









1. 定义
Kmeans算法的过程较为简单
1、从D中随机取k个元素,作为k个簇的各自的中心。
2、分别计算剩下的元素到k个簇中心的相异度,将这些元素分别划归到相异度最低的簇。
3、根据聚类结果,重新计算k个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数。
4、将D中全部元素按照新的中心重新聚类。
5、重复第4步,直到聚类结果不再变化。
6、将结果输出。
2.相异度
聚类算法中,我们将相似的元素聚成一类,让类与类之间的元素尽量不同,而聚成一类的元素尽量相似。这个度量相似的指标,就是相异度。虽然相异度可以理解为距离,但是相异度的计算方式有很多。注意相异度和相似度是一对相反的概念
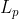 距离:
距离:
设n维特征空间中,
,
,
的
距离定义为(p>=1):
当p=1时,距离是曼哈顿距离(元素对应维度的绝对值之差求和)
当p=2时,距离是欧氏距离,也就是我们经常用到的距离公式
当p为无穷大的时候,距离是切比雪夫距离,定义为
向量
当特征是具有方向的向量的时候,比如词向量,词分布到向量空间中的时候,两个含义相反的词向量可能也是相反的,此时用Lp距离欧氏距离不合适,向量的相似度比较可以用余弦相似度来比较
one-hot特征
当特征空间是one-hot形式的时候,用上述距离也不合适,可以用元素相同序位不同值属性的比例来标识其相异度
例如:a={0,1,1,0} b={0,0,0,1},两个元素只在第一维上取值相同,相异度是3/4=0.75
有时候我们更关心那些取值为1的特征,比如用户购买预测的时候,两个用户没有买的商品会有很多相同的,但我们更关心用户买了相同的东西才是相似的,衡量方法为:取值不同的同位属性数/(单个元素的属性位数-同取0的位数),即分母此时不是全体特征数量,而是全体特征中去除掉那些和另一个比较的时候同时为0的个数。叫做非对称二元相异度,因为元素不同分母可能会变化。
上面是二元特征的情形,当一个特征是多元的,比如颜色的属性有很多,这种离散多元特征在机器学习中通常被处理成one-hot编码,所以度量方法和上面一样。
3. k值的选取——肘部法则
k值是一个超参数,选取方法有很多,除了根据先验知识确定以外,比较重要的方法有肘部法则:
- 计算指标:SSE(sum of the squared errors,误差平方和)
其中,Ci是第i个簇,m是簇的质心,即簇中元素的和的平均,p是Ci中的元素
我们从K=2的时候开始依次增大k值,此时k值比最优k值要小。随着聚类数k的增大,样本划分的趋势是更加精细,每个簇的聚合程度会快速提高,SSE的下降幅度很大。
当k到达真实聚类数时,再增加k的时候就像在已经聚好的簇内再画出簇来,必定SSE的下降幅度会骤减,最后趋于平缓。这个图的形状像一个手肘,而下降速度骤降的地方就是肘部,也就是最优k点

4. 问题
离群点检测
kmeans的一个应用是离群点检测,如果我们能确定能获得纯净数据(没有离群点),先训练模型,确定簇和簇心,再用数据去验证,如果该点距簇心的距离大于模型该簇心的最大距离,那么该点就是离群点。
归一化
如果有一维数据量纲太大,那么在算欧式距离的时候这一维就占了主导地位,归一化后量纲统一。但是归一化有可能会改变簇的分布
但是有的距离度量没有量纲影响,比如余弦相似度
分布式处理大数据
用MapReduce处理大数据,将数据分成n份分布处理,初始化簇心并广播到每一个mapper上计算数据属于哪一个簇心,再reduce计算簇心并更新
参考
https://www.cnblogs.com/data-miner/p/6288229.html
https://blog.csdn.net/u013713010/article/details/44905203















 1021
1021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









