







论文:《基于多重继承与信息内容的知网词语相似度计算》-2017-张波,陈宏朝等 查看
代码:https://github.com/yaleimeng/Final_word_Similarity
总体感受:
太乱了,有可能是之前没怎么接触这块。
看论文,搞不懂怎么回事,义项、义原是啥,怎么这么多定义,到头来还是不懂两个词的相似度怎么计算,比哈工大词林那篇论文复杂多了。
看代码,函数调来调去,一会这个判断一会那个判断,不明白为啥要这么干,光读词表就看着很费劲。
(程序可能还有bug,调试时有时不能正确运行)
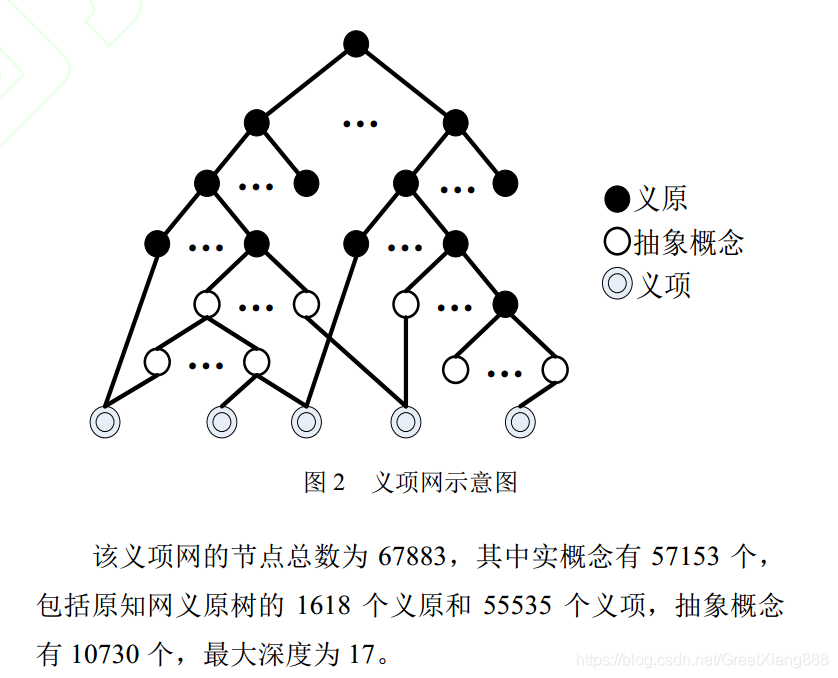
概念
义原:义原是描述义项的最基本单位,分为事件、实体、属性、属性值、数量、数量值、次要特征、语法、动态角色和动态属性等 10 大类,2000 版的知网共有 1618 个义原。 通过上下位关系,所有的知网义原组成一个树状义原层次体系,如图 1 所示。
义项:知网中所有的义项(又称“概念”)并不是组织为树状概念结构,而是采用“义原”对义项进行描述定义。

如图 2 所示,由于一个词语可能有多个义项,每一个义项可能有多个上位节点
(抽象概念或实概念),所以体现了义项网的多重继承特征, 但这种多重继承仅表现在叶子节点(义项) 上。
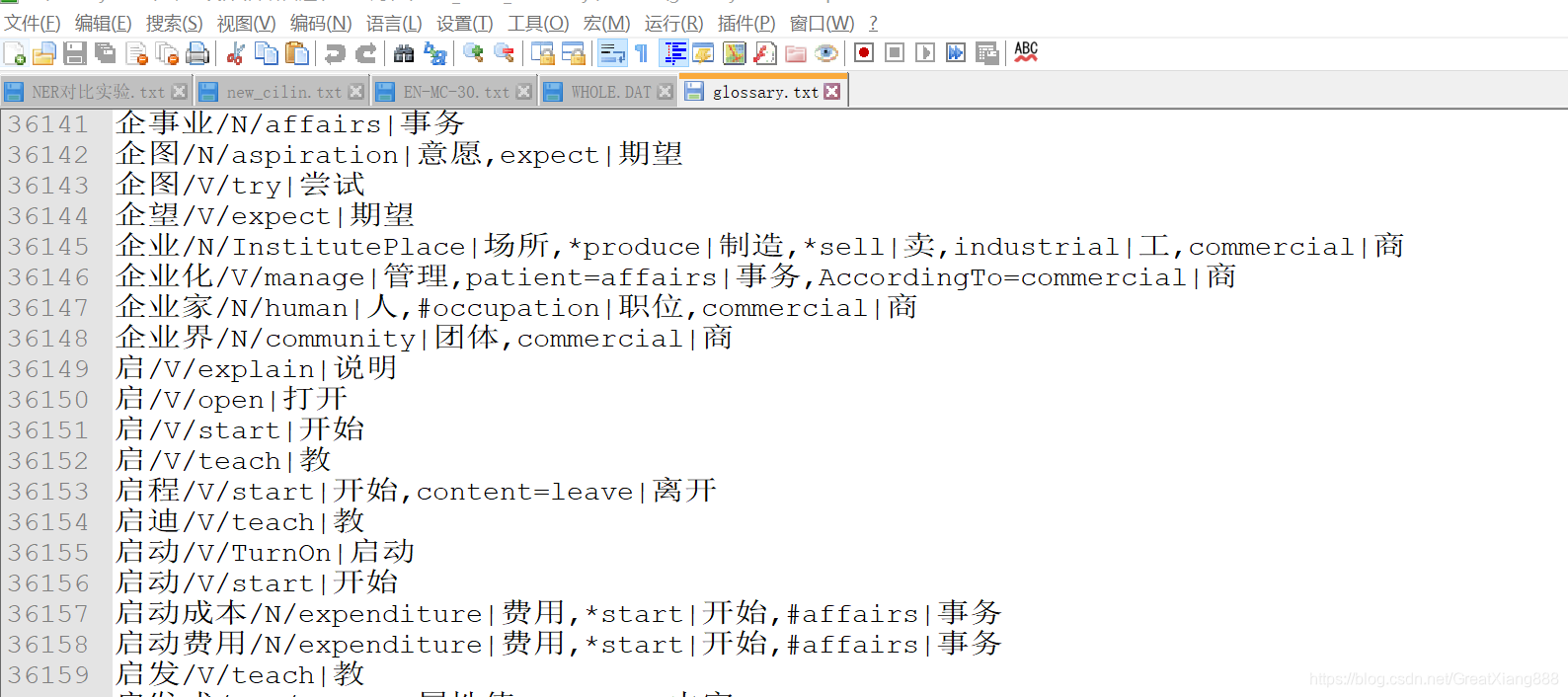
义项存储在glossary.txt文件中,如:
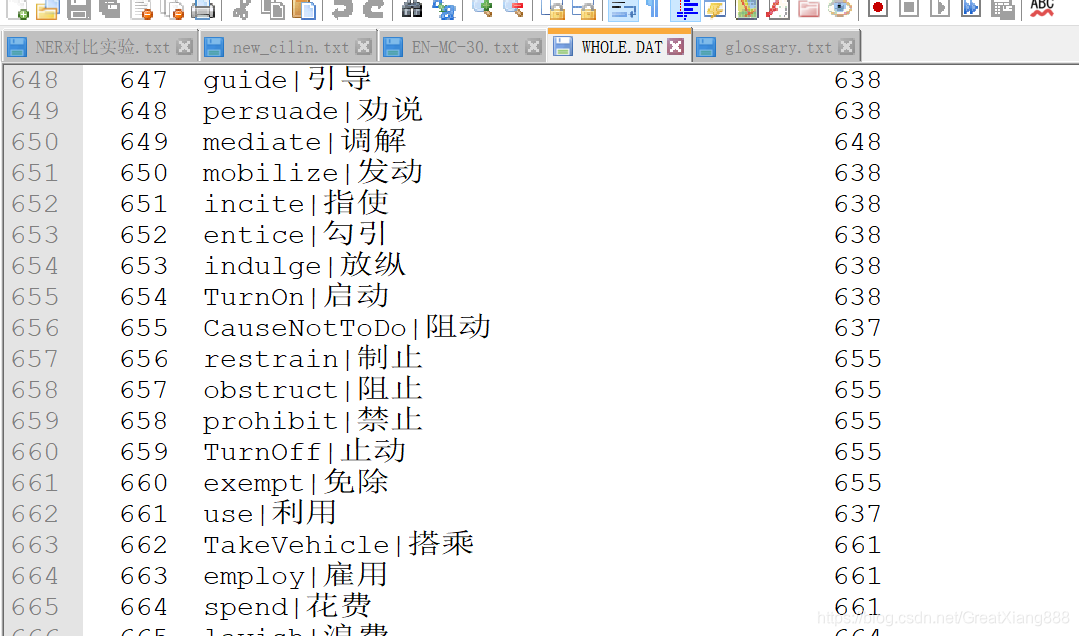
义原存储在WHOLE.DAT中,如:
example.py
在for w1, w2 in zip(MC30_A, MC30_B):下面加上一些调试信息:
for w1, w2 in zip(MC30_A, MC30_B):
#debug
if w1!='起重机':
continue
hybrid = HybridSim.get_Final_sim(w1, w2)
print('使用混合方法计算,相似度为:', hybrid)
这样可以比较“起重机”和“器械”之间的相似度,进入get_Final_sim()函数,设置断点。
HybridSim.py
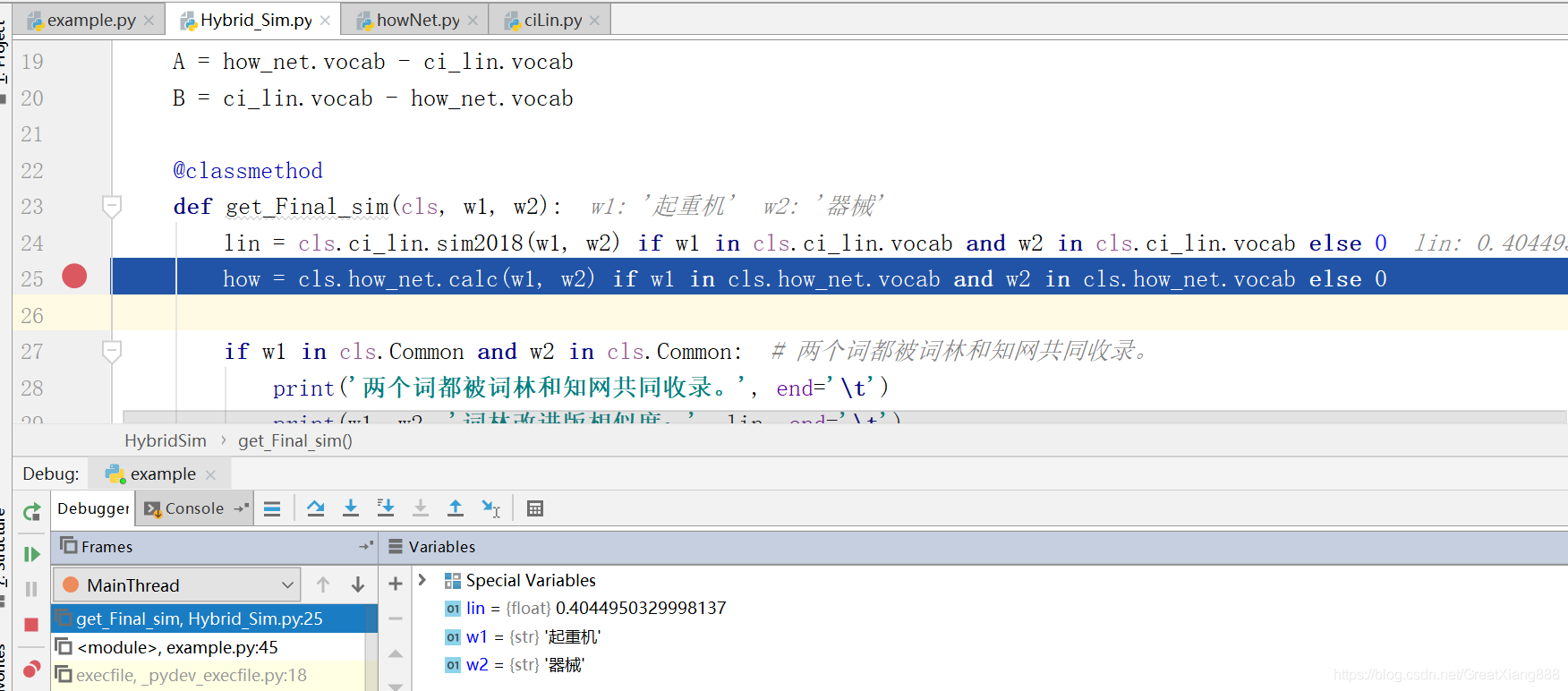
进入cls.how_net.calc(w1, w2)函数。
howNet.py
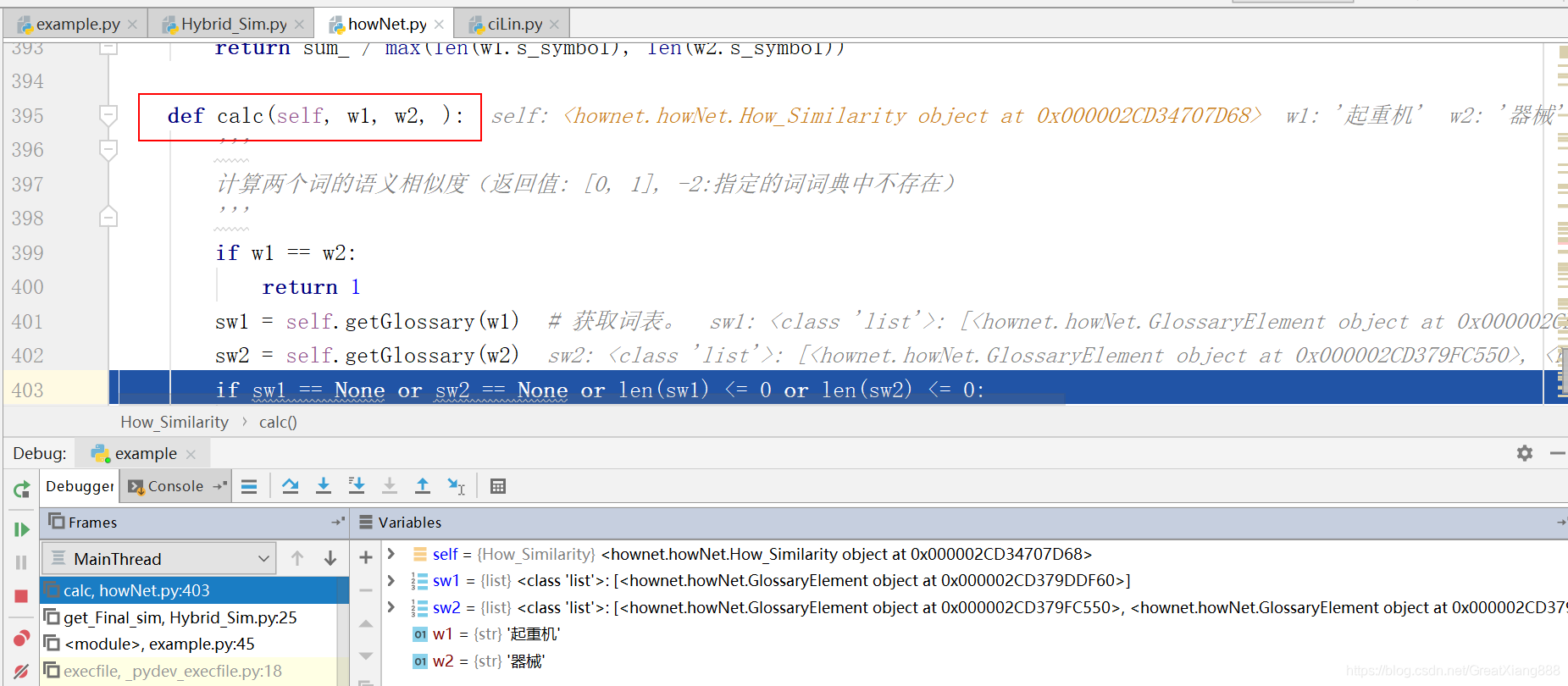
查看sw1和sw2:
通过单词找出更多相关信息
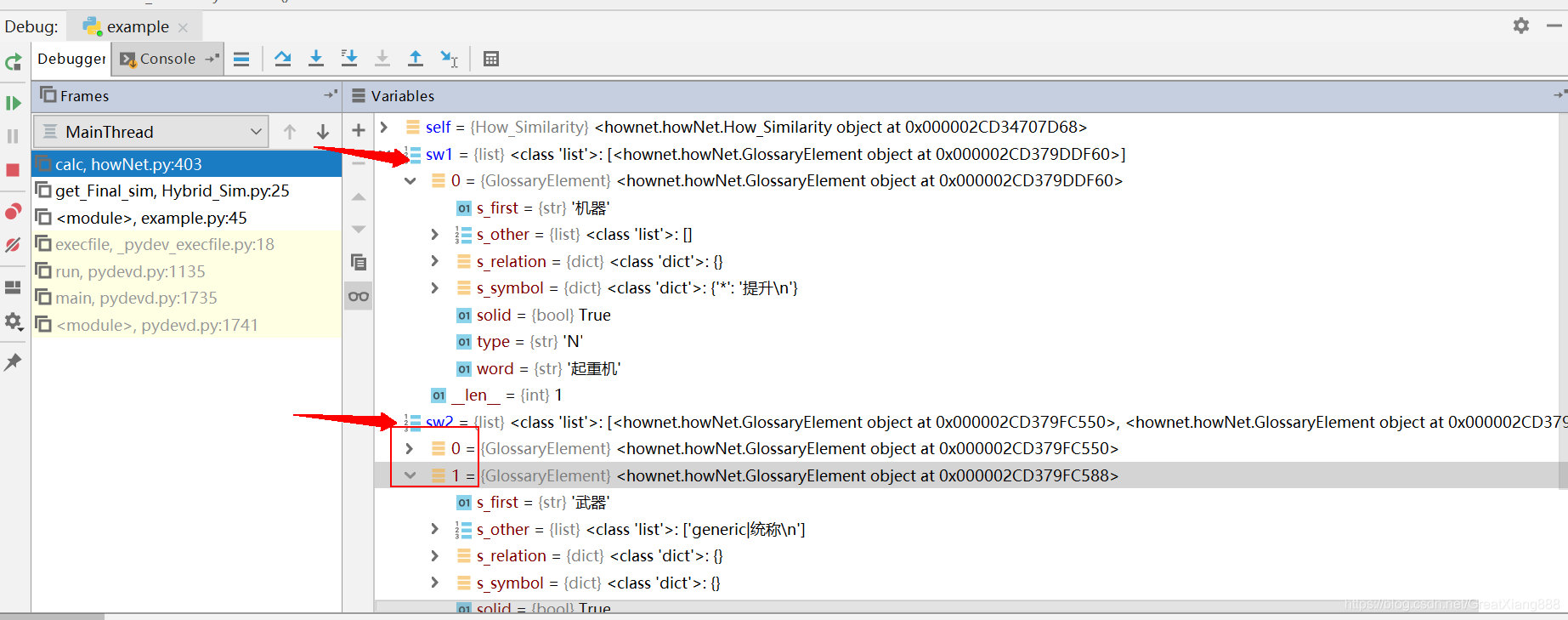
sw1只有一个值
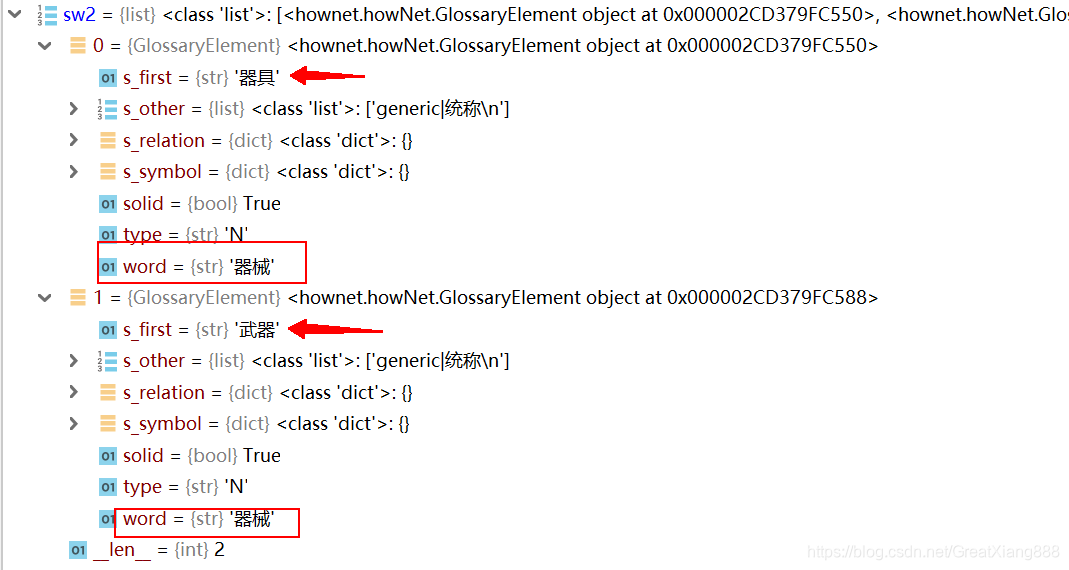
sw2有两个值。
sw2,对应词表文件glossary.txt为:

变量结果为:
在sw1和sw2中计算所有组合的相似度,取最大值:
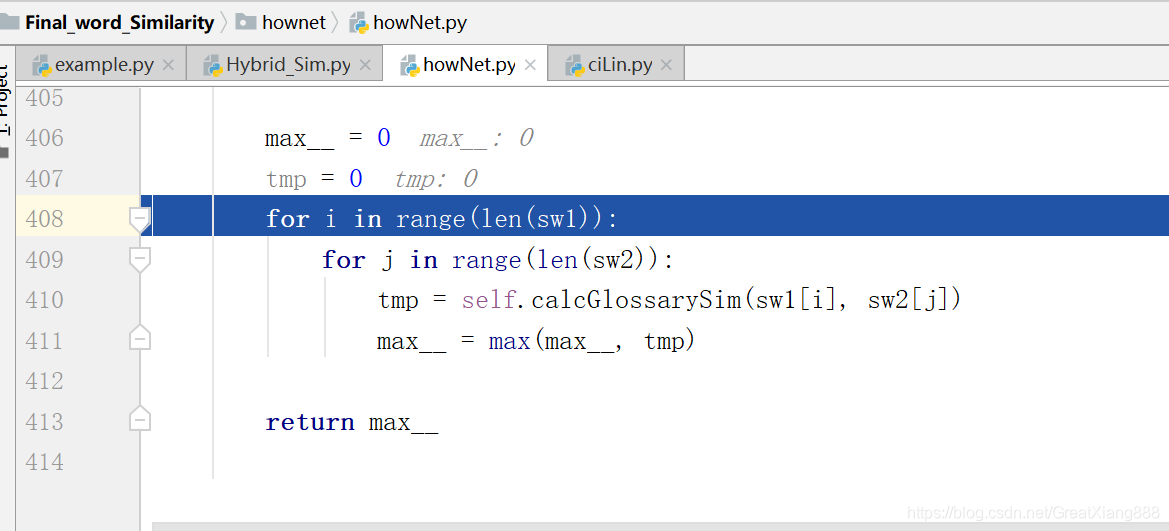
对应论文:

进入calcGlossarySim()函数:
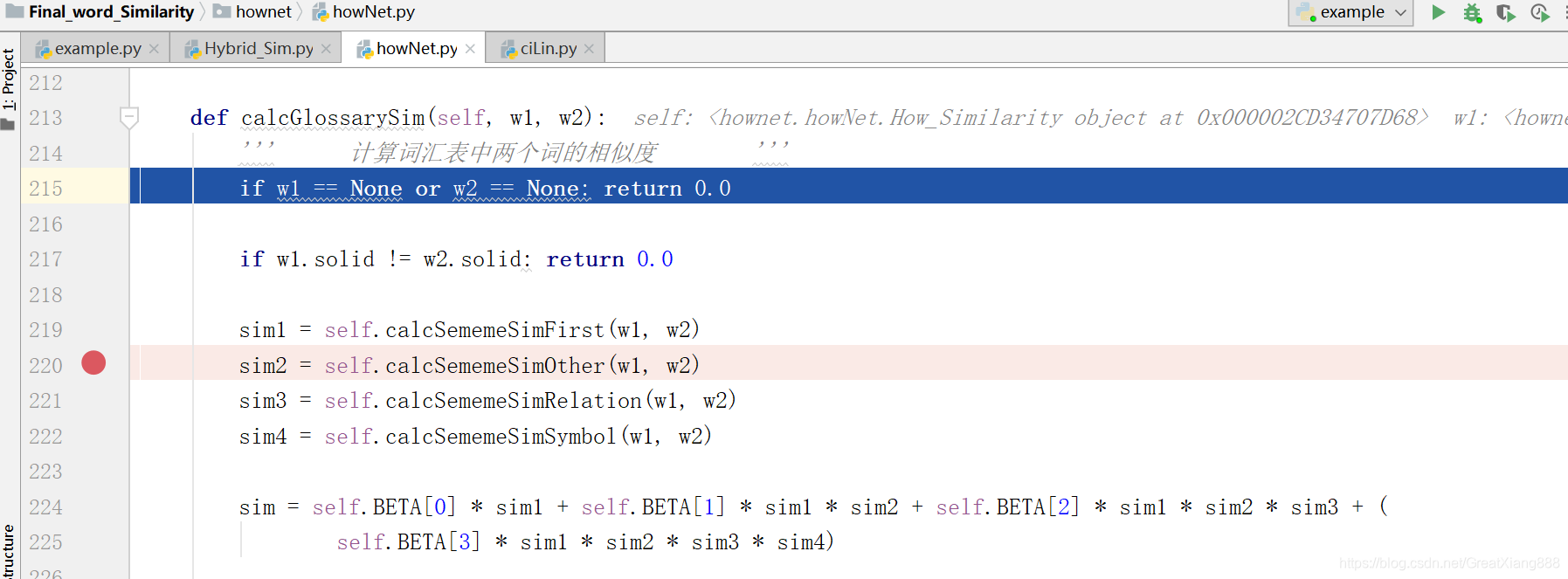
对应论文:

进入calcSememeSimFirst(w1, w2)函数,实际上是calcSememeSim(self, w1, w2, ):
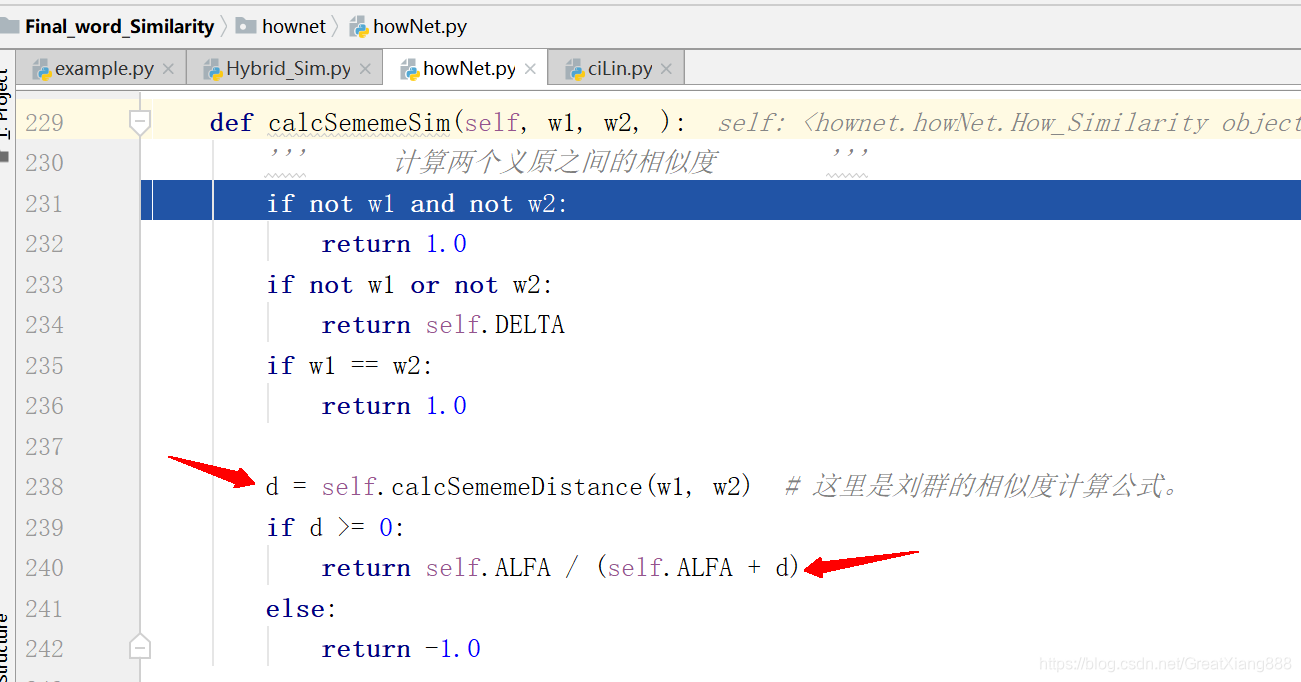
对应论文:

进入calcSememeDistance(self, w1, w2):#计算义原之间的距离(义原树中两个节点之间的距离,具体算法要看刘群的论文)
getSememeByZh(w1),根据中文词汇找到义原信息。
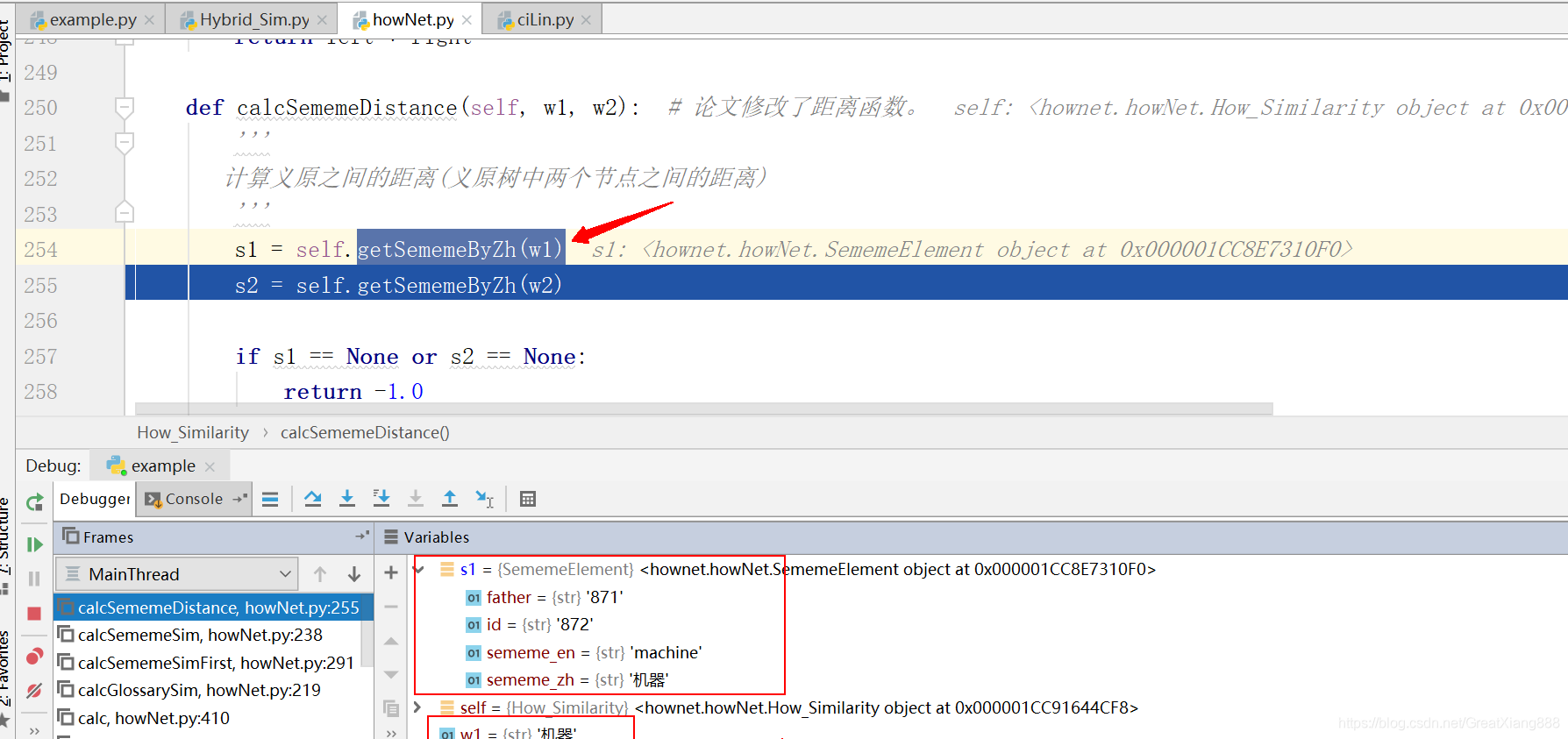
根据该节点,找到父亲节点(从WHOLE.DAT文件算出来的),一直找上去:
//这样两个子节点就可以找到公共父亲节点,如果节点离根节点越远,说明两个词越相似。
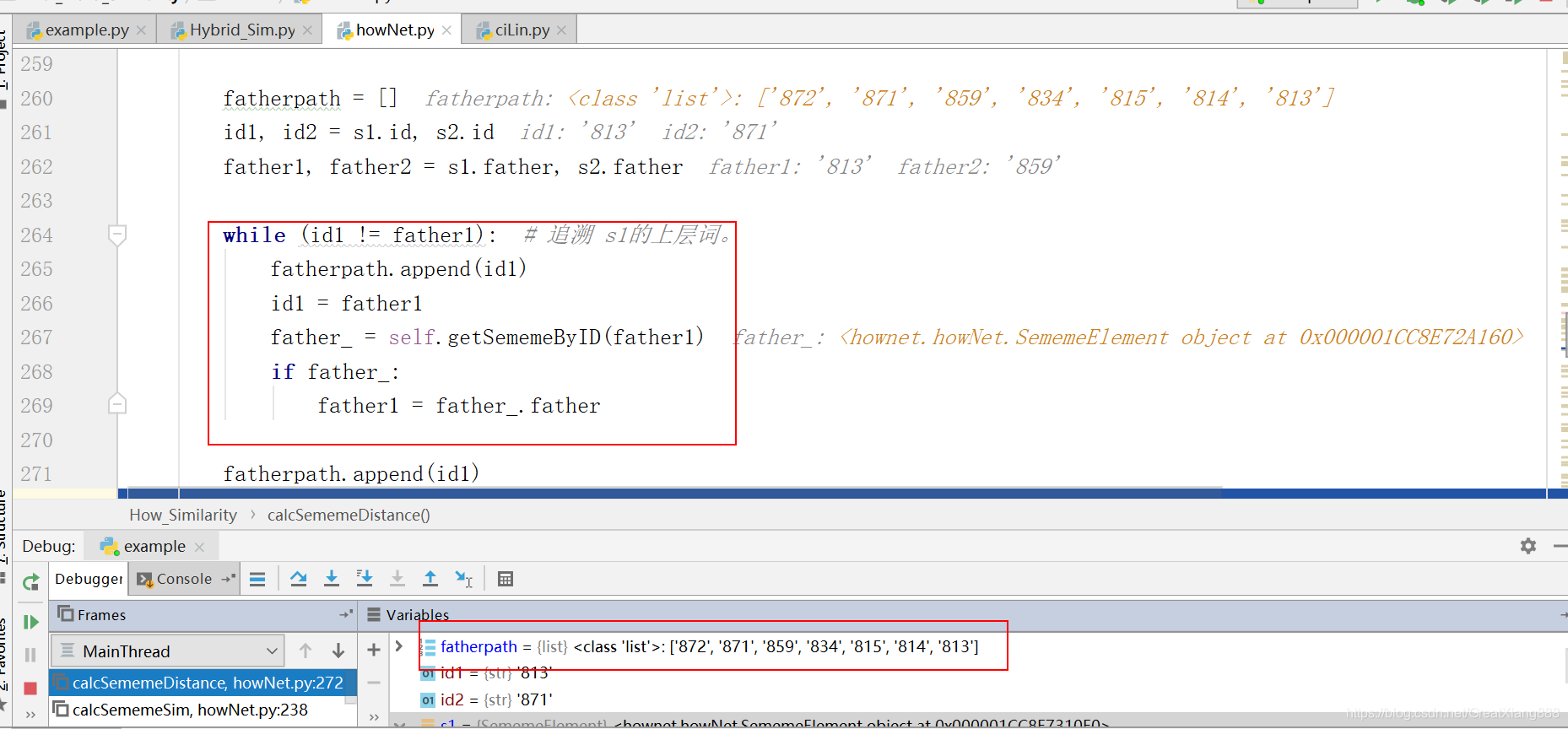
WHOLE.DAT文件相关内容:
872 machine|机器 871
871 implement|器具 859
859 artifact|人工物 834
834 inanimate|无生物 815
815 physical|物质 814
814 thing|万物 813
813 entity|实体 813
最后一步步返回,计算出cls.how_net.calc(w1, w2),两个词的相似度。
完成。














 2531
2531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









