







 本文介绍了CSS热点区域的制作,包括使用:nth-child(even)选择器改变背景色,解决布局中的顺序问题,创建两栏或三栏布局,以及使用伪元素处理链接、广告标签和文本样式。重点讲解了浮动、BFC、行内样式和文本对齐的运用。
本文介绍了CSS热点区域的制作,包括使用:nth-child(even)选择器改变背景色,解决布局中的顺序问题,创建两栏或三栏布局,以及使用伪元素处理链接、广告标签和文本样式。重点讲解了浮动、BFC、行内样式和文本对齐的运用。
接下来要制作的就是热点区域了,首先是间隔性的背景颜色的改变,这里考虑用nth-child(even)
.section:nth-child(even){
background-color: #f7f7f7;
}nth-child(even) 常见问题:前面的元素干扰顺序问题
这里要注意一个问题,在数section是第几个子元素时,它会先找section的元素,从同等级的div子元素开始数,不是从有section类名的div中数,要解决这个问题,可以将有section的div全都包裹在另一个div盒子里,这样有section的子元素的类名全是section,就不会因为前面的div而影响顺序。
制作两栏或三栏布局
在这里我们可以为左边栏右边栏设置统一的类名,为其设置统一的样式,用到时只需添加类名即可
<div class="aside-left">
左边栏
</div>
<div class="aside-right">
右边栏
</div>
<div class="main">
主区域
</div>注意设置主区域时要为主区域设置BFC,使其达到避开浮动盒子自动适应的效果
.aside-left{
float: left;
width: 100px;
margin-right: 20px;
}
.aside-right{
float: right;
width: 265px;
margin-left: 30px;
}
.main{
/* 创建BFC,自适应,避开浮动盒子 */
overflow: hidden;
}接下来就是右边栏的设置了,右边栏包括广告图片(adv),部分标题(section-title)以及列表内容(hot-list),adv里又包含a元素,a元素里又嵌套一个img元素,可以统一设置广告图片的样式为宽度撑满,display为块盒(去掉白边),section-title中有可以包括一个h3元素和a元素,a元素前后又有一个括号,上括号和下括号均可使用伪元素选择器(before和after)
![]()
因为鼠标移入a元素时,括号背景颜色不变,因此不能在a元素上设置伪元素,此时可以在a元素外面再添加一个span设置span伪元素即可
<span class="link">
<!-- ( -->
<a href="">
去话题广场
</a>
<!-- ) -->
</span>
热门话题后的省略号同理也可使用伪元素选择器
.section-title .title::after{
content: " · · · · · · ";
}有时候热点后会加上一个标签,例如广告同理这里也可使用伪元素选择器
.adv-tag::after{
content: "广告";
font-size: 13px;
color: #c9c9c9;
}
host-list中也可分为两个部分,一个为标题,一个为描述(desc),描述中又有两个span元素,两个span元素之间隔有一些距离,可以设置span元素的margin-right,也可设置除第一个span元素之外其他span的margin-left
设置子元素出第一个之外的其他元素
除第一个之外的其他span元素,n从0开始
.hot-list li .desc span:nth-child(n+2){
}接着设置各个部分文字颜色等细节即可
热门区域代码:
.hot-list{
line-height: 1.5;
}
.hot-list li{
margin-bottom: 15px;
}
.hot-list li .title{
font-size: 14px;
}
.hot-list li .desc{
font-size: 13px;
color: #aaa;
}首页通用样式代码:
.container {
width: 950px;
margin: 0 auto;
}
.section{
padding: 35px 0;
}
/* 遇到双数的section时,设置以下样式 */
.section:nth-child(even){
background-color: #f7f7f7;
}
.aside-left{
float: left;
width: 100px;
margin-right: 20px;
}
.aside-right{
float: right;
width: 265px;
margin-left: 30px;
}
.main{
/* 创建BFC,自适应,避开浮动盒子 */
overflow: hidden;
}
.adv img{
width: 100%;
/* 去掉白边 */
display: block;
}
.section-title{
margin: 12px 0;
}
.section-title .title{
/* 水平排列,不独占一行 */
display: inline;
color: #072;
font-size: 15px;
}
.section-title .title::after{
content: " · · · · · · ";
}
.section-title .link{
font-size: 12px;
}
.section-title .link::before{
content: "(";
}
.section-title .link::after{
content: ")";
}
.adv-tag::after{
content: "广告";
font-size: 13px;
color: #c9c9c9;
}
/* 首页通用样式结束 */还有要注意的一点,右边栏中已经定款宽,热点标题如果太长应有换行效果,
全英文换行效果
如果全英文(无空格),则最终效果不会换行,故要给ul设置word-break:break-all(可在单词内部截断)
接着设置主区域的内容,主区域里又有section-title和hot-main,hot-main里又有向左浮动的区域,以及向右浮动的区域,向左浮动的区域里有四个ul,每个ul里有两部分,一个为照片(img),另一个为文字(words),照片是li加a加img,words里有两部分,一个a,一个span元素,观察一下这四个ul的排列方式
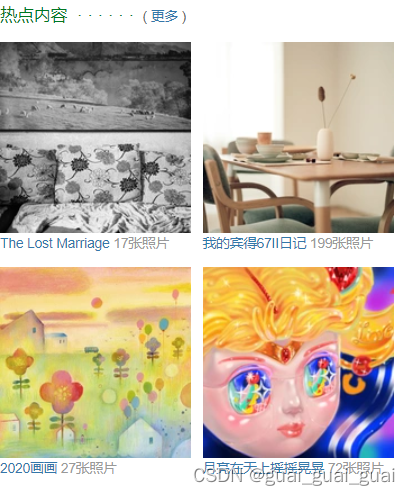
目前制作出来的效果如下:

两个两个排列在一行,此时最好不要用浮动,要频繁的解决高度坍塌问题,在这里我们将li元素定宽且变成一个行块盒,即可达到效果
接下来要让每一行中的li适应宽度排列,这里我们可以用到text-align的一个属性justify,即为分散对齐,但最后一行不会实现分散对齐,要想让最后一行实现该效果,可在最后一个li后面加上一个li宽度撑满成为最后一行,因为其高度为0,所以不会影响样式,也可以不添加元素,直接用样式解决,给ul设置一个伪元素即可。
.hot-main ul::after {
content: "";
display: inline-block;
width: 100%;
}接下来就该float-right了,注意设置其宽度,防止宽度太宽导致浮动元素换行,接着设置细节部分即可
<div class="float-left">
<ul>
<li>
<div class="img">
<a href="">
<img src="./imgs/热点1.webp" alt="">
</a>
</div>
<div class="words">
<a href="">
我们仍未知道那天所看见的论文的意义
</a>
<span>76张照片</span>
</div>
</li>
<li>
<div class="img">
<a href="">
<img src="./imgs/热点1.webp" alt="">
</a>
</div>
<div class="words">
<a href="">
我们仍未知道那天所看见的论文的意义
</a>
<span>76张照片</span>
</div>
</li>
<li>
<div class="img">
<a href="">
<img src="./imgs/热点1.webp" alt="">
</a>
</div>
<div class="words">
<a href="">
我们仍未知道那天所看见的论文的意义
</a>
<span>76张照片</span>
</div>
</li>
<li>
<div class="img">
<a href="">
<img src="./imgs/热点1.webp" alt="">
</a>
</div>
<div class="words">
<a href="">
我们仍未知道那天所看见的论文的意义
</a>
<span>76张照片</span>
</div>
</li>
<!-- <li style="width: 100%;"></li> -->
</ul>
</div>
<div class="float-right">
<ul>
<li>
<a href="">城市失忆症</a>
<div class="title">
菠萝的日记
</div>
<div class="desc">
从小家教比较严格,高中之前几乎杜绝了一切电子产品,没有手机,也没有电脑,去同学家玩还要胆战心惊。好处是读书几乎成为了唯一的娱乐,买书从来不会被限制,坏处是,小镇...
</div>
</li>
<li><a href="">Lorem ipsum dolor sit.</a></li>
<li><a href="">Error numquam minima praesentium.</a></li>
<li><a href="">Aperiam quidem atque eveniet.</a></li>
<li><a href="">Impedit nisi temporibus aut!</a></li>
<li><a href="">Ut iusto tempore recusandae.</a></li>
<li><a href="">Sequi reiciendis aut esse.</a></li>
<li><a href="">Ex voluptate enim reprehenderit!</a></li>
<li><a href="">Corrupti recusandae esse ab!</a></li>
<li><a href="">Voluptatem animi assumenda itaque!</a></li>
<li><a href="">Ipsum reiciendis similique blanditiis.</a></li>
</ul>
</div>.hot-list {
line-height: 1.5;
}
.hot-list li {
margin-bottom: 15px;
}
.hot-list li .title {
font-size: 14px;
}
.hot-list li .desc {
font-size: 13px;
color: #aaa;
}
/* 除第一个之外的其他span元素,n从0开始 */
/* .hot-list li .desc span:nth-child(n+2){
} */
.hot-list li .desc span {
margin-right: 4px;
}
.hot-main .float-left {
width: 350px;
}
.hot-main ul::after {
content: "";
display: inline-block;
width: 100%;
}
.hot-main .float-left li {
display: inline-block;
width: 170px;
font-size: 12px;
margin: 10px 0;
vertical-align: top;
}
.hot-main .float-left ul {
/* 分散对齐 */
text-align: justify;
line-height: 1.5;
}
.hot-main .float-left li .img img{
width: 100%;
display: block;
}
.hot-main .float-left li .words span{
color: #c9c9c9;
}
.hot-main .float-right{
width: 275px;
font-size: 12px;
}
.hot-main .float-right li{
margin-bottom: 12px;
}
.hot-main .float-right li .title{
color: #999;
}
.hot-main .float-right li .desc{
color: #666;
} 


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









