







“大数据”现在可谓越来越火了,不管是什么行业,也不敢是不是搞计算机的,都要赶个集,借着这股热潮,亦或炒作,亦或大干一番。尤其是从事IT行业的,不跟“大数据”沾点边,都不好意思出去说自己是干IT的。
“大数据”一词,已无从考证具体是什么时候兴起的,只是隐约记得大概火了三四年了吧。多大的数据算“大数据”哪?麦肯锡研究中心给出的定义是“超过一般计算机处理能力”的数据。好吧,这个概念真是投机取巧,让人难以攻击。因为大数据的界限真的难以定义。只能说我们平时自己保存和处理的数据都不是大数据。有些人以为自己电脑里有个特别大的Excel文件就是大数据;还有些人觉得有个数据库装了些数据就是大数据;有些闷骚男们说了:我专门买了个盘存了好几T的片片那,看我有这么大的数据……这些都不是大数据。
按照麦肯锡的定义,既然大数据是一般的计算机都处理不了的数据,那么肯定不是几个尺寸大点儿的文件就可以被称之为大数据。笔者斗胆总结一下大数据的几个特性:
首先,大数据肯定是存储量很大的数据。
这是前提条件。业界没有给出明确的数量定义,但肯定不能低于TB级。否则一般的个人电脑就可以轻松处理,就没有多大的研究价值了。
其次,大数据一定是没有明确组织规律的。
虽然局部可能有些规律可循,但总体上一定是没有统一的规律了。否则也没有多大的研究价值。可能兼顾了表格、图片、日志等多种类型的数据,甚至可能会有各种格式的视频和音频流。
第三,大数据一定是不容易分析的。
接着第二点来说,大数据肯定不会是单纯的存储和组织方式,不会像我们平时自己造的表格那样简单明了。而且,我们无法从中分析出一个简单统一的公式,使得所有数据都可以满足这个公式。即便是可以分析出某些公式来,也会形成成百上千个公式。所以,大数据的分析一定不是一蹴而就的,而是分布开展的。可能先会得到一些最原始的规律,再从这些原始规律中去分析出更高级的规律……不知会经过多少步才会得到最终有些价值的信息。
第四、大数据一般是动态的。
大数据一般不会是死或一成不变的数据,而是会不断追加新的数据,从而其尺寸不断变大。比如常见的就是操作日志、监测数据……等等。常见的大数据包括大型机场的订票或飞行数据、大型超市的用户购物记录、证券公司股民的股票交易记录、化工厂的设备运行监测数据、城市出租车起止位置数据、煤矿等作业区域的人员定位数据……等等。这些数据除了数据量很大外,还会实时产生海量的新数据。所以进行大数据分析时要充分考虑到数据的变化因素。
第五、大数据一般是用于预测的。
正如上段内容中介绍的,大数据环境一定是海量的数据环境,并且增量都有可能是海量的。大数据分析的价值就是从已有的数据中分析出固有的一些规律,从而能够与未来新产生的数据相吻合,从而可以提前预测未来会发生的一些事件,或提供一些有价值的信息,提前进行决策和处置。
忽然想起了多年前大学期间学过一门课程,叫《数据挖掘》,里面提到了数据挖掘针对的对象是“数据仓库”,指的就是数据量很大的数据。为此还提出了钻取、抽析等多种分析方法和理论。现在看来个人感觉大数据应该就是从数据挖掘的基础上发展起来的,只不过大数据面对的数据量比数据挖掘理论盛行时还要大很多个数量级吧。
正因为大数据的特殊性,所以已经不能用通常的理论和方法来处理了。
首先是大数据的存储。前面说了,大数据面对的数据量异常大,不是几块几个TB的硬盘就可以随随便便容纳得了的。而且个人电脑上的存储设备一般也无法容纳如此大量的数据。为了能够提供快速、稳定地存取这些数据,至少得依赖于磁盘阵列。同时还得通过分布式存储的方式将不同区域、类别、级别的数据存放于不同的磁盘阵列中。
以往的关系型数据库受限于设计模式的限制,一般只考虑到了单机的数据存储方式,即不管数据量大与小,一定会让一台机器存储和管理所有数据(即便是做集群,集群中的每个节点实际上也是要把所有的数据再存储一遍)。而每台机器上可以承载的存储设备是有限的,一般也不会超过几个TB。而且一旦某个数据库的数据量和文件的尺寸暴增到一定程度后,数据的检索速度就会急剧下降。
为了应对这个问题,很多主流的数据库纷纷提出了一些解决方案。如MySQL提供了MySQL proxy组件,实现了对请求的拦截,结合分布式存储技术,从而可以将一张很大的表中的记录拆分到不同的节点上去进行查询。对于每个节点来说,数据量不会很大,从而提升了查询效率。
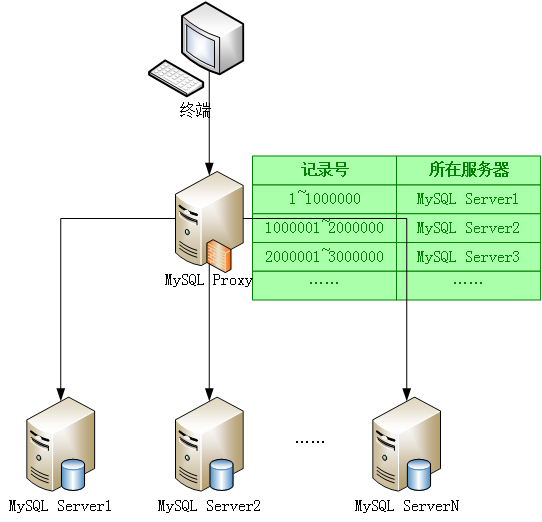
而Oracle针对大数据公开可查询的资料是“大数据机X3-2+Hadoop+NoSQL”的解决方案。在这套方案中,Oracle提供了拥有288个CPU、1152G内存、648T硬盘的无比豪华的服务器配置,同时结合Hadoop和NoSQL等技术对其中存储的大数据进行分析:
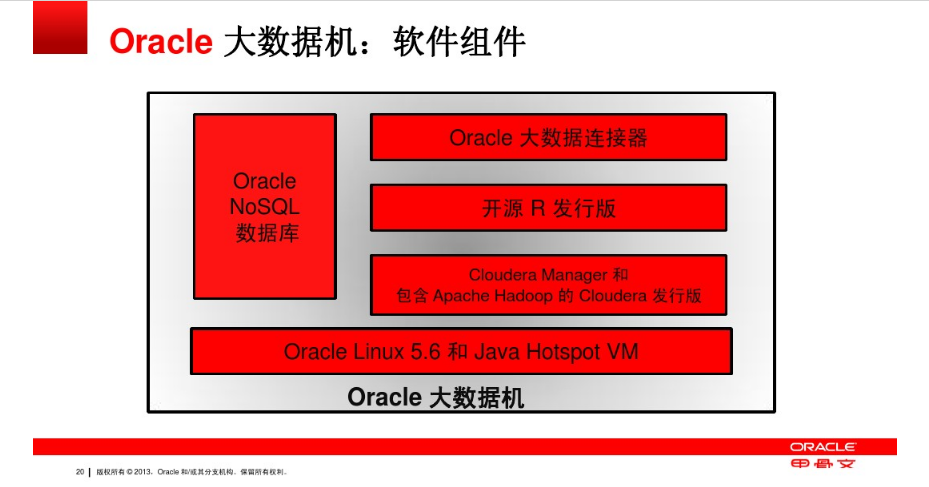
怎么说那,个人感觉Oracle完全是土豪策略:有钱你才能玩大数据,而有了钱你就买个特别牛×的机器,这样你就不怕数据大了。实际上Oracle并没有从根儿上专门为大数据而动过手术。
而对于像MongoDB、HBase等非关系型数据库,由于摆脱了表的存储模式,再加上起步较晚,所以对大数据的响应要比关系型数据库快的多。
MongoDB和HBase天生都支持分布式存储,即将一份大的数据分散到不同的机器上进行存储,从而降低了单个节点的存取压力。
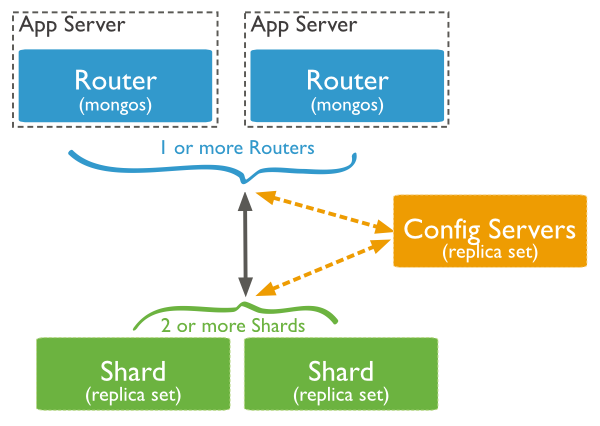
所以在实际应用中,如果是针对老的系统尤其是老的数据库进行大数据存储及分析,那么只能考虑横向拆分关系型数据库中的数据了;如果是准备建设新的系统,那么最好采用MongoDB,并使用分片集特性来存储大数据。HBase也可以,但入门学习成本可能稍微有一些高。
下一篇文章,咱们来聊聊大数据的分析过程和方法。














 2166
2166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









