







H.264 概述
帧内预测宏块
在帧内预测模式下,预测宏块是基于之前的编码块和重建块(未被过滤)。在进行编码前,当前块中需要减去预测块P。
对于luma(亮度), P可能是4x4的子块 也可能是16x16的宏块。每个4x4的luma 块总共有9种预测模式;16x16的luma块有4种预测模式;4x4的chroma(色度)块只有一种预测模式。
4x4 luma 预测模式
预测块的参考来源于同一帧图像中已被编码和重建的上边块和左边块中的一些边缘采样点,如下图中的A-M,a~p则是预测块的16个点。
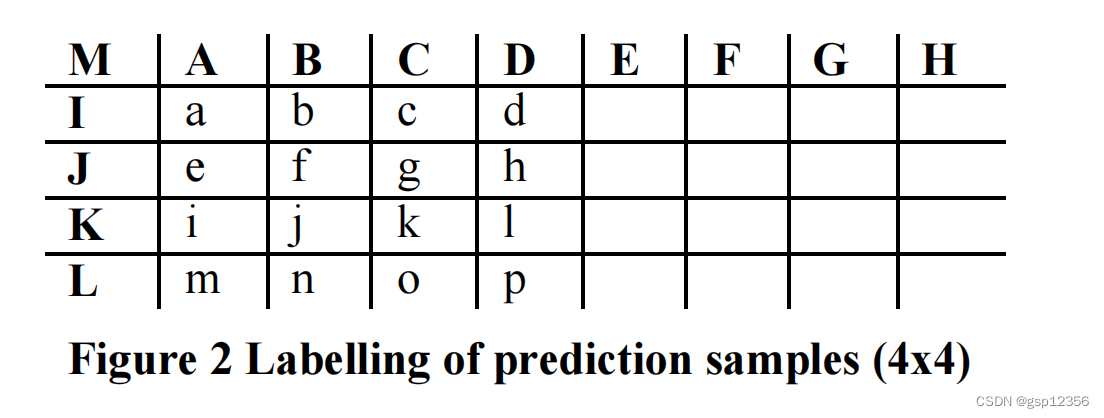
需要注意的是,在某些情况下,在当前的slice中并不会具备所有A~ M这些采样点:为了保证解码的独立性,只有在当前slice中的采样点才能被用于预测。DC预测模式 根据 可使用的采样点 而进行不同的修改(可使用采样点变化时,DC预测模式可对应变化),其他预测模式则只有上述A~M采样点均具备时才能使用(如果E,F,G,H不存在时,他们的值可用D值替代)。
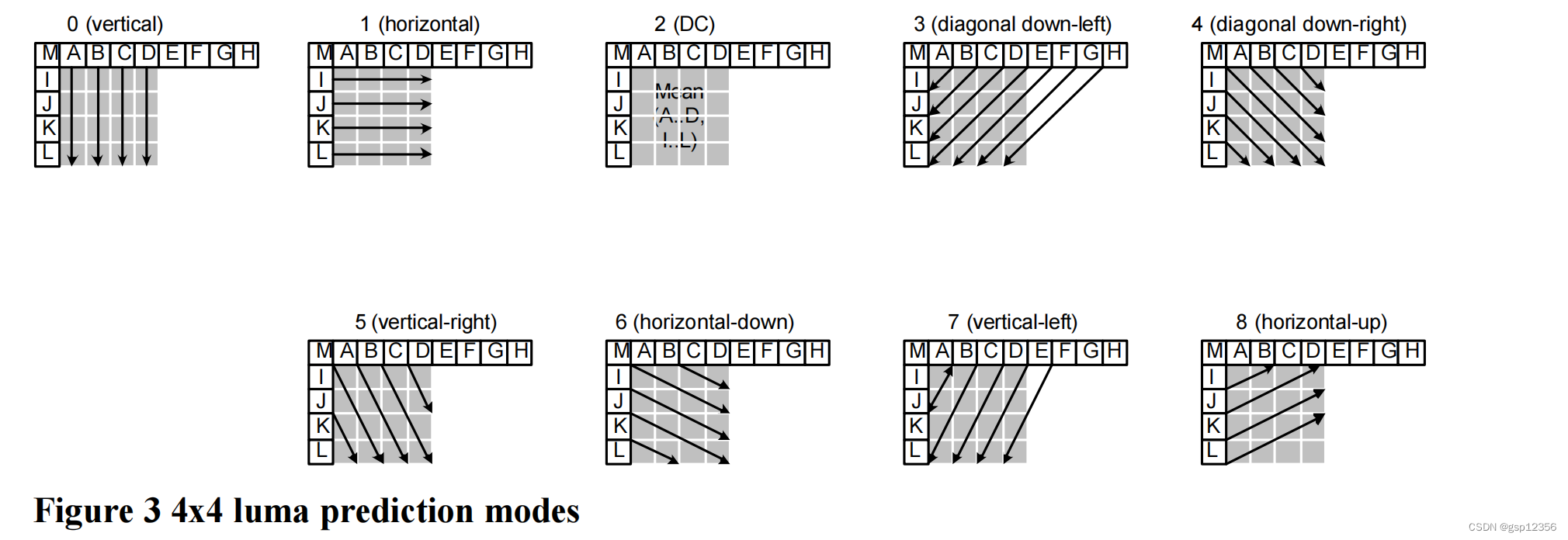
上图中的箭头代表每种预测模式的方向,模式3~8中,预测点由预测样本A-Q的加权平均值组成。编码器会在这些预测模式中选择 能使预测块P与编码块之间偏差最小的 一种。
ps:用每个预测的绝对误差之和(SAE)表示预测误差的大小。(SAE可能与SAD差不多)SAE越小,预测块与原始4x4 block(真实图像)之间的差异越小。
16x16 luma 预测模式
除了对4x4 luma block进行预测外,还可以直接对整个的16x16 luma 宏块进行预测。有如下4种预测模式
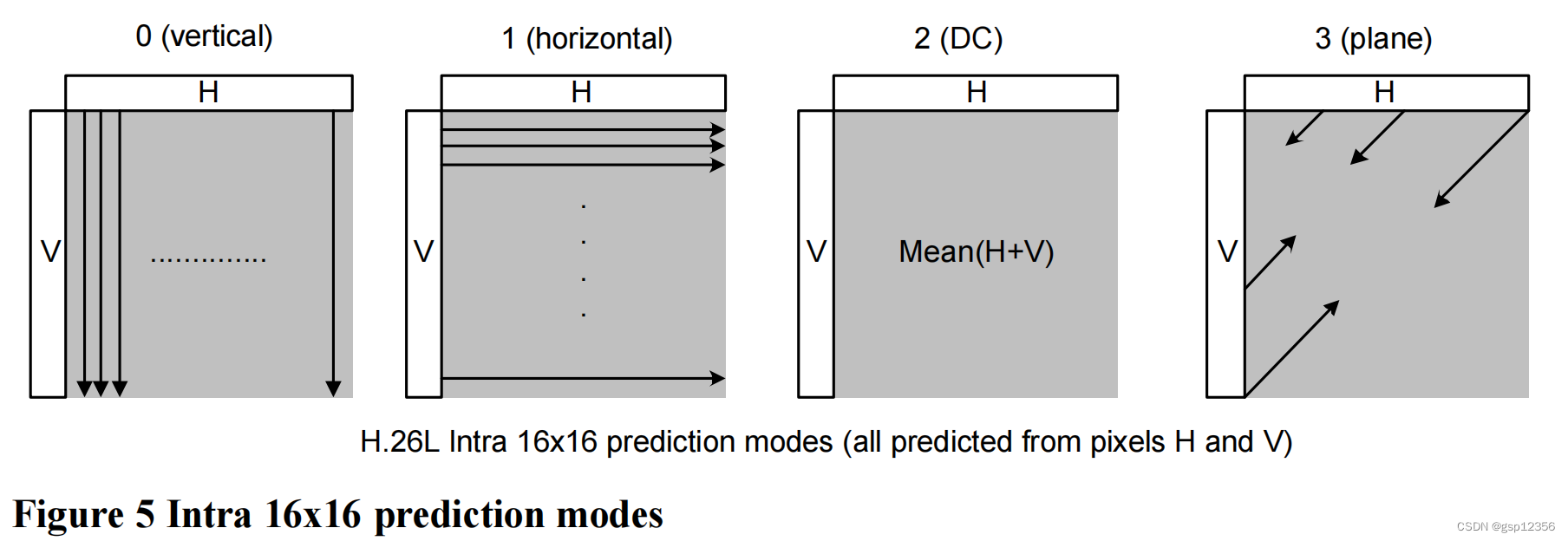
上图中的mode3 是对上边和左边的采样值进行一个线性“平面”函数的拟合,该模式在预测 亮度平滑变化的区域时 效果较好。
8x8 chroma 预测模式
一个宏块(16x16)的8x8 chroma 组块 也是根据chroma 已被编码和重建的上边沿和左边沿采样点 进行预测。预测模式与16x16 luma 类似(mode0:DC;mode1:水平; mode2:垂直;mode3:平面)。两个chroma block总是适用同一种预测模式。
另外:如果luma中有任何8x8的组块使用了帧内模式,那么两个chroma 块也将采用帧内模式。
帧内预测模式的编码
每个4x4块的帧内预测模式的选择都必须进行mark并给到解码器,这个过程可能需要大量的bits。然而,对于相邻的4x4 block而言,其帧内预测模式有高度的相关性。例如,如果下图中的A与B这两个4x4 block选择使用DC 模式进行预测,那么当前block- block C的最好的预测模式可能就是DC模式。
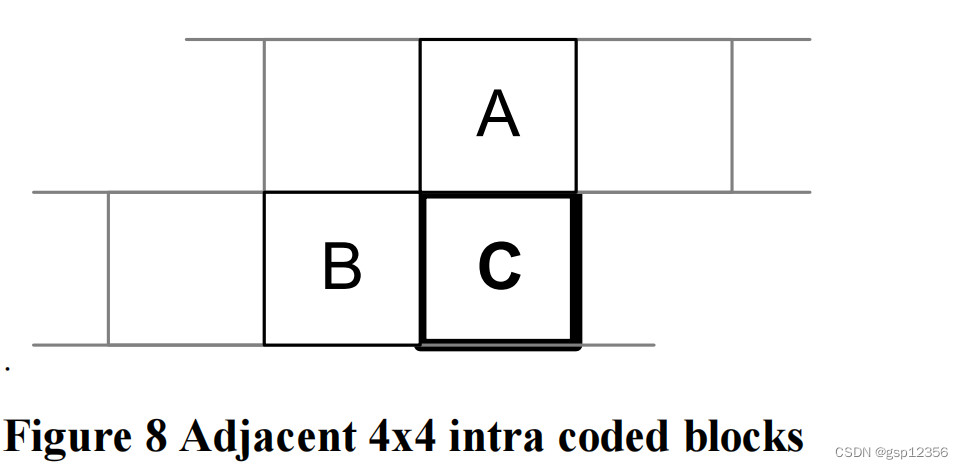
对于每一个当前块(c block),编码器和解码器将会计算出 most_probable_mode(最可能模式),如果A和B均在4x4帧内模式下编码 且均在当前slice, 最可能模式的值 就是 A和B预测模式值中的最小值(A的预测模式为5,B的预测模式为3 ,那么C的most_probable_mode就是3);当条件不满足时(A或者B不在当前slice或者其他),那么C的最可能模式将被设定为2(dc模式)。
编码器将给每一个4x4块发送一个flag(该flag为 use_most_probable_mode,即 使用最可能的模式),当这个flag为1,当前block将使用 最可能模式 进行预测;如果该flag为0,那么编码器将发送另一个参数remaining_mode_selector(保持模式选择器)来表明预测模式的变化。如果 “保持模式选择器”参数值小于“最可能模式”,那么当前block的预测模式将被设定为”保持模式选择“的参数值;否则当前block将使用 “保持模式选择”+1 所代表的预测模式。因而,“保持模式选择器”的取值范围为0~7 用来选择9种帧内预测模式(0到8)。
ps:各种预测模式的mode编号应该不是随意设定的,也不能自定义。
P-slices的帧间宏块预测
简介
帧间预测是一种基于不少于一帧已编码图像的预测模型。这种模型是通过 移动参考帧中的采样点 而形成的(运动补偿预测)。H264的codec过程不仅使用基于块的运动补偿,其与早期codec技术相比,能支持一系列 块大小(可小至4x4)和 精细的子像素运动向量(在luma中为1/4像素)
树状结构运动补偿
H264支持的运动补偿块大小范围为:16x16->4x4,16x16与4x4之间有多种选择。每个宏块(16x16)的亮度luma分量可以切分成4种,如下图2-1所示:16x16 16x8 8x16 8x8。每个细分区域都是一个宏块分区。如果选择了8x8的模式,那么对于这4个8x8的宏块分区 他们中的每一个分区都可能会以下图2-2的4种形式进一步分割:8x8 8x4 4x8 4x4(被称为宏块子分区)。这些分区和子分区会在每个宏块中有大量可能的组合形式。这种将宏块划分为不同大小的运动补偿子块的方法称为树形结构运动补偿。
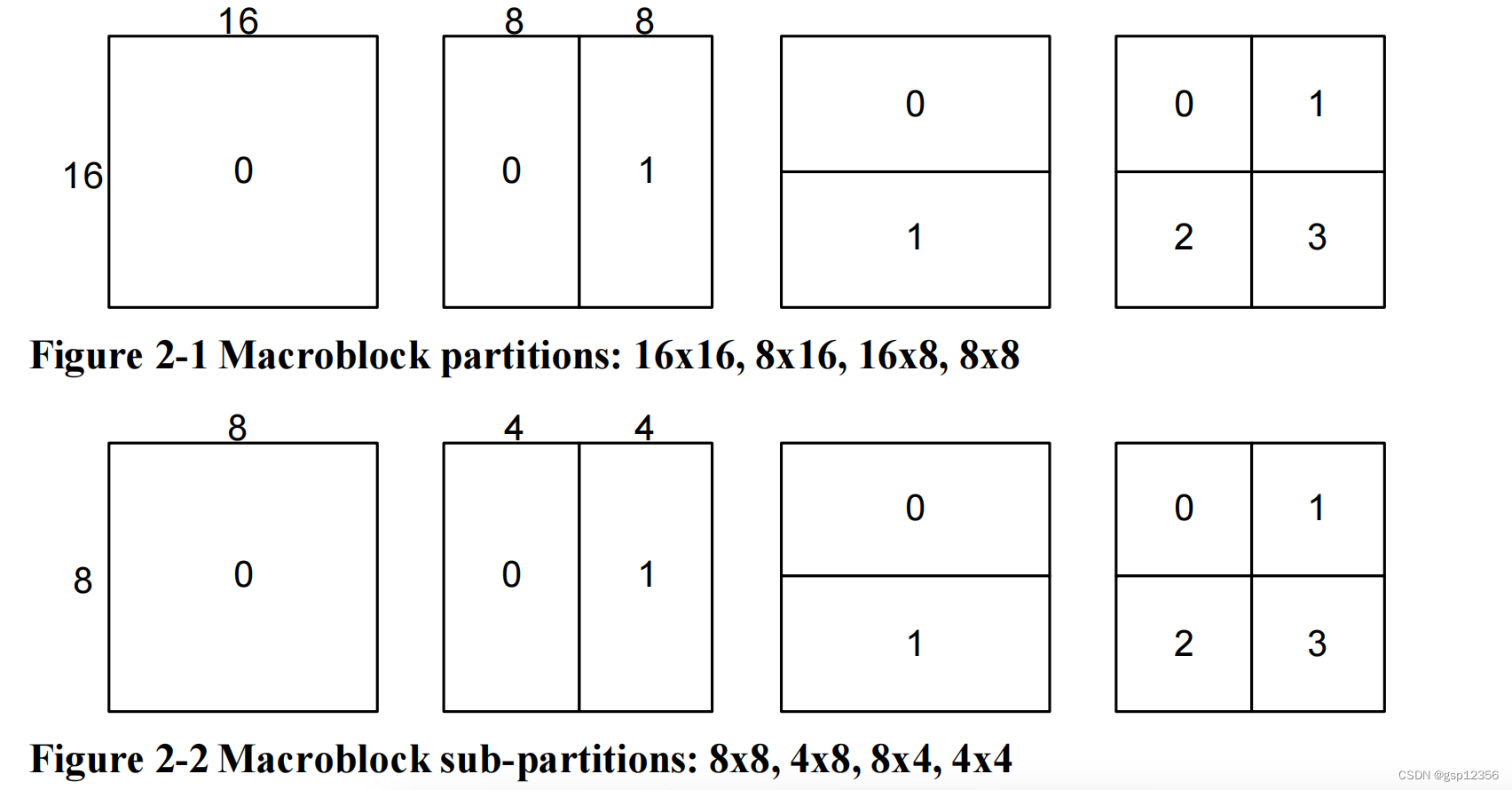
每个分区或子分区都需要一个单独的运动向量。每个运动矢量都必须进行编码和传输;此外,选择何种分区形式也必须编码在压缩码流中。选择一个较大尺寸的分区(如16x16 16x8 8x16)意味着只需要很少的bits就能将运动向量和区分类型的选择表示出来,但这种做法下将导致 运动补偿残余可能在高细节的帧区域中包含大量的能量。选择一个较小尺寸的分区大小(如8x4 4x4等)则在运动补偿之后有较少的能量残差 但需要大量的bits来表示运动向量和分区的选择。因而,分区尺寸的选择对压缩性能有明显的影响。一般来说,图像中的均匀区域适合选择较大的分区尺寸,而细节区域则适合较小的分区尺寸。
宏块中的色度分量(Cr与Cb)的分辨率是其亮度分量的一半。每个色度块的分区形式与亮度块类似,只是其分区大小刚好是行分辨率和列分辨率的一半(luma的8x16与chroma的4x8对应,luma的8x4对应chroma的4x2)。每个运动矢量(每个分区一个)的水平和垂直分量在应用于色度块时被减半。
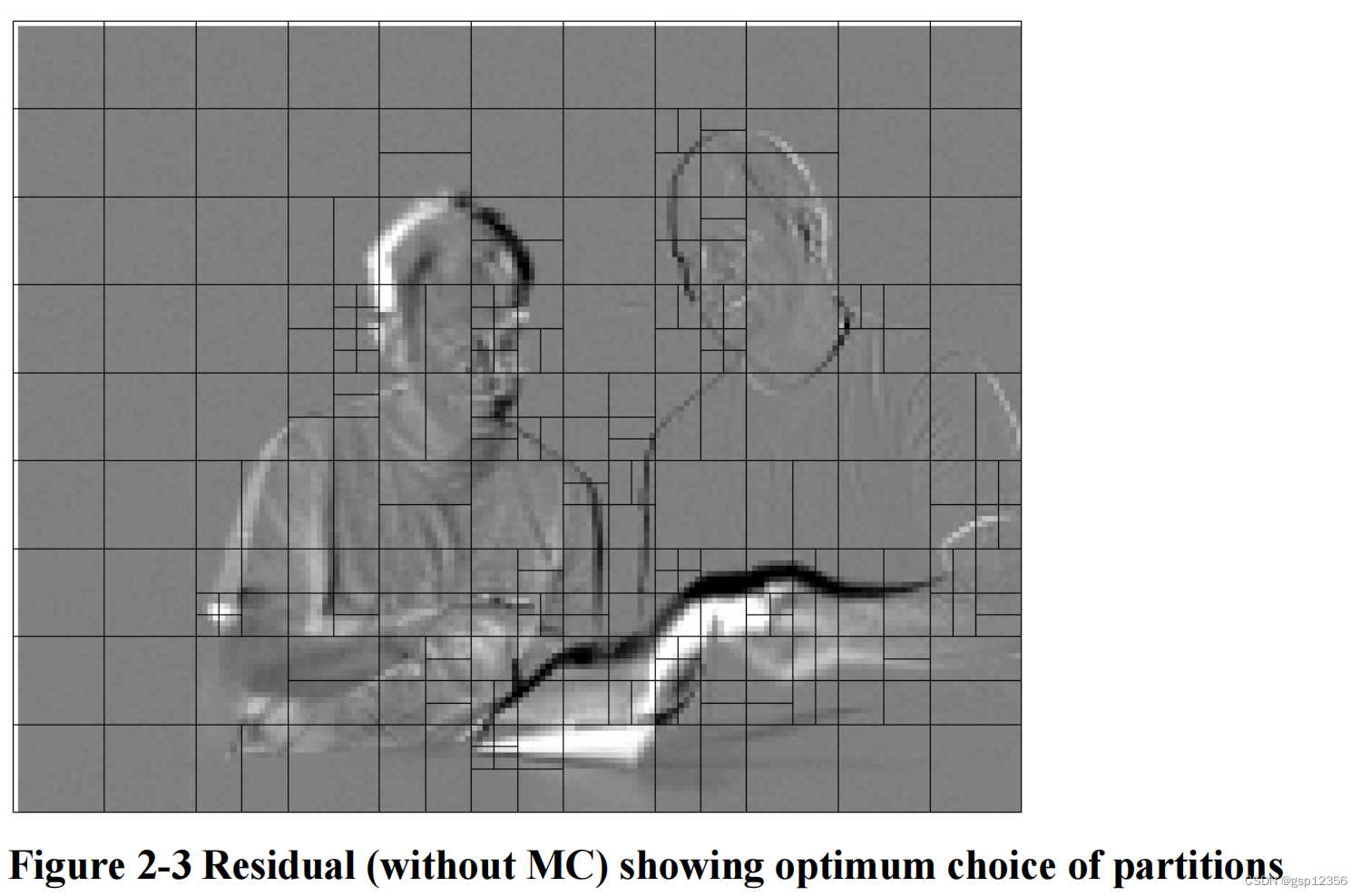
上面这副图是一副残差图(没有运动补偿,一帧减去另一帧得出的灰度图?),并且h264参考编码器为该帧的每个部分选择了“最佳”的分区大小,即:使编码的残差和运动向量最小化的分区大小。为每个区域选择的宏块分区显示为叠加在残差图上的框框。在帧与帧之间几乎没有变化的区域(残差显示为灰色),选择的是16x16分区;在细节运动的区域(残余显示为黑色或白色),较小的分区更有效。
亚像素运动向量
帧间编码宏块中的每一个分区均由参考图像中相同尺寸大小的区域进行预测。两个区域之间的偏移(运动向量/运动矢量)有 1/4个像素点的分辨率(对于luma分量而言)。luma与chroma在亚像素位置上的采样值并不由实际的参考图像提供,而需通过对亚像素点周边的像素点进行插值 得来。下图给出了一个示例。当前帧中的一个4x4子分区(a)将由参考帧中的相邻区域预测得出,如果运动矢量的水平和垂直分量都为整数(如b,向左和向上为正,因而(1,-1)代表参考块需要向左移动和向下移动才能得到预测块),那么参考帧中是有这些采样像素点值的(用白色像素点表示);如果运动矢量的分量都为小数(如c图),那么预测采样点(用灰色点表示)是由参考帧中的这些灰色点周围的几个白色像素点插值得到。
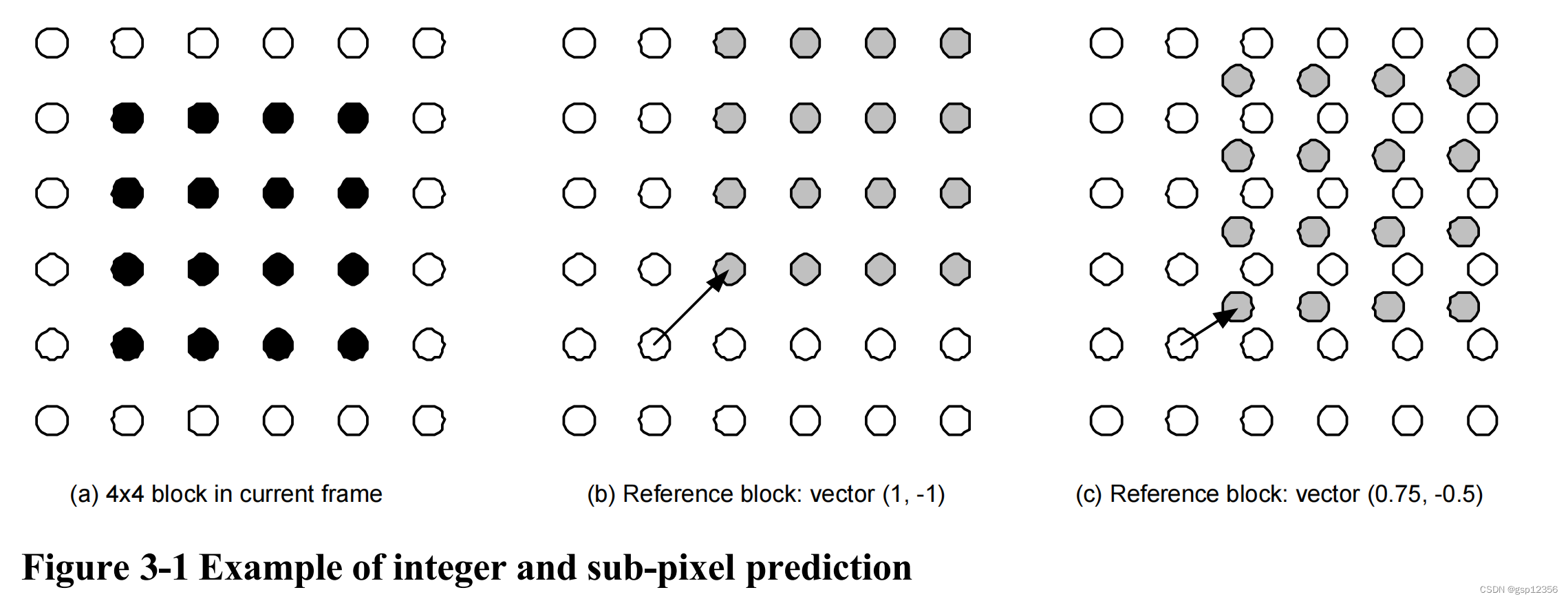
亚像素运动补偿可以提供比整数像素补偿更好的压缩性能,但以增加复杂性为代价。四分之一像素精度优于半像素精度。
对于luma分量,首先生成半像素位置的亚像素样本,这个过程需要使用6次有限脉冲响应滤波器(6步FIR滤波器)从相邻的整数像素样本进行插值,这意味着每一个半像素位置的样本是6个相邻整数像素样本的加权和。一旦所有的半像素样本都得出时,每个四分之一像素样本将通过对 相邻的半像素或整数像素样本之间 使用 双线性插值 产生。
如果视频源的采样为4:2:0,则在色度chroma分量中需要1/8像素的样本(对应于luma中1/4像素样本)。这些样本需要在整数像素的chroma色度样本之间进行插值(线性插值)得出。
运动矢量预测
为每个分区 编码 运动向量 需要很多bits来表示,特别是当选择 小尺寸的分区 时。相邻的分区 他们的运动向量通常是高度相似的,因此每个运动向量都是从 附近的先前编码的分区的向量 中预测出来的。将预测矢量用MVp表示,预测矢量是基于先前已计算出的运动矢量而形成的。MVD表示当前矢量与预测矢量的差异,也会被编码以及传输。形成预测MVp的方法取决于运动补偿分区的大小和附近矢量的可用性。“基本的”预测器是 当前宏块分区(或子分区)的正上方、斜上方和右侧 和直接左侧的分区(或子分区)的运动向量的中间值。如果选择16x8或者8x16分区(情况a)或者 如果附近的分区中有一些分区没办法拿到采样值(情况b),那么这两种情况下,预测器都需要进行修改。如果当前宏块被跳过(没有被传输),就好像MB(宏块)以16x16分区模式编码一样来生成一个预测矢量。
对于解码器,也是以相同的方式形成预测向量MVp,并将预测向量与解码向量差MVD进行相加。对于被跳过的宏块,则不存在被解码的向量,因而会根据MVp的大小而产生一个运动补偿宏块。
变换与量化
简介
每个残差块都需要进行转换、量化和编码。以往的标准如MPEG-1、MPEG-2、MPEG-4和H.263都采用了8x8离散余弦变换(DCT)作为基本变换。H.264的”基本档次“(分为基本档次,主档次,扩展档次)根据要编码的残差块类型选择三种转换:**内部宏块的4x4的luma DC系数(在16x16模式下预测的)需要一种转换;2x2的chroma DC系数(在任何宏块中)也需要一种转换;残差块中所有其他4x4块使用一种。**如果使用可选的“自适应块大小变换”模式,则会根据运动补偿块大小(4x8、8x4、8x8、16x8等)选择进一步的变换。
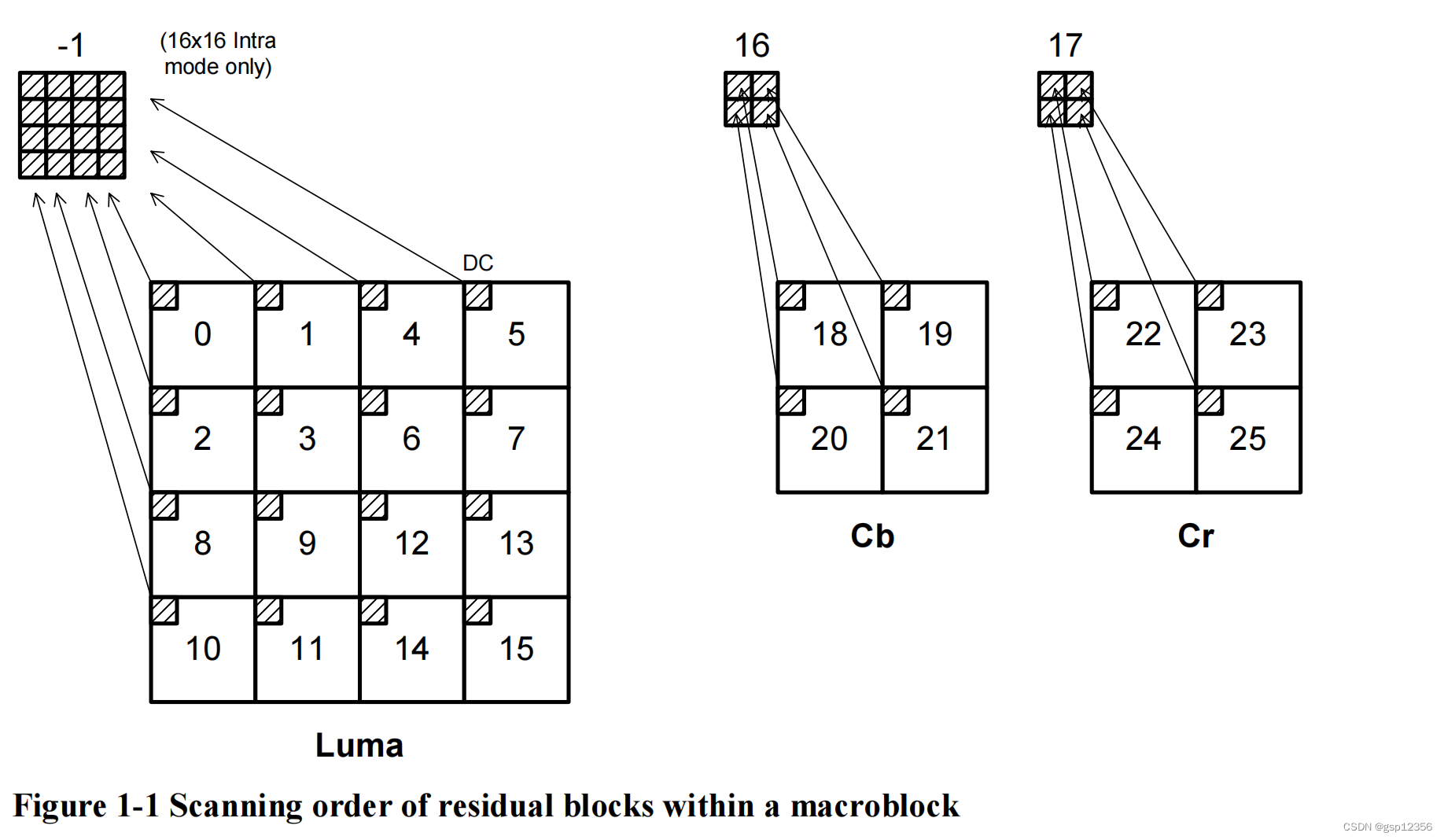
一个宏块中的数据传输顺序如上图所示。如果该宏块在16x16的内部模式中进行编码,那么上图中标为-1的块是最先被传输的,该块(-1)包含了每个4x4 luma 块(0~15)的DC系数;然后再传输被标记为0-15的luma 残差块(在帧内16x16的宏块中,里面的DC系数被设置成了0);被标记为16和17的块里面分别包含了Cb与Cr chroma分量的DC系数,这两个2x2的块是第三批被传输的;最后被传输的是chroma残差块,被标记成为18-25(这些4x4的残差块里面的DC系数均被设置成0)。
4x4 残差块的转换与量化(对应于上图中的0~15 18-25块)
这种转换发生在运动补偿预测或者帧内预测之后的 以4x4块形式存在的 残差数据上。这种转换基于DCT但有一些基本差异:
1、这是一种整数转换(所有操作都可以用整数运算,不会损失精度)
2、逆变换在H.264标准中完全指定,如果正确遵循该规范,编码器和解码器之间不会发生不匹配。
3、变换的核心部分没有乘法,即它只需要加法和移位。
4、缩放乘法(完整变换的一部分)被集成到量化器中(减少乘法的总数)。
整个变换和量化过程可以使用16位整数运算,每个系数只乘一次,不会造成任何精度损失。
4x4 DCT的扩展
下面这个公式就是H264/avc的4x4整数变换公式,X矩阵为残差矩阵(当前frame与预测块的差值)
这个变换公式中的后半部分,即点乘Ef(前面两两矩阵叉乘的结果是一个4x4的矩阵,在点乘Ef时相当于4x4矩阵中的每一个元素都直接乘以Ef中处于相同位置的系数)可能是在量化阶段进行的,具体参看链接: link
上面这个链接中还有变换过程的蝶型图
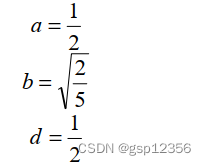

下面是反变换公式
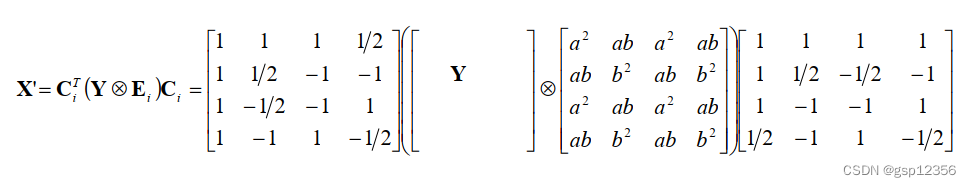















 921
921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









