







正文共:888 字 11 图,预估阅读时间:1 分钟
前面,我们已经测试过如何在HCL中导入自定义NFV镜像VSR1000(如何在最新版的HCL 5.10.0中导入NFV镜像?),上次我们又补测了转发性能(小测一下HCL中VSR的转发性能),虽然HCL号称V5.10.1版本优化了设备性能,但测试结果还是比较尴尬。当然,我自己的笔记本是低压CPU,服务器由做了嵌套虚拟化,所以最终测得的最高不超过400 Mbps的性能应该不是设备极限,毕竟VSR的CPU利用率都没有超过10%。
还是上次的测试拓扑。

这次我借来了颜总的高端笔记本,本次的测试环境配置如下:
主机:处理器Intel Core i7-8750H@2.2GHz(6核心12线程),16 GB内存
HCL版本:V5.10.1
VSR:Version 7.1.064, Release 1362P12,2核CPU,2 GB内存
openwrt:22.03,2核CPU,2 GB内存
首先以openwrt2为服务端,以openwrt3为客户端,使用系统自带的iperf 2.1.3进行测试。
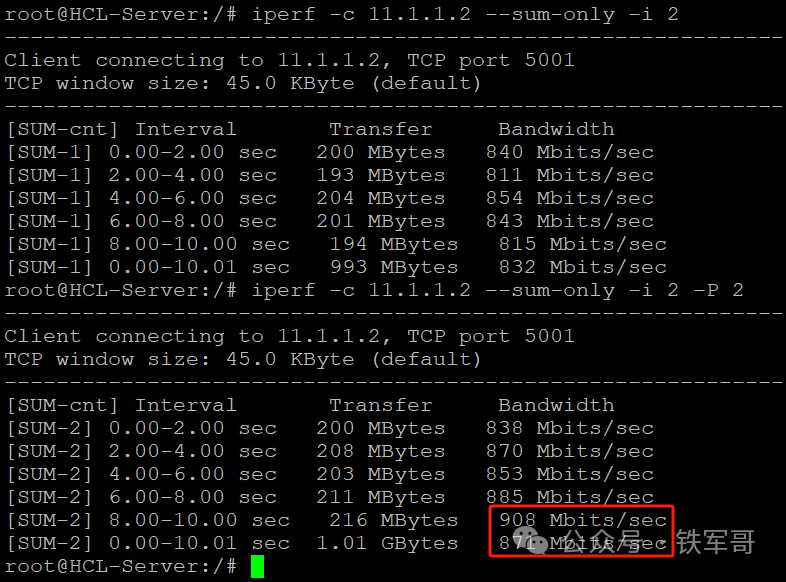
整体还不错,打了3次没有出现崩溃的情况,测试过程中出现的最高带宽为908 Mbps,整体871 Mbps的水平还算稳定。
接下来,我们对调一下服务端和客户端,再次测试一下。
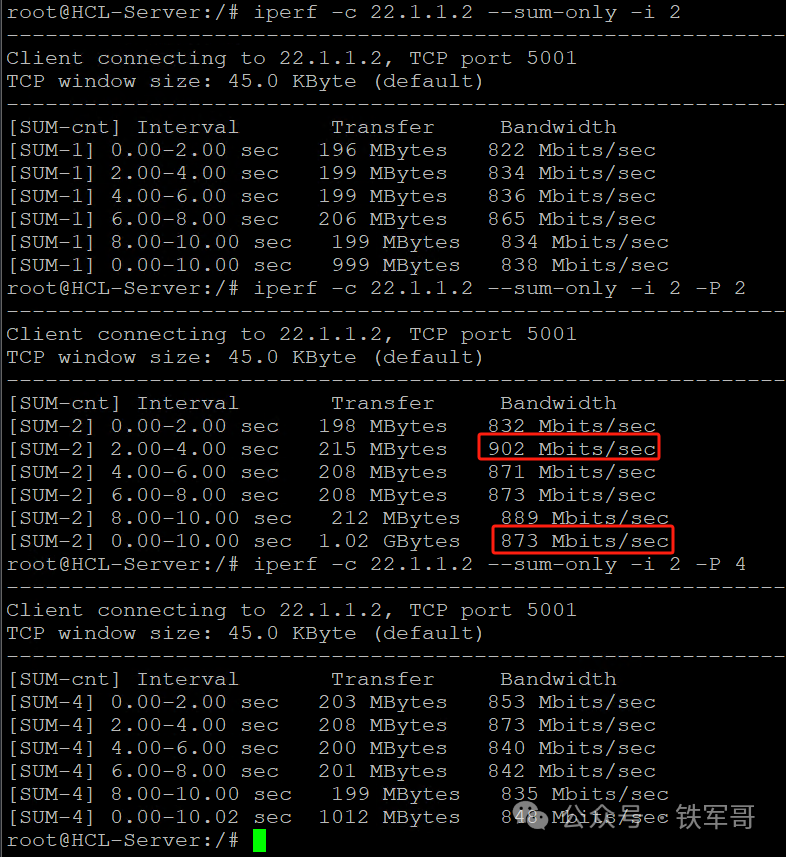
最高带宽为902 Mbps,整体873 Mbps的带宽性能比较稳定,多次测试未出现崩溃的情况。
如果我们查看VSR的负载,发现始终处于比较低的水平,多次测试CPU使用率未超过20%;所以瓶颈应该还是在openwrt上。
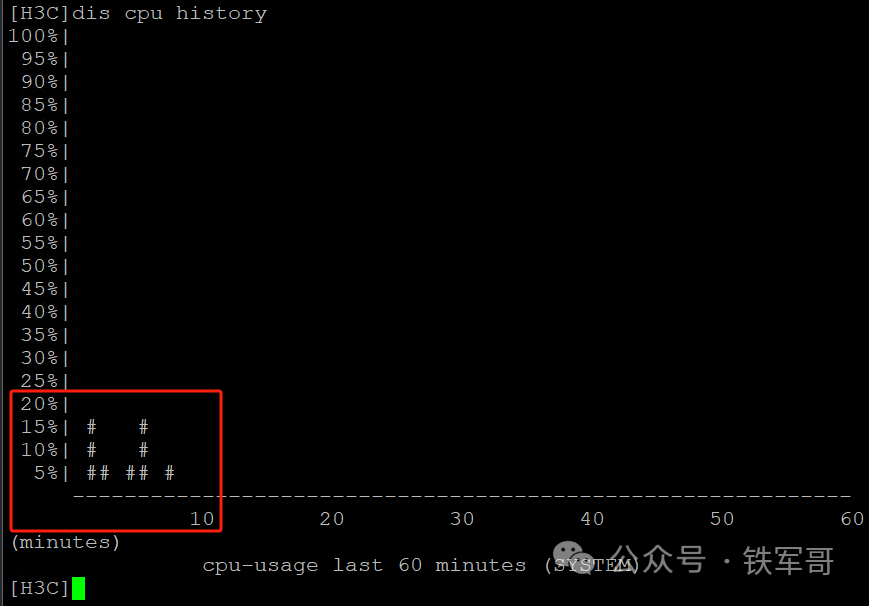
当然,应该也是受宿主机的性能影响,打流时CPU利用率一直介于80%-90%之间;但没有像我的低端电脑一样冲到98%,所以整体还是比较稳定。
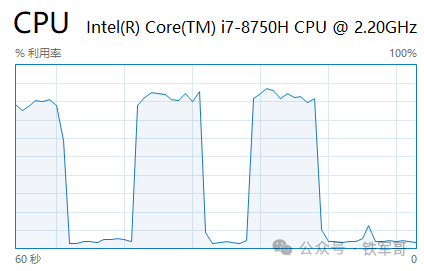
由此可见,HCL中虚拟设备的性能和电脑的CPU性能密不可分,为什么这么说呢?我们考虑以下几个方面,首先虚拟设备都是基于VirtualBox运行的,平台性能很大程度上决定了虚拟设备的性能上限;其次,如果我们细心观察,就可以发现虚拟设备之间的连线是通过UDPTunnel实现的,这种方式也是比较消耗CPU性能的,所以我的低端本才会出现网卡崩溃的情况。

了解到了问题所在,我们将网卡类型调整一下,将连接方式从通用驱动的UDPTunnel修改为仅主机网络,并将两根线路区分开,类似于我们在ESXi中使用的虚拟交换机。
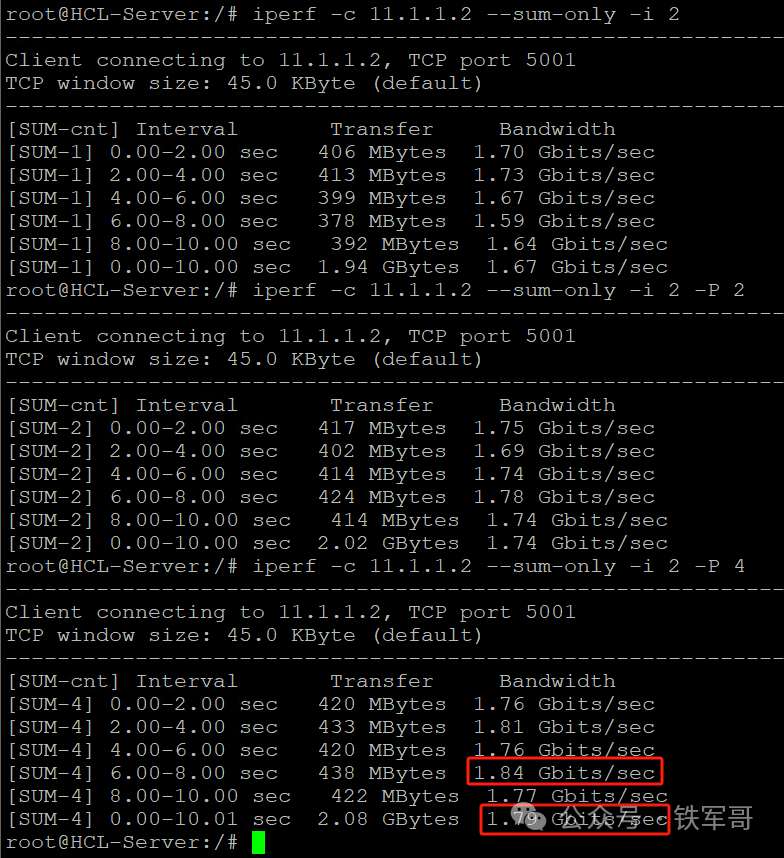
再次进行测试,转发带宽轻轻松松又翻了一倍多,直接来到了1.8 Gbps。
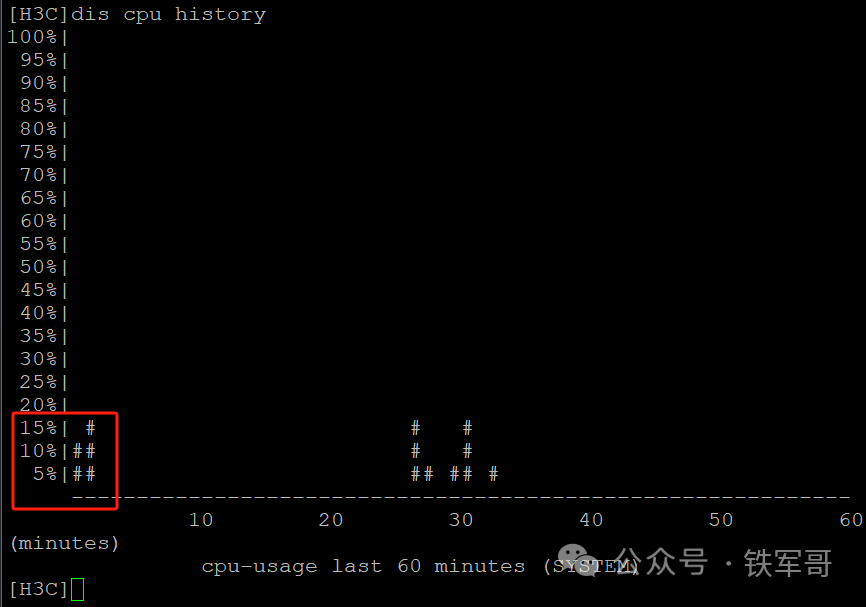
观察VSR的设备负载,CPU使用率依旧没有超过20%。
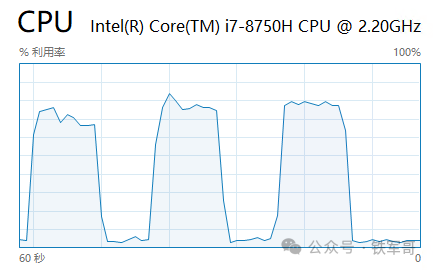
相比于之前,转发性能更高的同时,主机的CPU利用率还稍微有所降低,整体维持在不超过80%的水平。
既然都测到这了,那我就把HCL里的高端路由设备VSR-88和高端交换设备S6850也简单测试一下吧。
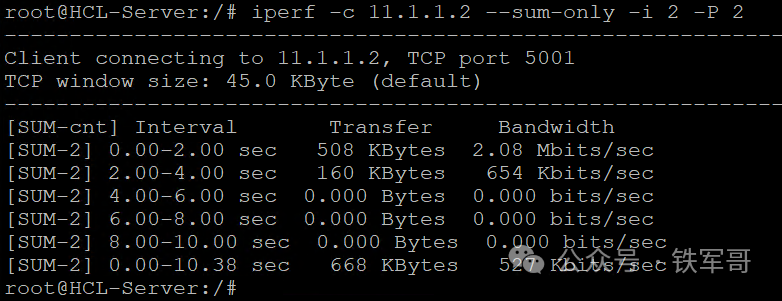
没想到啊,大风大浪都挺过来了,测试低端设备又翻了车了,而且测了几次,次次翻车,看来HCL里面的高端设备还得再优化一下啊!

长按二维码
关注我们吧


添加E1000网卡进行测试,只有VMXNET3性能的四分之一
TensorFlow识别GPU难道就这么难吗?还是我的GPU有问题?
同一个问题,Gemini、ChatGPT、Copilot、通义千问和文心一言会怎么答?
















 318
318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











