除 Default for new databases 复选框将 ANSI-89 设为默认查询模式
我们在两种 ANSI SQL查询模式下都可以创建 SQL 查询
- Access 的 ANSI-89 查询模式用的是传统的 Jet SQL 语法。 这种模式总体上跟 ANSI-89 Level 1 的规范是一致的,但某些 ANSI-89 SQL 性能没有实现,并且通配符是跟 VBA(Visual Basic for Applications)规范一致,而不是跟 SQL 一致。
- ANSI-92 提供了新的保留字,语法规则和通配符,增强了我们创建查询,过滤的能力。Access 2000 程序不能设置 ANSI-92 查询模式,也就不能直接生成符合 ANSI-92 规范的查询对象;但是我们可以在 Access 2000 程序里通过编程的方法使用 ADO 对象,而 ADO 是支持ANSI-92 规范的。
为什么要用 ANSI-92 SQL 呢?有下面几个理由:
- 你预期在未来把数据库程序升级为 Access 项目。Microsoft Access project 自己不保存表和视图这样的数据对象,而是连接到 Microsoft SQL Server 数据库,主要用于创建客户端/服务器(client/server)程序;而 MS SQL SQL 的配置是 ANSI-92 规范。
- 你想利用 ANSI-89 SQL 中不存在的新性能,比如:
- 用 SQL 语句 GRANT 和 REVOKE 修改安全设置。
- 在聚合函数里使用 DISTINCT 保留字,比如,SUM(DISTINCT Price)。这种写法只能在 Access 项目(.adp)文件里用,Access 数据库(.mdb)文件不支持这种写法。
- 使用 LIMIT TO nn ROWS 子句限制查询返回的行数。
要注意的一点就是,我们要避免在两种查询模式下分别创建查询然后混在一起用。我们前面说过,两种查询模式在保留字,通配符和数据类型方面都有所不同。在不同模式下生成的查询可能会不能用或不能返回期望的结果。所以我们在创建 Access 数据库时要想好要使用的查询模式。
使用通配符的查询示例
在准则表达式里使用通配符的查询在不同的查询模式下会产生不同的结果。比如:
- 符合 ANSI-89 SQL 规范的查询在 ANSI-92 查询模式下运行:
SELECT * FROM Customers WHERE Country Like 'U*'
从 customers 表里返回 country 字段等于"U*"的所有记录,而不是 Country 字段以字母"U"开头的所有记录,因为星号(*)在 ANSI-92 SQL 里不是通配符。
- 符合 ANSI-92 SQL 规范的查询在 ANSI-89 查询模式下运行:
SELECT * FROM Customers WHERE Country Like 'U%'
从 customers 表里返回 country 字段等于"U%"的所有记录,而不是 Country 字段以字母"U"开头的所有记录,因为百分号(%)在 ANSI-89 SQL 里不是通配符。
字段名和字段别名重复的例子
在一个查询中,如果某个字段的别名和基础表里的字段名重复,当你基于这个意义含糊的名字进行计算时,在不同的查询模式下会产生不同的结果。比如:
SELECT Orders.OrderID AS Freight, Orders.Freight, [Freight]*1.1 AS [New Freight] FROM Orders;
在 ANSI-92 SQL 模式下,Access 基于 Freight 基础字段计算 New Freight 字段的值,将每个 Freight 字段的值提高10%。在 ANSI-89 SQL 模式下,Access 基于 Freight 字段别名计算 New Freight 字段的值,将每个 OrderID 的值提高10%。
通过上面的例子,我们看到在两种不同的查询模式下混用查询会造成的问题。要避免出现这种情况,我们可以采取以下注意事项:
- Access 2002-2003文件格式的数据库如果设成使用 ANSI-92 SQL 查询模式,避免将它转成 2000 或 97 的文件格式。
- 避免在创建过查询后再改变 ANSI SQL 查询模式。如果一定要这样做,在新的查询模式下测试已有的查询,保证能够运行并返回期望的结果,必要的话要修改写好的查询。
- 避免在两个不同查询模式的 Access 数据库之间导入/导出查询。
- 避免在已有的数据库应用程序中改变 ANSI SQL 查询模式。
在 Access 2000 版中,我们只能用编程的方式改变 ANSI SQL 查询模式,任何在 ANSI-92 模式下创建的查询不能在“Database”窗口中看到(Database 窗口指刚打开 Access 数据库或 Access 项目时出现的窗口)。在 Access 2002 和后继版本中,用户可以通过界面改变 ANSI SQL 查询模式,ANSI-92 模式下生成的查询在“Database”窗口中不再隐藏,会显示出来。我们应该防止故意或意外地改变数据库应用程序的查询模式。
- 避免使用含义不清的别名和字段名,要保证别名和字段名在 SQL 语句里是唯一的。
Microsoft Jet SQL 和 ANSI SQL 的比较
Microsoft Jet 数据引擎 SQL 总体上跟 ANSI-89 Level 1 是兼容的,但某些 ANSI SQL 性能在 Microsoft Jet SQL 里没有实现。 Microsoft 发布的 Jet 4.X 版本,以及“Microsoft OLE DB Provider for Jet” 推出了更多的 ANSI-92 SQL 语法。在另一方面,Microsoft Jet SQL 包含了 ANSI SQL 不支持的保留字和性能。
主要的不同
- Microsoft Jet SQL 和 ANSI SQL 各自有不同的保留字和数据类型。可参考下列链接:
List of Microsoft Jet 4.0 reserved words
Equivalent ANSI SQL Data Types - 对于下面所示的语法结构应用的规则不一样:
expr1 [NOT] Between value1 And value2
在 Microsoft Jet SQL 中,value1 可以比 value2 大;在 ANSI SQL 中, value1 一定要小于等于 value2
- 当我们用 Like 操作符进行模糊查询时,Microsoft Jet SQL 既支持 ANSI SQL 的通配符,也支持 Microsoft Jet 特有的通配符。但是 ANSI 和 Microsoft Jet 的通配符是互斥的,我们只能选用任一组字符而不能混用在一起。ANSI SQL 通配符只在使用 Jet 4.X 和 Microsoft OLE DB Provider for Jet 时可用。如果试图通过 Microsoft Access 或 DAO 来使用 ANSI SQL 通配符,这些字符会被理解为普通字符。反之,当使用 Microsoft OLE DB Provider for Jet 和 Jet 4.X 时只能使用 ANSI SQL 通配符。
匹配的字符 Microsoft Jet SQL ANSI SQL 任意单个字符 ? _ (下划线) 零或多个字符 * % - Microsoft Jet SQL 语法通常上不是很严格。比如,允许对表达式分组和排序。
- Microsoft Jet SQL 支持更强大的表达式。
Microsoft Jet SQL 提供下列扩展的性能
- TRANSFORM 语句,可以用来创建 crosstab 查询。
- 额外的 SQL 聚合函数,比如 StDev 和 VarP。
- PARAMETERS 声明用来定义参数查询。
Microsoft Jet SQL 不支持下列 ANSI SQL 性能:
- DISTINCT 聚合函数保留字。比如,Microsoft Jet SQL 不允许 SUM(DISTINCT columnname)。
- LIMIT TO nn ROWS 子句,用来限制查询返回的行数。我们只能用 WHERE 子句来限制查询的范围。

















 991
991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









