






思考:为什么JavaScript可以在浏览器中被执行
每个浏览器都有JS解析引擎,不同的浏览器使用不同的JavaScript解析引擎,待执行的js代码会在js解析引擎下执行
为什么JavaScript可以操作DOM和BOM
每个浏览器都内置了DOM、BOM这样的API函数,因此,浏览器中的JavaScript才可以调用他们
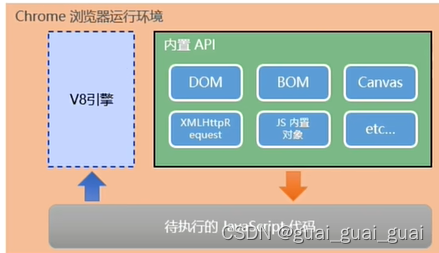
浏览器中的JavaScript运行环境
运行环境是指代码正常运行所需的必要环境
总结:
- V8引擎负责解析和执行JavaScript代码
- 内置API是由运行环境提供的特殊接口,只能在所属的运行环境中被调用
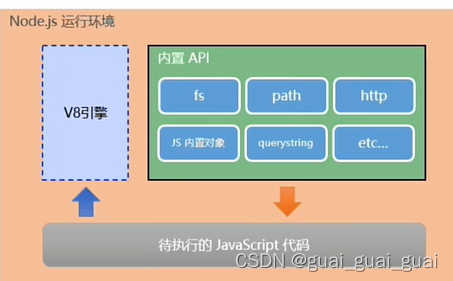
Node.js中的JavaScript运行环境
注意:
- 浏览器是JavaScript的前端运行环境
- Node.js是JavaScript的后端运行环境
- Node.js中无法调用DOM和BOM等浏览器内置API
// global顶级对象
console.log(global)
console.log(globalThis===global)//trueNode.js作用:
- 基于Express(http://www.expressjs.com/cn),可以快速构建Web应用
- 基于Electron框架(http://electronjs.org/),可以构建跨平台的桌面应用
- 基于restify框架(http://restify.com/),可以快速构建API借口项目
- 读写和操作数据库,创建实用的命令行工具辅助前端开发
Node.js环境的安装
区分LTS版本和Current版本的不同
- LTS为长期稳定版,对于追求稳定性的企业级项目来说,推荐安装LTS版本的Node.js
- Current为新特性尝鲜版,对热衷于尝试新特性的用户来说,推荐Current版本的Node.js,但是,Current版本中可能存在隐藏的Bug或安全漏洞,因此不推荐在企业级项目中使用Current版本的Node.js
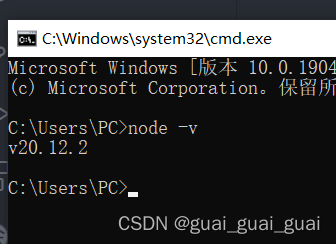
在终端中输入命令node -v可查看node.js是否安装成功
在Node.js环境中执行JavaScript代码
在终端中输入
node 要执行的js文件路径
注意要切换到文件所处的目录
cd 文件路径
终端中的快捷键
- 上箭头----快速定位到上一次命令
- tab键----补全文件路径
- esc键----快速清空当前已输入的命令
- 输入cls清空终端
终端中的常用命令:
- d: 将当前目录切换到d盘下
- dir 查看当前目录下的文件
- cd 切换工作目录
- cd.. 切换到上一级目录
- dir /s查看文件夹下所有文件的内容,包括子文件内的内容
Buffer
Buffer中文译为【缓冲区】,是一个类似于Array的对象,用于表示固定长度的字节序列,换句话说,Buffer就是一段固定长度的内存空间,用于处理二进制数据
特点:
- Buffer大小固定且无法调整
- Buffer性能较好,可以直接对计算机内存进行操作
- 每个元素的大小为1字节
创建Buffer的方法:
// alloc
let buf=Buffer.alloc(10)//创建一个十个字节的buffer,Buffer为内置模块,相当于全局变量
//alloc创建的二进制都会归零
// allocUnsafe
let buf_2=Buffer.allocUnsafe(10)//可能会包含之前旧的内存数据,不会对旧的数据进行清空,速率快,因为不用对旧数据进行处理
// from
let buf_3=Buffer.from('hello')//将一个字符串或数组转为Buffer,将每个字母对应为unicode所对应的数字,以十六进制呈现将buffer转为字符串
对Buffer元素的读写
let buf=Buffer.from('hello')
console.log(buf[0].toString(2))//转化为二进制
buf[0]=95
console.log(buf.toString())
// 溢出
let buf=Buffer.from('hello')
buf[0]=361//舍弃高位的数字 0001 0110 1001 =>0110 1001
// 中文
// utf-8中一个中文占三个字节进程
进行中的程序
线程
线程是一个进程中执行的一个执行流,一个线程是属于某个进程的
fs文件系统模块
fs模块是Node.js官方提供的、用来操作文件的模块,可以实现与硬盘的交互,它提供了一系列的方法和属性,用来满足用户对文件的操作需求
例如:
- fs.readFile()方法,用来读取文件中的内容
- fs.writeFile()方法,用来向指定的文件中写入内容
如果要在JavaScript代码中使用fs模块来操作文件,则需先使用如下的方法导入它:
fs.readFile()的语法格式
使用fs.readFile()方法,可以读取指定文件中的内容,语法格式如下:
fs.readFile(path[,options],callback)- 参数1:必选参数,字符串,表示文件的路径
- 参数2:可选参数,表示以什么编码格式来读取文件
- 参数3:必选参数,文件读取完成后,通过回调函数拿到读取的结果
// 导入fs模块 来操作文件
const fs=require('fs')
// fs.readFile(path[,options],callback)
// 调用fs.readFile()方法读取文件
// 参数1:读取文件的存放路径 参数2:读取文件时候采用的编码格式,一般默认指定utf-8参数3:回调函数 拿到读取失败和成功的结果 err dataStr
// fs.readFile('../files/1.txt','utf-8',function(err,dataStr){
// // 打印失败的结果
// // 如果读取成功 则err的值为null
// // 如果读取失败 则err的值为错误对象,dataStr的值为undefined
// console.log(err)
// // 打印成功的结果
// console.log(dataStr)
// })
fs.readFile('./files/1.txt','utf8',function(err,result){
if(err){
return console.log('文件读取失败'+err.message)
}
console.log('文件读取成功,内容是:'+result)
})
// 同步读取
let data=fs.readFileSync('./观书有感.txt')
console.log(data.toString())fs流式读取
// 1.引入fs模块
const fs=require('fs')
// 2.创建读取流对象
const rs=fs.createReadStream('./观书有感.txt')
// 3.绑定data事件 chunk块,读取一块数据之后就触发该事件
rs.on('data',chunk=>{
// console.log(chunk.length)//单位是字节
console.log(chunk.toString())
})
// 4.end可选事件
rs.on('end',()=>{
console.log('读取完成')
})向指定的文件中写入内容 fs.writeFile()
语法格式
fs.writeFile(file,data[,option],callback)- 参数1:必选参数,需要指定一个文件路径的字符串,表示文件的存放路径
- 参数2:必选参数,表示要写入的内容
- 参数3:可选参数,表示以什么格式写入文件内容,默认值是utf8
- 参数4:必选参数,文件写入完成后的回调函数
// 导入fs文件系统模块
const fs=require('fs')
// 调用fs.writeFile()方法 写入文件内容
// 参数1 表示文件的存放路径
// 参数2:表示要写入的内容
// 参数3:回调函数
fs.writeFile('./files/2.txt','abcd',function(err){
// 如果文件写入成功 则err的值等于null
// 如果文件写入失败 则err的值等于一个错误对象
console.log(err)
})
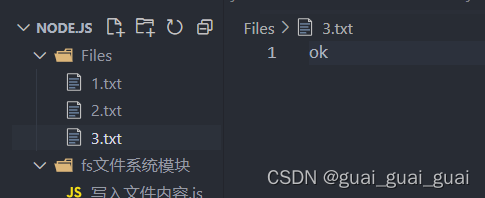
新建文件并判断是否写入成功 (3.txt并未初始并未创建)
// 导入fs文件系统模块
const fs=require('fs')
// 调用fs.writeFile()方法 写入文件内容
// 参数1 表示文件的存放路径
// 参数2:表示要写入的内容
// 参数3:回调函数
fs.writeFile('../files/3.txt','ok',function(err){
// 如果文件写入成功 则err的值等于null
// 如果文件写入失败 则err的值等于一个错误对象
// console.log(err)
if(err){
return console.log('文件写入失败'+err.message)
}
console.log('文件写入成功!')
})
// 同步写入
fs.writeFileSync('./data.txt','test')appendFile/appendFileSync追加写入
appendFile作用是在文件尾部追加内容,appendFile语法与writeFile语法完全相同
fs.appendFile(file,data[,options],callback)
fs.appendFile(file,data[,options])
返回值:二者都为undefined
const fs=require('fs')
fs.appendFile('./座右铭.txt','\r\n则其善者而从之,则其不善者而改之',err=>{
if(err){
console.log('写入失败')
return
}
console.log('追加写入成功')
})fs流式写入
// 流式写入
// 导入fs
const fs=require('fs')
// 创建写入流对象
const ws=fs.createWriteStream('./观书有感.txt')
// write
ws.write('半亩方糖一鉴开\r\n')
ws.write('天光云影共徘徊\r\n')
ws.write('问渠哪得清如许\r\n')
ws.write('为有源头活水来\r\n')
ws.close()程序打开一个文件是需要消耗资源的,流式写入可以减少打开关闭文件的次数
流式写入方式适用于大文件写入或者频繁写入的场景,writeFile适合于写入频率较低的场景
写入文件的场景
文件写入在计算机中是一个非常常见到的操作,下面的场景都用到了文件写入
- 下载文件
- 安装软件
- 保存程序日志,如Git
- 编辑器保存文件
- 视频录制
当需要持久化保存数据的时候,应该想到文件写入
练习 - 考试成绩整理
核心实现步骤:
- 导入需要的fs文件系统模块
- 使用fs.readFile()方法,读取素材目录下的成绩.txt文件
- 判断文件是否读取失败
- 文件读取成功后,处理成绩数据
- 将处理完成的成绩数据,调用fs.writeFile()方法,写入到新文件成绩- ok.txt中
// 1. 导入 fs 模块
const fs = require('fs')
// 2. 调用 fs.readFile() 读取文件的内容
fs.readFile('../素材/成绩.txt', 'utf8', function(err, dataStr) {
// 3. 判断是否读取成功
if (err) {
return console.log('读取文件失败!' + err.message)
}
// console.log('读取文件成功!' + dataStr)
// 4.1 先把成绩的数据,按照空格进行分割
const arrOld = dataStr.split(' ')
console.log(arrOld)
// 4.2 循环分割后的数组,对每一项数据,进行字符串的替换操作
const arrNew = []
arrOld.forEach(item => {
arrNew.push(item.replace('=', ':'))
})
console.log(arrNew)
// 4.3 把新数组中的每一项,进行合并,得到一个新的字符串
const newStr = arrNew.join('\r\n')//\r\n表示换行
console.log(newStr)
// 5. 调用 fs.writeFile() 方法,把处理完毕的成绩,写入到新文件中,在写的内容之后添加配置{flag:'a'}即可实现追加效果
fs.writeFile('./files/成绩-ok.txt', newStr, function(err) {
if (err) {
return console.log('写入文件失败!' + err.message)
}
console.log('成绩写入成功!')
})
})
fs练习 - 复制文件
/**
* 需求:
* 复制观书有感.txt
*/
const fs=require('fs')
// // 方式一 readFile
// // 读取文件内容
// let data=fs.readFileSync('./观书有感.txt')
// // 写入文件
// fs.writeFileSync('观书有感2.txt',data)
// 方式2 流式操作
// 创建读取流对象
const rs=fs.createReadStream('./观书有感.txt')
// 创建写入流对象
const ws=fs.createWriteStream('观书有感3.txt')
// 绑定data事件
rs.on('data',chunk=>{
ws.write(chunk)
})
//rs.pipe(ws)//直接写此代码就可实现复制流式操作占用内存小,它是将内存一块一块读取,一块一块写入,不需要很大的空间去复制
文件的重命名与移动
const fs=require('fs')
fs.rename('./座右铭.txt','./论语.txt',err=>{
if(err){
console.log('操作失败~')
return
}
console.log('操作成功')
})
//文件的移动
fs.rename('./观书有感3.txt','../1‘/观书有感3.txt',err=>{
if(err){
console.log('操作失败')
return
}
console.log('操作成功')
})删除文件
const fs=require('fs')
// 调用unlink方法 unlinkSync
fs.unlink('./观书有感2.txt',err=>{
if(err){
console.log('删除失败')
return
}
console.log('删除成功')
})
//调用rm方法 rmSync
fs.rm('./观书有感2.txt',err=>{
if(err){
console.log('删除失败')
return
}
console.log('删除成功')
})文件夹操作
// 创建文件夹
const fs=require('fs')
// fs.mkdir('./html',err=>{
// if(err){
// console.log('创建失败')
// return
// }
// console.log('创建成功')
// })
// 递归创建 recursive:true表示允许递归创建
// fs.mkdir('./a/b/c',{recursive:true},err=>{
// if(err){
// console.log('创建失败')
// return
// }
// console.log('创建成功')
// })
// 读取文件夹
// fs.readdir('./',(err,data)=>{
// if(err){
// console.log('读取失败')
// return
// }
// console.log(data)//可得到目标文件夹下的资源列表
// })
// 删除文件夹 rm remove删除
// fs.rmdir('./html',err=>{
// if(err){
// console.log('删除失败')
// return
// }
// console.log('删除成功')
// })
// 递归删除
// fs.rmdir('./a',{recursive:true},err=>{
// if(err){
// console.log('删除失败')
// return
// }
// console.log('删除成功')
// })
fs.rm('./a',{recursive:true},err=>{
if(err){
console.log('删除失败')
return
}
console.log('删除成功')
})fs查看资源状态
const fs=require('fs')
// 查看资源状态 stat 方法 status缩写 状态
fs.stat("./注意.js",(err,data)=>{
if(err){
console.log('操作失败')
return
}
// ifFile获取文件的类型
console.log(data.isFile())
// isDirectory判断是不是文件夹
console.log(data.isDirectory())
}
)fs模块 - 路径动态拼接问题
在使用fs模块操作文件时,如果提供的操作路径是以./或../开头的相对路径时,很容易出现路径动态拼接错误的问题
原因:代码在运行的时候,会以执行node命令时所处的目录,动态拼接出被操作文件的完整路径
解决方案:在使用fs模块操作文件时,直接提供完整的路径,不要提供./或../开头的相对路径,从而防止路径动态拼接的问题
const fs = require('fs')
// 出现路径拼接错误的问题,是因为提供了 ./ 或 ../ 开头的相对路径
// 如果要解决这个问题,可以直接提供一个完整的文件存放路径就行
/* fs.readFile('./files/1.txt', 'utf8', function(err, dataStr) {
if (err) {
return console.log('读取文件失败!' + err.message)
}
console.log('读取文件成功!' + dataStr)
}) */
// 移植性非常差、不利于维护 注意将\写成\\ 转义字符
/* fs.readFile('C:\\Users\\escook\\Desktop\\Node.js基础\\day1\\code\\files\\1.txt', 'utf8', function(err, dataStr) {
if (err) {
return console.log('读取文件失败!' + err.message)
}
console.log('读取文件成功!' + dataStr)
}) */
// __dirname 表示当前文件所处的目录
// console.log(__dirname)
fs.readFile(__dirname + '/files/1.txt', 'utf8', function(err, dataStr) {
if (err) {
return console.log('读取文件失败!' + err.message)
}
console.log('读取文件成功!' + dataStr)
})
fs练习-批量重命名
const fs=require('fs')
// 读取文本夹
const files=fs.readdirSync('./代码')
// 遍历数组
files.forEach(item=>{
// 拆分文件名
let data=item.split('-')
let [num,name]=data
// 判断
if(Number(num)<10){
num='0'+num
}
// 创建新的文件名
let newName=num+'-'+name
console.log(newName)
// 重命名
fs.renameSync(`./代码/${item}`,`./代码/${newName}`)
})Path路径模块
path模块是Node.js官方提供的,用来处理路径的模块,它提供了一系列的方法和属性,用来满足用户对路径的处理需求。
例如:
- path.join()方法,用来将多个路径片段拼接成一个完整的路径字符串
- path.basename()方法,用来从路径字符串中将文件名解析出来
如果要在JavaScript代码中,使用path模块来处理路径,则需要先使用如下方式导入path
const path = require('path')path.join()代码示例
使用path.join()方法,可以把多个路径片段拼接为完整的路径字符串:
const path = require('path')
const fs = require('fs')
// 注意: ../ 会抵消前面的路径
// const pathStr = path.join('/a', '/b/c', '../../', './d', 'e')
// console.log(pathStr) // \a\d\e
// fs.readFile(__dirname + '/files/1.txt')
fs.readFile(path.join(__dirname, './files/1.txt'), 'utf8', function(err, dataStr) {
if (err) {
return console.log(err.message)
}
console.log(dataStr)
})
注意:今后凡是涉及到路径拼接的操作,都要使用path.join()方法进行处理,不要直接使用+字符串拼接,也可使用path.resolve()方法处理
获取路径中的文件名path.basename()格式
使用path.basename()方法,可以获取路径中的最后一部分,经常通过这个方法获取路径中的文件名,语法格式如下:
path.basename(path[,ext])参数解读:
- path<string>必选参数,表示一个路径的字符串
- ext<string>可选参数,表示文件扩展名
- 返回:<string>表示路径中的最后一部分
const path = require('path')
// 定义文件的存放路径
const fpath = '/a/b/c/index.html'
const fullName = path.basename(fpath)
console.log(fullName)
const nameWithoutExt = path.basename(fpath, '.html')
console.log(nameWithoutExt)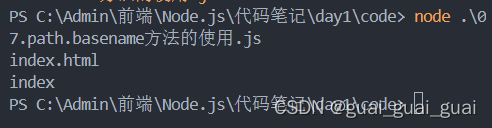
获取路径中的文件扩展名path.extname()
使用path.extname()方法,可以获取路径中的扩展名部分,语法格式如下:
path.extname(fpath)参数解读:
- path<string>必选参数,表示一个路径的字符串
- 返回:<string>返回得到的扩展名字符串
const path = require('path')
// 这是文件的存放路径
const fpath = '/a/b/c/index.html'
const fext = path.extname(fpath)
console.log(fext)

// resolve 解决
console.log(path.resolve(__dirname,'./index.html'))
// sep分隔符
console.log(path.sep)//window / Linux /
// parse 方法 解析路径并返回对象
let str='D:\\nodeJS\\13-path\\代码\\path.js'
console.log(path.parse(str))综合案例 - 时钟案例
案例的实现步骤
-
创建两个正则表达式,分别用来匹配<style>和<script>标签
// 1.1 导入 fs 模块
const fs = require('fs')
// 1.2 导入 path 模块
const path = require('path')
// 1.3 定义正则表达式,分别匹配 <style></style> 和 <script></script> 标签
const regStyle = /<style>[\s\S]*<\/style>/ // /s/S表示匹配任意字符
const regScript = /<script>[\s\S]*<\/script>/-
使用fs模块,读取需要被处理的HTML文件
// 2.1 调用 fs.readFile() 方法读取文件
fs.readFile(path.join(__dirname, '../素材/index.html'), 'utf8', function(err, dataStr) {
// 2.2 读取 HTML 文件失败
if (err) return console.log('读取HTML文件失败!' + err.message)
// 2.3 读取文件成功后,调用对应的三个方法,分别拆解出 css, js, html 文件
resolveCSS(dataStr)
resolveJS(dataStr)
resolveHTML(dataStr)
})-
自定义resolveCSS方法,来写入index.css样式文件
// 3.1 定义处理 css 样式的方法
function resolveCSS(htmlStr) {
// 3.2 使用正则提取需要的内容
const r1 = regStyle.exec(htmlStr)//选出匹配正则表达式内的字符串
// 3.3 将提取出来的样式字符串,进行字符串的 replace 替换操作
const newCSS = r1[0].replace('<style>', '').replace('</style>', '')
// 3.4 调用 fs.writeFile() 方法,将提取的样式,写入到 clock 目录中 index.css 的文件里面
fs.writeFile(path.join(__dirname, './clock/index.css'), newCSS, function(err) {
if (err) return console.log('写入 CSS 样式失败!' + err.message)
console.log('写入样式文件成功!')
})
}-
自定义resolveJS方法,来写入index.js文件
// 4.1 定义处理 js 脚本的方法
function resolveJS(htmlStr) {
// 4.2 通过正则,提取对应的 <script></script> 标签内容
const r2 = regScript.exec(htmlStr)
// 4.3 将提取出来的内容,做进一步的处理
const newJS = r2[0].replace('<script>', '').replace('</script>', '')
// 4.4 将处理的结果,写入到 clock 目录中的 index.js 文件里面
fs.writeFile(path.join(__dirname, './clock/index.js'), newJS, function(err) {
if (err) return console.log('写入 JavaScript 脚本失败!' + err.message)
console.log('写入 JS 脚本成功!')
})
}-
自定义resolveHTML方法,来写入index.html文件
// 5.1 定义处理 HTML 结构的方法
function resolveHTML(htmlStr) {
// 5.2 将字符串调用 replace 方法,把内嵌的 style 和 script 标签,替换为外联的 link 和 script 标签
const newHTML = htmlStr.replace(regStyle, '<link rel="stylesheet" href="./index.css" />').replace(regScript, '<script src="./index.js"></script>')
// 5.3 写入 index.html 这个文件
fs.writeFile(path.join(__dirname, './clock/index.html'), newHTML, function(err) {
if (err) return console.log('写入 HTML 文件失败!' + err.message)
console.log('写入 HTML 页面成功!')
})
}案例两个注意点:
- fs.writeFile()方法只能用来创建文件,不能用来创建路径
- 重复调用fs.write()写入同一个文件,新写入的内容会覆盖之前的内容
http模块
- 在网络节点中,负责免费消费资源的电脑,叫做客户端,负责对外提供网络资源的电脑,叫做服务器
- http模块是Node.js官方提供的、用来创建web服务器的模块,通过http模块提供的http.createServer()方法,就能方便的把一台普通的电脑,变成一台Web服务器,从而对外提供Web资源服务
如果希望使用http模块创建Web服务器,则需要先导入它:
const http=require('http')进一步理解http模块的作用
服务器和普通电脑的区别在于,服务器上安装了web服务器软件,例如:IIS,Apache等。通过安装这些服务器软件,就能把一台普通的电脑变成一web服务器。
在Node.js中,我们不需要使用IIS,Apache等这些第三方服务器软件,因为我们可以基于Node.js提供的http模块,通过几行简单的代码,就能轻松的手写一个服务器软件,从而对外提供web服务
服务器相关的概念
IP地址
IP地址就是互联网上每台计算机的唯一地址,因此IP地址具有唯一性,如果把“个人电脑”比作“一台电话”,那么“IP地址“就相当于”电话号码“,只有知道对方IP地址的前提下,才能与对应的电脑之间进行数据通信。
IP地址的格式:通常用”点分十进制“表示成(a,b,c,d)的形式,其中,abcd都是0~255之间的十进制整数,例如:用点分十进表示的IP地址(192.168.1.1)
IP的分类
- 本机回环IP地址
- 局域网IP地址(私网IP)
- 广域网IP地址(公网IP)
注意:
- 互联网中每台Web服务器,都有自己的IP地址,在window中运行ping www.baidu.com命令,即可查看到百度服务器的IP地址
- 在开发期间,自己的电脑既是一台服务器,也是一个客户端,为了方便测试,可以在自己的浏览器中输入127.0.0.1这个IP地址,就可以把自己的电脑当成一台服务器进行访问了
域名和域名服务器
尽管IP地址能够唯一地标记网络上的计算机,但IP地址是一长串数字,不直观,而且不便于记忆,于是人们又发明了另一套字符型地地址方案,即所谓的域名(Domain Name)地址
IP地址和域名是一一对应关系,这份对应关系存放在一种叫做域名服务器(DNS,Domain name server)的电脑中。使用时只需通过好记的域名访问对应的服务器即可,对应的转换工作由域名服务器实现,因此,域名服务器就是提供IP地址和域名之间的转换服务的服务器
注意:
- 单纯使用IP地址,互联网中的电脑也能够正常工作。但是有了域名的加持,能让互联网的世界变得更加方便
- 在开发测试期间,127.0.0.1对应的域名是localhost,它们都代表我们自己的电脑,在使用效果上没有任何区别
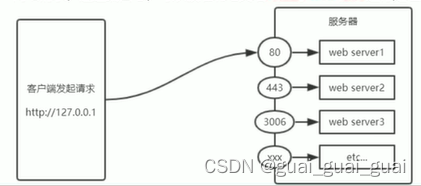
端口号
端口是应用程序的数字标识,主要作用是实现了不同主机应用程序之间的通信
计算机中的端口号,就好像是现实生活中的门牌号一样,通过门牌号,外卖小哥可以在整栋大楼众多的房间中,准确的把外卖送到你的手中
同样的道理,在一台电脑中,可以运行成百上千web服务,每个web服务都对应唯一的端口号,客户端发送过来的网络请求,通过端口号可以被准确地交给对应的web服务进行处理
注意:
- 每个端口号不能同时被多个服务器所占用
- 在实际应用中,URL中的80端口可以被省略
创建基本的web服务器
创建web服务器的基本步骤
-
导入http模块
如果希望在自己的电脑上创建一个web服务器,从而对外提供web服务,则需要导入http模块:
const http=require('http')-
创建web服务器实例
调用http.creatServer()方法,即可快速创建一个web服务器实例:
const server=http.creatServer()-
为服务器实例绑定request事件,监听客户端的请求
为服务器实例绑定request事件,即可监听客户端发送过来的网络请求
server.on('request', function (req, res) {
console.log('Someone visit our web server.')
})-
启动服务器
调用服务器实例的.listen()方法,即可启动当前的web服务器实例
server.listen(8080, function () {
console.log('server running at http://127.0.0.1:8080')
})// 1. 导入 http 模块
const http = require('http')
// 2. 创建 web 服务器实例
const server = http.createServer()
// 3. 为服务器实例绑定 request 事件,监听客户端的请求
server.on('request', function (req, res) {
console.log('Someone visit our web server.')
})
// 4. 启动服务器
server.listen(80, function () {
console.log('server running at http://127.0.0.1:8080')
})注意事项
- 命令行ctrl+c停止服务
- 当服务启动后,更新代码必须重启服务之后才能生效
- 相应内容中文乱码的解决方法
response.setHeader('content-type','text/html;charset=utf-8')- 端口号被占用
Error:listen EADDRINUSE: address already in use :::9000
- 关闭当前正在运行监听端口的服务(使用较多)
- 修改其他端口号
- HTTP协议默认端口是80,HTTPS协议的默认端口是443,HTTP服务开发常用端口有3000,8080,8090,9000等
如果端口被其他程序占用,可以使用资源监视器找到占用端口的程序,然后使用任务管理器关闭对应的程序
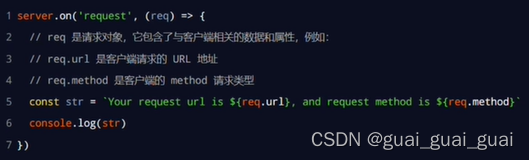
req请求对象
只要服务器接收到了客户端的请求,就会调用通过server.on()为服务器绑定的request事件处理函数
如果想在事件处理函数中,访问与客户端相关的数据或属性,可以使用如下方式:
res响应对象
在服务器的request事件处理函数中,如果想访问与服务器相关的数据或属性,可以使用如下的方式

const http = require('http')
const server = http.createServer()
// req 是请求对象,包含了与客户端相关的数据和属性
server.on('request', (req, res) => {
// req.url 是客户端请求的 URL 地址,只包含路径和查询字符串
const url = req.url
// req.method 是客户端请求的 method 类型
const method = req.method
console.log(req.httpVersion)//获取HTTP协议的版本号
console.log(req.headers)//获取HTTP的请求头
console.log(req.headers.host)
const str = `Your request url is ${url}, and request method is ${method}`
console.log(str)
// 调用 res.end() 方法,向客户端响应一些内容
res.end(str)
})
server.listen(80, () => {
console.log('server running at http://127.0.0.1')
})提取HTTP报文中URL的路径和查询字符串
// 提取HTTP报文中URL的路径与查询字符串
const http=require('http')
const url=require('url')
const server=http.createServer((request,response)=>{
let res=url.parse(request.url,true)//解析url,true表示query会变成一个对象
console.log(res)
// let pathname=res.pathname
// console.log(pathname)
// let keyword=res.query.keyword
// console.log(keyword)
response.end('url')
})
server.listen(9000,()=>{
console.log('服务已经启动...')
})// 提取HTTP报文中URL的路径与查询字符串
const http=require('http')
const url=require('url')
const server=http.createServer((request,response)=>{
// 实例化url的对象
// let url=new URL('/search?a=100&b=200','http://127.0.0.1:9000')
let url=new URL(request.url,'http://127.0.0.1:9000')
console.log(url)
console.log(url.pathname)
console.log(url.searchParams.get('keyword'))
response.end('url')
})
server.listen(9000,()=>{
console.log('服务已经启动...')
})const http=require('http')
const url=require('url')
const server=http.createServer((request,response)=>{
// 设置相应状态码
response.statusCode=203
// 响应状态的描述
response.statusMessage='i love you'
// 响应头
response.setHeader('content-type','text/html;charset=utf-8')
response.setHeader('Server','Node.js')
response.setHeader('MyHeader','test')
response.setHeader('test',['q','d'])
// 响应体的设置
response.write('loved')//可多次调用返回
response.end('response')//有且只有一个end
})
server.listen(9000,()=>{
console.log('服务已经启动...')
})解决中文乱码问题
当调用res.end()方法,向客户端发送中文内容的时候,会出现乱码问题,此时,需要手动设置内容的编码格式
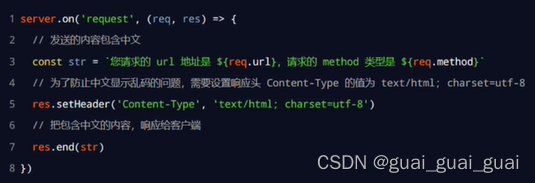
const http = require('http')
const server = http.createServer()
server.on('request', (req, res) => {
// 定义一个字符串,包含中文的内容
const str = `您请求的 URL 地址是 ${req.url},请求的 method 类型为 ${req.method}`
// 调用 res.setHeader() 方法,设置 Content-Type 响应头,解决中文乱码的问题
res.setHeader('Content-Type', 'text/html; charset=utf-8')
// res.end() 将内容响应给客户端
res.end(str)
})
server.listen(80, () => {
console.log('server running at http://127.0.0.1')
})
将html页面响应回浏览器中:
const http=require('http')
const fs=require('fs')
const server=http.createServer((request,response)=>{
let html=fs.readFileSync('../atguigu/代码/test.html')
response.end(html)
})
server.listen(9000,()=>{
console.log('服务已经启动 http://127.0.0.1:9000')
})同时响应css文件和js文件
const http=require('http')
const fs=require('fs')
const server=http.createServer((request,response)=>{
let {pathname}=new URL(request.url,'http://127.0.0.1')
if(pathname==='/'){
let html=fs.readFileSync('../atguigu/代码/test.html')
response.end(html)
}else if(pathname==='/test.css'){
let css=fs.readFileSync('../atguigu/代码/test.css')
response.end(css)
}else if(pathname==='/test.js'){
let js=fs.readFileSync('../atguigu/代码/test.js')
response.end(js)
}else{
response.statusCode=404
response.end('<h1>404 Not Found</h1>')
}
})
server.listen(9000,()=>{
console.log('服务已经启动 http://127.0.0.1:9000')
})静态资源服务
- 静态资源是指内容长时间不发生改变的资源,例如图片,视频,css文件,js文件,HTML文件,字体文件等
- 动态资源是指内容经常更新的资源,例如百度首页,网易首页,京东搜索列表页面等
搭建静态资源服务
const http=require('http')
const fs=require('fs')
const server=http.createServer((request,response)=>{
let {pathname}=new URL(request.url,'http://127.0.0.1')
let filePath=__dirname+'/page'+pathname
// 读取文件fs异步API
fs.readFile(filePath,(err,data)=>{
if(err){
response.statusCode=500
response.end('文件读取失败')
}
// 响应文件内容
response.end(data)
})
})
server.listen(9000,()=>{
console.log('服务已经启动 http://127.0.0.1:9000')
})网站根目录或静态资源目录
网站根目录在哪个文件夹中寻找静态资源,哪个文件夹就是静态资源目录,也称之为网站根目录
vscode中使用live-server访问HTML时,它启动的服务网站根目录是vscode所打开的文件夹
设置资源类型(mime类型)
媒体类型(通常称为Multipurpose Internet Mail Extensions或MIME类型)是一种标准,用来表示文档,文件或字节流的性质和格式

HTTP服务可以设置响应头Content-Type来表明响应体的MIME类型,浏览器回根据类型决定如何处理资源
下面是常见文件对应的mime类型

let mimes={
html:'text/html',
css:'text/css',
js:'text/javascript',
png:'image/png',
jpg:'image/jpeg',
gif:'image/gif',
mp4:'video/mp4',
mp3:'audio/mpeg',
json:'application/json'
}
const http=require('http')
const fs=require('fs')
const server=http.createServer((request,response)=>{
if(request.method!=='GET'){
response.statusCode=405
response.end('<h1>405 Method Not Allowed</h1>')
return
}
let {pathname}=new URL(request.url,'http://127.0.0.1')
let filePath=__dirname+'/page'+pathname
// 读取文件fs异步API
fs.readFile(filePath,(err,data)=>{
if(err){
response.setHeader('content-type','text/html;charset=utf-8')
switch(err.code){
case 'ENOENT':
response.statusCode=404
response.end('<h1>404 Not Found</h1>')
case 'EPERM':
response.statusCode=403
response.end('<h1>403 Forbidden</h1>')
}
return
}
// 获取文件的后缀名
let ext=path.extname(filePath).slice(1)//从下标1开始截取
// 获取对应的类型
let type=mimes[ext]
if(type){
// 匹配到了
if(ext==='html'){
response.setHeader('content-type',type+';charset=utf-8')
}
else {
response.setHeader('content-type','application/octet-stream')
}
}
// 响应文件内容
response.end(data)
})
})
server.listen(9000,()=>{
console.log('服务已经启动 http://127.0.0.1:9000')
})GET请求的情况
- 在地址栏直接输入url访问
- 点击a链接
- link标签引入css
- script标签引入js
- video与audio引入多媒体
- img标签引入图片
- form标签中的method为get
- ajax中的get请求
POST请求的情况:
- form标签中的method为post
- AJAX的posti请求
GET和POST请求的区别
GET和POST是HTTP协议请求的两种方式,主要有以下区别:
- 作用,GET主要用来获取数据,POST主要用来提交数据
- 参数位置,GET带参数请求时将参数缀到URL之后,POST带参数请求是将参数放在请求体中
- 安全型,POST请求相对于GET安全一些,因为在浏览器中参数会暴露在地址栏
- GET请求大小有限制,一般为2k,而POST请求则没有大小限制
根据不同的url响应不同的html内容
核心实现步骤
- 获取请求的url地址
- 设置默认的响应内容为404 Not found
- 判断用户请求的是否为/或/index.html首页
- 判断用户请求的是否为/about.html关于页面
- 设置Content-Type响应头,防止中文乱码
- 使用res.end()把内容响应给客户端
动态响应内容
const http = require('http')
const server = http.createServer()
server.on('request', (req, res) => {
// 1. 获取请求的 url 地址
const url = req.url
// 2. 设置默认的响应内容为 404 Not found
let content = '<h1>404 Not found!</h1>'
// 3. 判断用户请求的是否为 / 或 /index.html 首页
// 4. 判断用户请求的是否为 /about.html 关于页面
if (url === '/' || url === '/index.html') {
content = '<h1>首页</h1>'
} else if (url === '/about.html') {
content = '<h1>关于页面</h1>'
}
// 5. 设置 Content-Type 响应头,防止中文乱码
res.setHeader('Content-Type', 'text/html; charset=utf-8')
// 6. 使用 res.end() 把内容响应给客户端
res.end(content)
})
server.listen(80, () => {
console.log('server running at http://127.0.0.1')
})
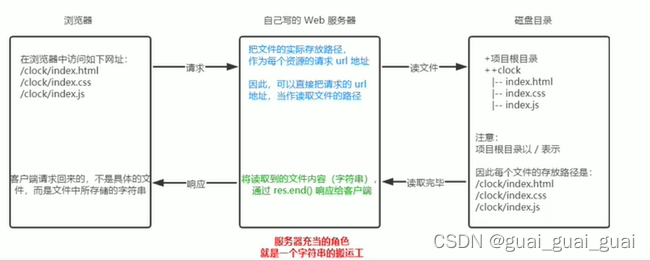
案例 - 实现clock时钟的web服务器
核心思路:
把文件的实际存放路径,作为每个资源请求的url地址
实现步骤:
-
导入需要的模块
-
创建基本的web服务器
-
将资源的请求url地址映射为文件的存放路径
-
读取文件内容并响应给客户端

-
优化资源的请求路径

// 1.1 导入 http 模块
const http = require('http')
// 1.2 导入 fs 模块
const fs = require('fs')
// 1.3 导入 path 模块
const path = require('path')
// 2.1 创建 web 服务器
const server = http.createServer()
// 2.2 监听 web 服务器的 request 事件
server.on('request', (req, res) => {
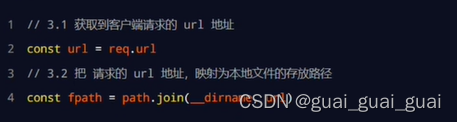
// 3.1 获取到客户端请求的 URL 地址
// /clock/index.html
// /clock/index.css
// /clock/index.js
const url = req.url
// 3.2 把请求的 URL 地址映射为具体文件的存放路径
// const fpath = path.join(__dirname, url)
// 5.1 预定义一个空白的文件存放路径
let fpath = ''
if (url === '/') {
fpath = path.join(__dirname, './clock/index.html')
} else {
// /index.html
// /index.css
// /index.js
fpath = path.join(__dirname, '/clock', url)
}
// 4.1 根据“映射”过来的文件路径读取文件的内容
fs.readFile(fpath, 'utf8', (err, dataStr) => {
// 4.2 读取失败,向客户端响应固定的“错误消息”
if (err) return res.end('404 Not found.')
// 4.3 读取成功,将读取成功的内容,响应给客户端
res.end(dataStr)
})
})
// 2.3 启动服务器
server.listen(80, () => {
console.log('server running at http://127.0.0.1')
})
模块化
模块化是指解决一个复杂问题时,自顶向下逐层把系统划分成若干模块的过程,对于整个系统来说,模块是可组合,分解和更换的单元
编程领域中的模块化
编程领域中的模块化就是遵守固定的规则,把一个大文件拆成独立并且相互依赖的多个小模块
把代码进行模块化拆分的好处:
- 提高了代码的复用性
- 提高了代码的可维护性
- 可以实现按需加载
模块化规范
模块化规范就是对代码进行模块化的拆分与组合时,需要遵守的那些规则
例如:
- 使用什么样的语法格式来引用模块
- 在模块中使用什么样的语法格式向外暴露成员
模块化规范的好处:大家都遵守同样的模块化规范写代码,降低了沟通的成本,极大的方便了各个模块之间的相互调用,利人利己
Node.js中模块的分类
Node.js中根据2模块来源的不同,将模块分为3大类,分别是:
- 内置模块(内置模块是由Node.js官方提供的,例如fs,path,http等)
- 自定义模块(用户创建的每个js文件,都是自定义模块)
- 第三方模块(由第三方开发出来的模块,并非官方提供的内置模块,也不是用户创建的自定义模块,使用前需要先下载)
加载模块
使用强大的require()方法,可以加载需要的内置模块,用户自定义模块,第三方模块进行使用。例如

注意:使用require()方法加载其他模块时,会执行被加载模块中的代码

require导入自定义模块的基本流程
- 将相对路径转为绝对路径,定位目标文件
- 缓存检测
- 读取目标文件代码
- 包裹为一个函数并执行(自执行函数),通过arguments.callee.toString()查看自执行函数
- 缓存模块的值
- 返回module.exports的值
function require(file){
// 1.将相对路径转为绝对路径,定位目标文件
let absolutePath=path.resolve(__dirname,file)
// 2.缓存检测
if(caches[absolutePath]){
return chches[absolutePath]
}
// 3.读取文件的代码
let code=fs.readFileSync(absolutePath).toString()
let module={}
let exports=module.exports={}
// 包裹为一个函数 然后执行
(function(exports,require,module,__filename,__dirname){
const test={
name:'尚硅谷'
}
module.exports=test
// 输出
console.log(arguments.callee.toString())
})(exports,require,module,__filename,__dirname)
// 5.缓存结果
caches[absolutePath]=module.exports
// 6.返回module.exports的值
return module.exports
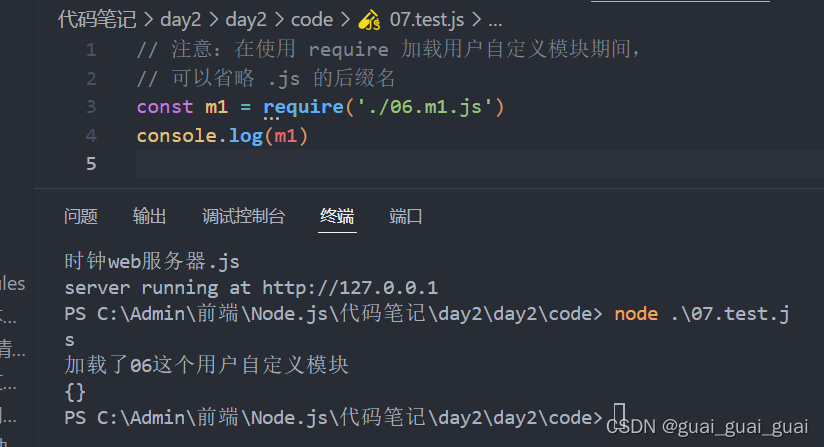
}require使用的一些注意事项
- 对于自己创建的模块,导入时路径建议写相对路径,且不能省略./和../
- js和json文件时可以不用写后缀,c/c++编写的node扩展文件也可以不写后缀,但是一般用不到,先找js,再找json
- 如果导入其它类型的文件,会以js文件进行处理
- 如果导入的路径是个文件夹,则会首先检测该文件夹下package.json文件中main属性对应的文件,如果main属性不存在,或者package.json不存在,则会检测文件夹下index.js和index.json,如果还是没有找到,就会报错
- 导入node.js内置模块中,直接require模块的名字即可,无需加./和../
Node.js中的模块作用域
模块作用域和函数作用域类似,在自定义模块中定义的变量、方法等成员,只能在当前模块内被访问,这种模块级别的访问限制,叫做模块作用域
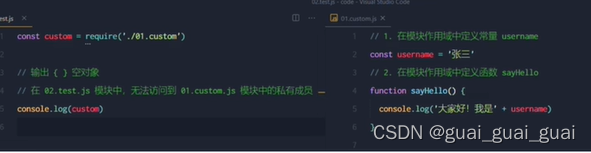
模块作用域的好处
防止了全局变量污染的问题
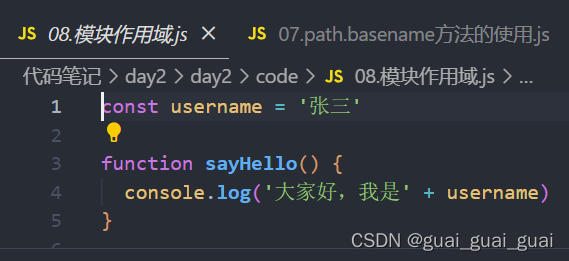
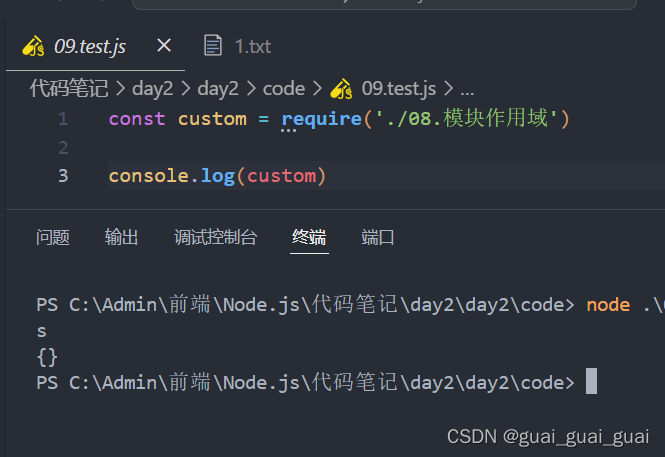
在09中引入08,发下输出custom为空对象,说明不同模块之间变量不可相互访问
向外共享模块作用域中的成员
module对象
每个.js自定义模块中都有一个module对象,他里面存储了和当前模块有关的信息。打印如下:
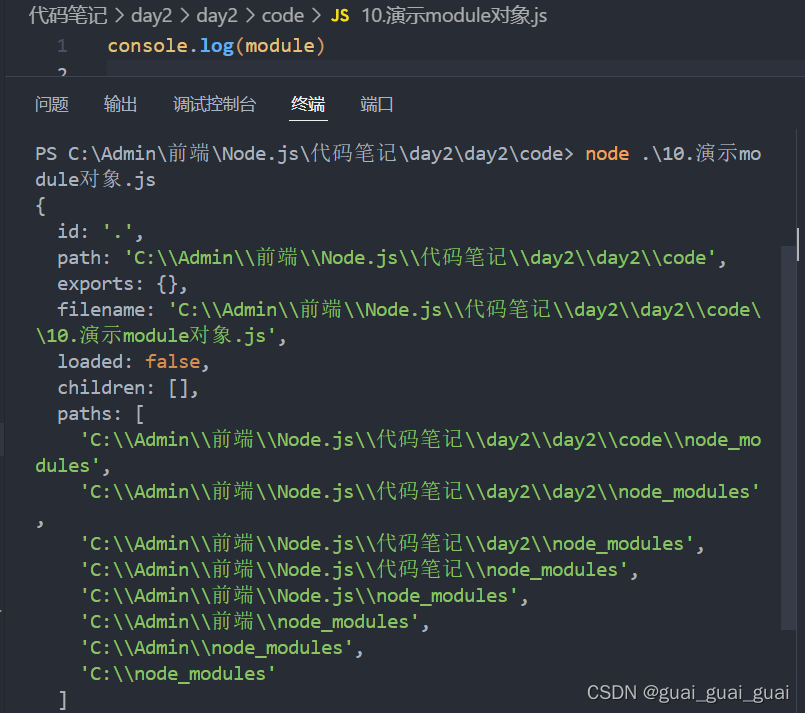
module.exports对象
在自定义模块中,可以使用module.exports对象,将模块内的成员共享出去,供外界使用
外界用require()方法导入自定义模块时,得到的就是mojule.exports所指向的对象
共享require()方法导入模块时,导入的 结果,永远以module.exports指向的对象为准
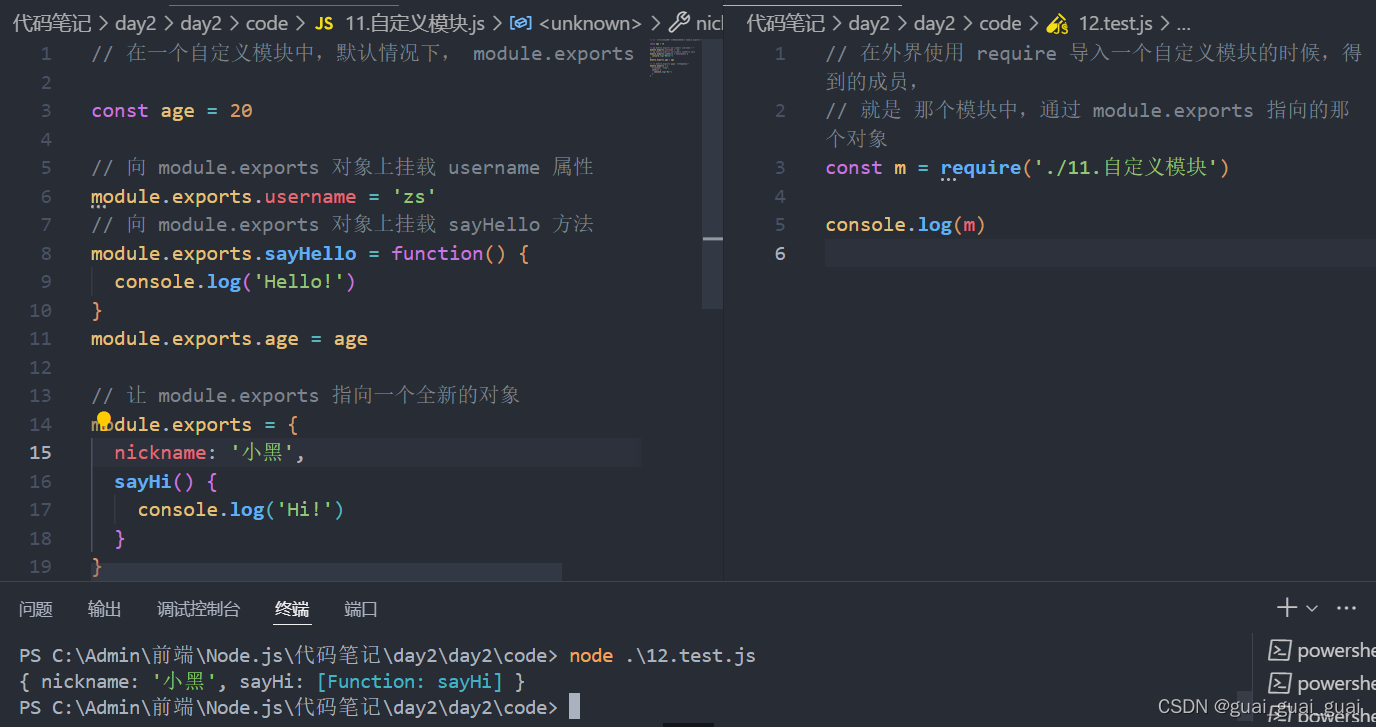 exports对象
exports对象
由于module.exports单词写起来比较复杂,为了简化向外共享成员的代码,Node提供了exports对象,默认情况下,exports和module.exports指向同一个对象,最终共享的结果,还是以module.exportos指向的对象为准。

exports和module.exports的使用误区
时刻谨记,require()模块时,得到的永远是module.exports指向的对象,exports原本是和module.exports指向的地址相同,但若给exports重新赋值,则exports会指向一个新的对象,但是module.exports指向的地址不变,内容也不变,require引入的时候,可以将module.exports中的内容引入,而exports指向的新对象则不hi引入,凡是给exports重新赋值,都会指向一个新的对象
- module.exports可以暴露任意数据
- 不能使用exports=value的形式暴露数据,模块内部module与exports的隐式关系 exports=module.exports={}
注意:为了防止混乱,建议不要在同一个模块中同时使用exports和module.exports
Node.js中的模块化规范
Node.js遵循了CommonJS模块化规范,CommonJS规定了模块的特性和各模块之间如何相互依赖
CommonJS规定:
- 每个模块内部,module变量代表当前模块
- module变量是一个对象,它的exports属性(即module.exports)是对外的接口
- 加载某个模块,其实是加载该模块的module.exports属性,require()方法用于加载模块
module.exports,exports以及require这些都是CommonJS模块化规范中的内容
而Node.js实现了CommonJS模块化规范,二者关系有点像JavaScript与ECMAScript
包
Node.js中的第三方模块又叫做包
就像电脑和计算机指的是相同的东西,第三方模块和包指的是同一个概念,只不过叫法不同
包的来源
不同于Node.js中的内置模块与自定义模块,包是由第三方个人或团队开发出来的,免费供所有人使用
注意:Node.js中的包都是免费且开源的,不需要付费就可免费下载使用
为什么需要包
由于Node.js的内置模块仅提供了一些底层的API,导致在基于内置模块进行项目开发时,效率很低
包是基于内置模块封装出来的,提供了更高级、更方便的API,极大的提高了开发效率
包和内置模块之间的关系,类似于jQuery和浏览器内置API之间的关系
从哪里下载包
国外有一家IT公司,叫做npm,lnc.这家公司旗下有一个非常著名的网站:http://www.npmjs.com/,它是全球最大的包共享平台,你可以从这个网站上搜索到任何你需要的包,只要你有足够的耐心
npm,lnc.公司提供了一个地址为https://registry.npmjs.org/的服务器,来对外共享所有的包,我们可以从这个服务器上下载自己所需的包.
注意:
从http://www.npmjs.com/网站上搜索自己需要的包
从https://registry.npmjs.org/服务器上下载自己需要的包
包的分类
项目包
那些被安装到项目的node_modules目录中的包,都是项目包
项目包又分为两类,分别是:
开发依赖包(被记录到devDependencies节点中的包,只在开发期间会用到)
核心依赖包(被记录到dependencies节点中的包,在开发期间和项目上线之后都会用到)

全局包
在执行npm install命令时,如果提供了-g参数 则会把包安装为全局包
全局包会被安装到C:\Users\用户日录AppData\Roaming\npm\node modules目录下

注意:
- 只有工具性质的包,才有全局安装的必要性,因为它们提供了好用的终端命令
- 判断某个包是否需要全局安装后才能使用,可以参考官方提供的使用说明即可
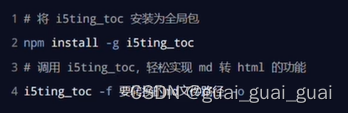
i5ting_toc
i5ting_toc是一个可以把md文档转为html页面的小工具,使用步骤如下:
规范包的结构
一个规范的包,它的组成结构,必须符合以下三点要求:
- 包必须以单独的目录存在
- 包的顶级目录下要必须包含package.json这个包管理配置文件
- package.json中必须包含name,version,main这三个属性,分别代表包的名字,版本号,包的入口
包的初始化
- 创建一个空目录,然后以此目录作为工作目录启动命令行工具,执行npm init
- npm init命令的作用是将文件夹初始化为一个包,交互式创建package.json文件
- package.json是包的配置文件,每个包都必须要有package.json
初始化package.json

- name:包的名字,名字唯一,不可重复
- version:包的版本号
- main:指定包的入口文件,外界resquire导入包导入的就是main属性所指向的文件
- description:包的简短的描述信息,指出包的功能
- keywords:数组,里面包含了检索的字符串
- license:开源许可协议
{
"name": "itheima-tools",
"version": "1.1.0",
"main": "index.js",
"description": "提供了格式化时间、HTMLEscape相关的功能",
"keywords": [
"itheima",
"dateFormat",
"escape"
],
"license": "ISC"
}初始化注意事项:
- package name(包名)不能使用中文,大写,默认值是文件夹的名称,所以文件夹名称也不能使用中文和大写
- version(版本号)要求x.x.x的形式定义,x必须是数字,默认值是1.0.0
- ISC证书与MIT证书功能上是相同的,
- package.json可以手动创建或修改
- 使用npm init -y或者npm init --yes极速创建package.json
搜索包
命令行 npm s/search 关键字
网站搜索 网址为https://www.npmjs.co/
require导入npm包基本流程
- 在当前文件夹下node_modules中寻找同名的文件夹
- 在上级目录中下的node_modules中寻找同名的文件夹,直至找到磁盘根目录
生产环境与开发环境
开发环境是程序员专门用来写代码的环境,一般是指程序员的电脑,开发环境一般只能程序员自己访问
生产环境是项目代码正式运行的环境,一般是指正式的服务器电脑,生产环境的项目一般每个客户都可以访问
生产依赖与开发依赖
我们可以在安装时设置选项来区分依赖的类型,目前分为两类:
| 类型 | 命令 | 补充 |
|---|---|---|
| 生产依赖 | npm i -S uniq npm i --save uniq | -S等效于--save,-S是默认选项 包信息保存在package.json中dependencies属性 |
| 开发依赖 | npm i -D less npm i --save-dev less | -D等效于--save-dev 包信息保存在package.json中,devDependencies属性 |
开发依赖是只在开发阶段使用的依赖包,而生产依赖是开发阶段和最终上线运行阶段都用到的依赖包
全局安装
我们可以执行安装选项-g进行全局安装
npm i -g nodemon全局安装完成之后就可以在命令行的任意位置运行nodemon命令
该命令的作用是自动重启node应用程序
说明:
- 全局安装的命令不受工作目录的影响
- 可以通过npm root -g可以查看全局安装包的位置
- 不是所有的包都适合全局安装,只有全局类的工具才适合,可以通过查看包的官方文档来确定安装方式
npm安装包的所有依赖
在项目协作中有一个常用的命令就是npm i,通过该命令可以依据package.json和package-lock.json的依赖声明安装项目依赖
npm inode_modules文件夹大多数情况都不会存入版本库
安装指定版本的包
项目中可能会遇到版本不匹配的情况,有时就需要安装指定版本的包,可以使用下面的命令
npm i <包名@版本号>
npm i jquery@1.11.2删除依赖
项目中可能需要删除某些不需要的包,可以使用下面命令
// 局部删除
npm remove uniq
npm r uniq
//全局删除
npm remove -g nodemon配置命令别名
通过配置命令别名可以更简单的执行命令
配置package.json中的script属性

配置完成后,可以使用别名执行命令
npm run server
npm run start不过start别名比较特别,使用时可以省略run
npm start
说明
- npm start是项目中常用的一个命令,一般用来启动项目
- npm run有自动向上级目录中查找的特性,跟require函数也一样
- 对于陌生的项目,我们可以通过查看scripts属性来参考项目的一些操作
cnpm使用步骤 (淘宝镜像)

yarn
yarn是由Facebook在2016年推出的JavaScript包管理工具,官方网址:Home page | Yarn
yarn特点
yarn官方宣称的一些特点
- 速度超快:yarn缓存了每个下载过的包,所以再次使用时无需重复下载,同时利用并行下载以最大化资源利用率,因此安装速度更快
- 超级安全:在执行代码之前,yarn会通过算法校验每个安装包的完整性
- 超级可靠:使用详细,简洁的锁文件格式和明确的安装算法,yarn能够保证在不同系统上无差异的工作
yarn常用命令
npm和yarn选择
我们可以根据不同的场景进行选择
- 个人项目
如果是个人项目,哪个工具都可以,
- 公司项目
如果是公司要根据项目代码进行选择,可以通过锁文件判断项目的包管理工具
- npm的锁文件为package-lock.json
- yarn的锁文件为yarn.lock
定义格式化时间的方法
function dateFormat(dateStr) {
const dt = new Date(dateStr)
const y = dt.getFullYear()
const m = padZero(dt.getMonth() + 1)
const d = padZero(dt.getDate())
const hh = padZero(dt.getHours())
const mm = padZero(dt.getMinutes())
const ss = padZero(dt.getSeconds())
return `${y}-${m}-${d} ${hh}:${mm}:${ss}`
}
/ 定义一个补零的函数
function padZero(n) {
return n > 9 ? n : '0' + n
}
module.exports = {
dateFormat
}当require只引入一个文件夹时,会先检查文件夹里面是不是有package.json,会寻找其属性main,自动导入main里包含的文件
在index.js中定义转义HTML的方法
// 定义转义 HTML 字符的函数
function htmlEscape(htmlstr) {
return htmlstr.replace(/<|>|"|&/g, match => {//正则表达式< > " &均符合条件 match即为匹配成功的字符
switch (match) {
case '<':
return '<'
case '>':
return '>'
case '"':
return '"'
case '&':
return '&'
}
})
}
// 定义还原 HTML 字符串的函数
function htmlUnEscape(str) {
return str.replace(/<|>|"|&/g, match => {
switch (match) {
case '<':
return '<'
case '>':
return '>'
case '"':
return '"'
case '&':
return '&'
}
})
}
module.exports = {
htmlEscape,
htmlUnEscape
}
将不同的功能进行模块划分
- 将格式化时间的功能,拆分到src->dateFormat.js中
- 将处理HTML字符串的功能,拆分到src->htmlEcape.js中
- 在index.js中,导入两个模块,得到所需要向外共享的方法
- 在index.js中,使用module.exports把对应的方法共享出去
htmlEscape.js
// 定义转义 HTML 字符的函数
function htmlEscape(htmlstr) {
return htmlstr.replace(/<|>|"|&/g, match => {//正则表达式< > " &均符合条件 match即为匹配成功的字符
switch (match) {
case '<':
return '<'
case '>':
return '>'
case '"':
return '"'
case '&':
return '&'
}
})
}
// 定义还原 HTML 字符串的函数
function htmlUnEscape(str) {
return str.replace(/<|>|"|&/g, match => {
switch (match) {
case '<':
return '<'
case '>':
return '>'
case '"':
return '"'
case '&':
return '&'
}
})
}
module.exports = {
htmlEscape,
htmlUnEscape
}
dateFormat.js
// 定义格式化时间的函数
function dateFormat(dateStr) {
const dt = new Date(dateStr)
const y = dt.getFullYear()
const m = padZero(dt.getMonth() + 1)
const d = padZero(dt.getDate())
const hh = padZero(dt.getHours())
const mm = padZero(dt.getMinutes())
const ss = padZero(dt.getSeconds())
return `${y}-${m}-${d} ${hh}:${mm}:${ss}`
}
// 定义一个补零的函数
function padZero(n) {
return n > 9 ? n : '0' + n
}
module.exports = {
dateFormat
}
index.js
// 这是包的入口文件
const date = require('./src/dateFormat')
const escape = require('./src/htmlEscape')
// 向外暴露需要的成员
module.exports = {
...date,//将date中所有的属性均挂载到这个对象上
...escape
}
编写包的说明文档
- 包根目录中的README.md文件,是包的说明文档,通过它,我们可以事先把包的使用说明,以markdown的格式写出来,方便用户参考
- README文件中具体写什么内容,没有强制性的要求,只要能够清晰的把包的作用,用法,注意事项等描述清楚即可
- 我们所创建的这个包的README.md文档中,会包含以下6项内容:
- 安装方式,导入方式,格式化时间,转义HTML中的特殊字符,还原HTML中的特殊字符、开源协议
## 安装
```
npm install itheima-tools
```
## 导入
```js
const itheima = require('itheima-tools')
```
## 格式化时间
```js
// 调用 dateFormat 对时间进行格式化
const dtStr = itheima.dateFormat(new Date())
// 结果 2020-04-03 17:20:58
console.log(dtStr)
```
## 转义 HTML 中的特殊字符
```js
// 带转换的 HTML 字符串
const htmlStr = '<h1 title="abc">这是h1标签<span>123 </span></h1>'
// 调用 htmlEscape 方法进行转换
const str = itheima.htmlEscape(htmlStr)
// 转换的结果 <h1 title="abc">这是h1标签<span>123&nbsp;</span></h1>
console.log(str)
```
## 还原 HTML 中的特殊字符
```js
// 待还原的 HTML 字符串
const str2 = itheima.htmlUnEscape(str)
// 输出的结果 <h1 title="abc">这是h1标签<span>123 </span></h1>
console.log(str2)
```
## 开源协议
ISC发布包
具体详见08.发布包-把包发布到npm_哔哩哔哩_bilibili
091_包管理工具_npm发布一个包_哔哩哔哩_bilibili
包的管理工具

nvm
nvm全称Node Version Manager顾名思义它是用来管理Node版本的工具,方便切换不同版本的Node.js
下载: https://github.com/coreybutler/nvm-windows/releases
常用命令
| 命令 | 说明 |
|---|---|
| nvm list available | 显示所有可以下载的Node.js版本 |
| nvm list | 显示已安装的版本 |
| nvm install 18.12.1 | 安装18.12.1版本的Node.js |
| nvm install latest | 安装最新版本的Node.js |
| nvm uninstall 18.12.1 | 删除某个版本的Node.js |
| nvm use 18.12.1 | 切换18.12.1的Node.js |
模块的加载机制
优先从缓存中加载
模块在第一次加载后会被缓存,这也意味着多次调用require()不会导致模块的代码被执行多次
注意:不论是内置模块,用户自定义模块,还是第三方模块,他们都会优先从缓存中加载,从而提高模块的加载效率
内置模块的加载机制
内置模块是由Node.js官方提供的模块,内置模块的加载优先级最高
例如,require('fs')始终返回内置的fs模块,即使在node_modules目录名下有名字相同的包(第三方模块)也叫做fs
自定义模块的加载机制
使用require()加载自定义模块时,必须指定以./或../开头的路径标识符,在加载自定义模块时,如果没有指定./或../这样的路径标识符,则node会把它当作内置模块或第三方模块进行加载
同时,在使用require()导入自定义模块时,如果省略了文件的扩展名,则Node.js会按照顺序分别尝试以下的文件:
- 按照确切的文件名进行加载
- 补全.js扩展名进行加载
- 补全.json扩展名进行加载
- 补全.node扩展名进行加载
- 加载失败,终端报错
第三方模块的加载机制
如果传递给 require0 的模块标识符不是一个内置模块,也没有以./或../开头则Node.js 会从当前模块的父级目录开始,尝试从/node_modules 文件夹中加载第三方模块
如果没有找到对应的第三方模块,则移动到再上一层父目录中,进行加载,直到文件系统的根目录
例如,假设在C:\Users\itheimaproject foo,js' 文件里调用了 require(tools),则 Nodejs 会按以下顺序查找:
C:\Users\itheima\project\node modules\tools
C: \Users\itheima\node\modules\tools
C: \Users\node\modules\tools
C: \node\modules\tools
目录作为模块
当把目录作为模块标识符,传递给require()进行加载的时候,有三种加载方式:
- 在被加载的目录下查找一个叫做package.json的文件,并寻找main属性,作为require()加载的入口
- 如果目录里没有package.json文件,或者main入口不存在或无法解析,则Node.js将会试图加载目录下的index.js文件
- 如果以上两步都失败了,则Node.js会在终端打印错误信息,报告模块的缺失:Error:Cannot find module 'xxx'















 909
909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









