






KMP算法
KMP的用途
KMP主要应用在字符串匹配中。
我们在进行字符串匹配时,通常采用的暴力求解方法是,从头开始比较两个字符串,如果遇到不一样的地方,则将模式字符串移动一位,然后继续与主字符串进行匹配判断。这样会使时间复杂度提高不少。
因此,KMP算法就被发明了,这个算法的主旨是当字符串不匹配时,利用之前已经匹配过的字符串内容,避免从头开始匹配。
这里极力推荐卡尔老师的KMP算法视频,讲的非常清楚。
KMP的使用-前缀表
如何利用之前已经匹配过的字符串呢?
这就要使用到KMP中的前缀表了,前缀表在KMP中一般用next数组来表示,他的作用是记录下字符串中的每个字符对应的最长相等前后缀,是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。
如下图所示。

!注意!: 前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串
后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串
比如说,这里模式串的第一个字符a,他所在的位置的前缀为a后缀为空,因此前缀表为0;第二个a,他所在位置的前缀为a后缀也为a,相等,因此前缀表为1;下标为2时,对应的字符为b,因此前缀为aa后缀为ab,不相等,对应的前缀表为0;下标为3时,对应的字符为a,此时最大相等前缀为a后缀为a,因此为1;下标为4时,最大相等的前后缀为aa,因此对应的前缀表为2;当下标为5时,前后缀没有相等的,因此为0。
对应过来的前缀表就为[0,1,0,1,2,0]。其实比较下来看看,实际上比的是前后缀的末尾,这个就有点DP的味道了,末尾相同,前缀表加1,然后再比较后面的末尾。这样说有点抽象,下面具体介绍一下怎么实现的。
那么怎么在代码中实现前缀表呢?
主要有三步:
1.初始化
2.处理前后缀不相同的情况
3.处理前后缀相同的情况
首先第一步:因为要比较前后缀是否相同,因此需要两个指针i和j,i指向前缀的末尾位置,j指向后缀的末尾位置。下面画图来演示一下。

对于一个字符串aabaaf来说,初始化的时候先确定字符串前缀的末尾位置,对于起始处,前缀就为第一个字符,因此,此时前缀表为0,j指向第一个字符。而i指针则是需要从下一个位置开始遍历的,并不需要初始化。如下:
j = 0
next[0] = 0第二步前后缀相同的情况如何处理?如下:
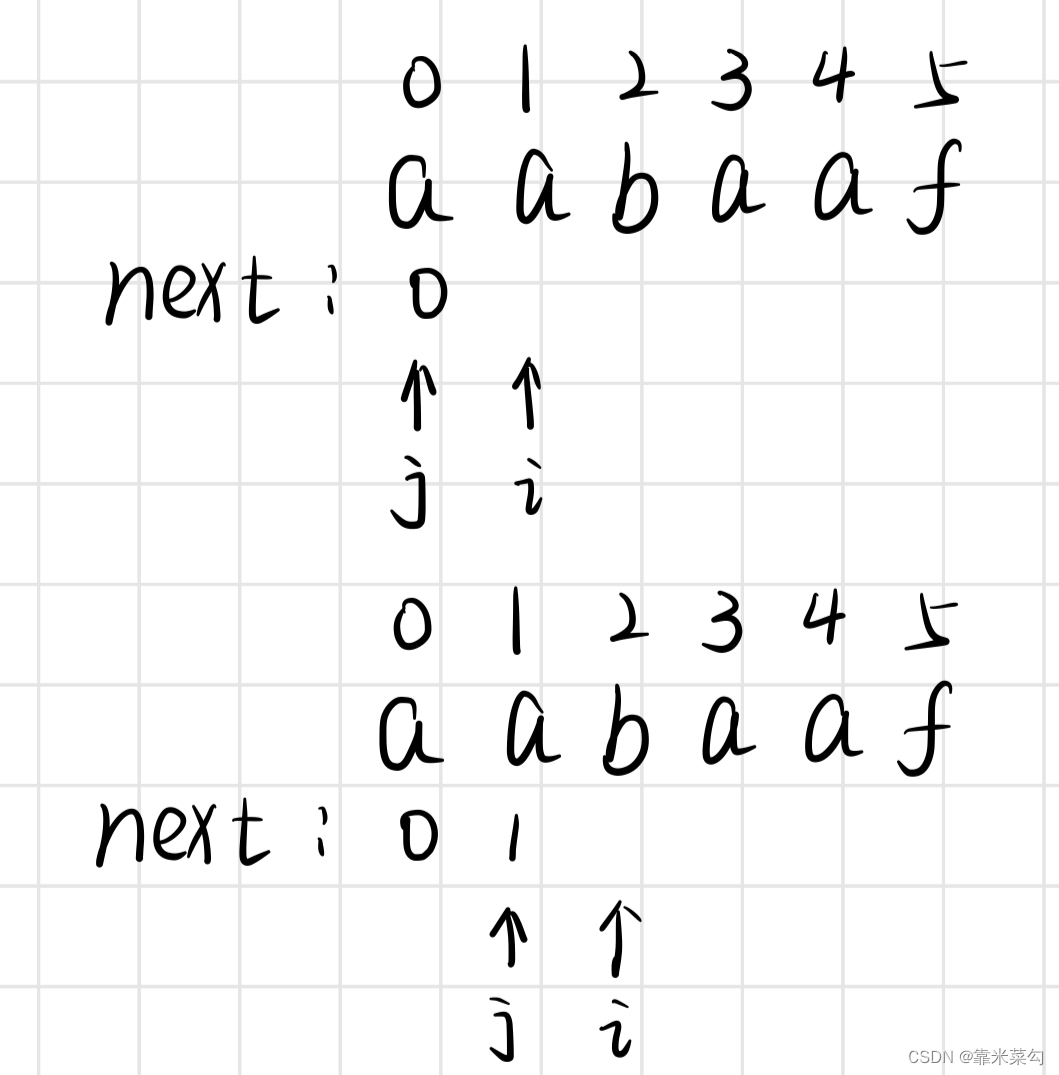
前后缀相同就说明需要更新next数组了,如上图所示,现在i等于1的时候恰好等于j等于0时候的字符,说明现在的最大相等前后缀为1,因此next[1]更新为1,j向后移动变为1,同时i也随着循环向后移动1位。
for i in range(1,len(s)):
if s[i] == s[j]:
j += 1
next[j] = j
第三步前后缀不同的情况怎么处理?由上面可以知道,在前后缀不相同的情况下需要回退到前缀表中对应的位置,遇见冲突看前一位。
while j > 0 and s[i] != s[j]:
j = next[j-1]因此,getNext函数可以写为如下:
def getNext(self, next: List[int], s: str) -> None:
j = 0
next[0] = 0
for i in range(1, len(s)):
while j > 0 and s[i] != s[j]:
j = next[j - 1]
if s[i] == s[j]:
j += 1
next[i] = j那么最后一步,如何利用前缀表进行字符串的匹配?
下面画图来演示一遍。

下面直接利用一道题来练习一下KMP算法。
28. 找出字符串中第一个匹配项的下标
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
解题思路
class Solution:
def strStr(self, haystack: str, needle: str) -> int:
def getNext(next,s):
j = 0
next[0] = 0
for i in range(1,len(s)):
print(s[j])
while j > 0 and s[j] != s[i]:
j = next[j-1]
if s[j] == s[i]:
j += 1
next[i] = j
return next
if len(needle) == 0:
return 0
next_ = [0] * len(needle)
next_ = getNext(next_,needle)
j = 0
for i in range(len(haystack)):
while j > 0 and haystack[i] != needle[j]:
j = next_[j-1]
if haystack[i] == needle[j]:
j += 1
if j == len(needle):
return i - len(needle) + 1
return -1在获得前缀表后,进行字符串匹配时还是一样的流程,只是不需要再更新前缀表了,当字符不一样时,回退到匹配好的位置,当字符一样时一起往前遍历,知道指向模式字符串的末尾。还得多练练啊,改bug改了好久。
459. 重复的子字符串
给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。
解题思路
由于这道题本质上还是找到匹配字符串,所以这道题继续使用KMP算法,先求一下next数组就可以发现当字符串为abcabcabc的时候,其前缀表数组为000123456,最小重复单元为000即abc。当字符串为aba时,其前缀表数组为001,此时他不能由最小重复单元重复多次构成。
比较一下不难得知,最小重复单元就是前缀表最前面的0所代表的字符,后面不为0的值则对应可能重复的单元,如果是能够重复多次构成的字符串,那么其前缀表的最后一位再加上最小重复单元的长度就是字符串的长度了,可以以此为判别准则,因此,代码如下:
class Solution:
def repeatedSubstringPattern(self, s: str) -> bool:
def getNext(next,s):
j = 0
next[0] = 0
for i in range(1,len(s)):
while j > 0 and s[j] != s[i]:
j = next[j-1]
if s[j] == s[i]:
j += 1
next[i] = j
return next
if len(s) == 1:
return False
next_ = [0]*len(s)
next_ = getNext(next_,s)
num_of_0 = next_.count(0)
print(next_)
if len(s) % (len(s)-next_[-1]) == 0 and next_[-1] != 0:
return True
else :
return False














 916
916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









