







 本文介绍了搜索引擎的架构,重点讲解了索引处理系统,包括文本采集、文本转换和创建索引的过程。爬虫从互联网抓取信息,信息源如RSS提供实时数据,转换组件涉及分词、停用词处理、词干提取等,最后创建索引时计算词项权重,进行倒排和分布索引,以提升搜索效率和效果。
本文介绍了搜索引擎的架构,重点讲解了索引处理系统,包括文本采集、文本转换和创建索引的过程。爬虫从互联网抓取信息,信息源如RSS提供实时数据,转换组件涉及分词、停用词处理、词干提取等,最后创建索引时计算词项权重,进行倒排和分布索引,以提升搜索效率和效果。
架构
对软件系统来讲,从一个层面对系统的各个组件进行抽象.描述它们各自的功能、提供的接口以及它们之间的关系.
需求
架构为应付需求而产生,对搜索引擎来讲,它主要的需求来自两个方面:
效果(effectiveness):搜索的结果质量如何.
效率(effeciency):返回结果的相应时间是不是够低,搜索服务的吞吐量是不是够高.
索引处理系统(Indexing Process)
从这样的需求出发,我们就不能顺着文档的每一个字或词来比较用户输入的查询关键字.
所以我们需要一种能提供高效的数据结构、算法和检索策略的东西,这就是索引处理系统.
这个系统大概像下面这样:
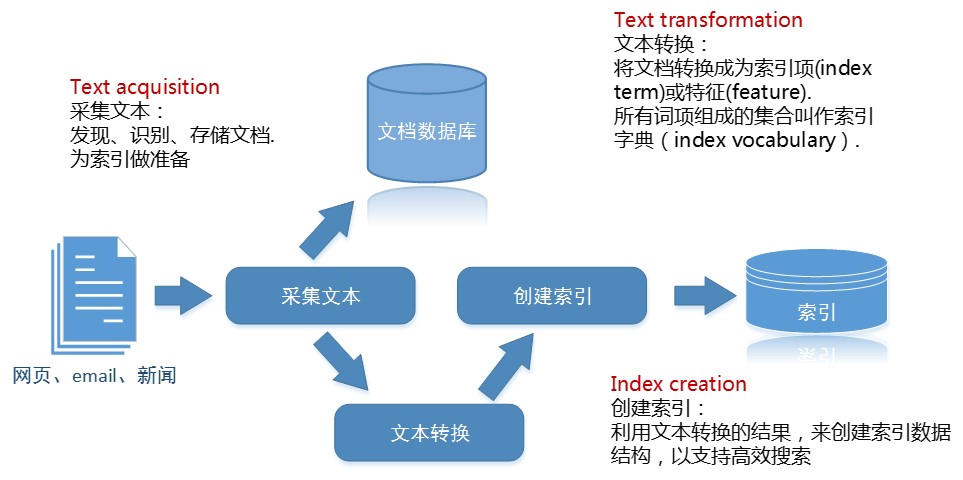
这幅图能告诉我们什么?
采集文本组件(Text acquisition)
这个组件用于发现、识别、和存储文档.为索引做准备.通常它必须具备以下几个功能:
1.爬虫 (Crawler)
一般搜索引擎中就是网络爬虫(web cralwer)了.
它负责通过超链接来源源不断地从互联网、文件服务器等信息源中爬取网页、新闻、email、话题等文档.并将这些信息加工后丢进文档数据库中.如上图所示.
爬虫要解决一个更新的问题,因为一个搜索引擎必须拥有对更新或时新的内容进行处理的能力.
2.信息源 (Feeds)
对于实时文档流,检测信息如果就能获得更新的消息那再好不过了.RSS就是一种信息源.它用XML来描述.
3.转换 (Conversion)
这里的转换的功能一些也可以丢给文本转换组件.
来自爬虫抓取或者信息源的文档集合,格式很多,比如html、xml、PDF、doc、ppt等,而我们更喜欢纯文本的格式以高效和有效处理.
4.文档数据库 (Document Data Store)
必须有一个能存储文档及其元数据的地方,否则索引再快,也没东西返回,虽然互联网上的文档可以时时抓取,但离线分析显然更快,这就需要一个文档数据库.
选择关系型数据库(RDBMS)还是NoSQL数据库,根据实际情况来.
文本转换组件(Text Transformation)
这个组件负责将文档转换成为索引项(index term)或特征(feature).
所有词项组成的集合叫作*索引字表(index vocabulary)*.
1.解析器 (parser)
这个组件负责分词或叫词素切分(tokenizing)和识别词素(tokens).
词素识别可以将文档中的结构化部分切分出来,比如链接、主题、图标等。
不仅是对文档,对查询也要做分词,这样查询和文档才能比较。
2.停用词处理 (stopping)
一些停用词,比如英文中的to、of、the,中文中的的、吗等,对文档内容贡献不大,但却大量出现。
去除停用词可以在相当的幅度上增加检索效率,但也可能带来错误的搜索结果。
停用词库的大小要斟酌,小了意义不大,大了容易过滤掉很多东西,导致查询的本意被改变或者变得不可读。比如一骗文章叫“论的字在生活中的作用”,去除了“的”之后,就会很囧。
3.词干提取 (parser)
同义词或英文中的派生词处理.
4.链接分析(link analysis)
链接
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1508
1508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









