







字母表类
一些应用程序可能对字符串的字母表作出限制。在这些应用中,可能常常需要会需要一个API来表示Alphabet类(只是参考,并不会使用该类讨论算法)

public class Alphabet {
/**
* The binary alphabet { 0, 1 }.
*/
public static final Alphabet BINARY = new Alphabet("01");
/**
* The octal alphabet { 0, 1, 2, 3, 4, 5, 6, 7 }.
*/
public static final Alphabet OCTAL = new Alphabet("01234567");
/**
* The decimal alphabet { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 }.
*/
public static final Alphabet DECIMAL = new Alphabet("0123456789");
/**
* The hexadecimal alphabet { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F }.
*/
public static final Alphabet HEXADECIMAL = new Alphabet("0123456789ABCDEF");
/**
* The DNA alphabet { A, C, T, G }.
*/
public static final Alphabet DNA = new Alphabet("ACTG");
/**
* The lowercase alphabet { a, b, c, ..., z }.
*/
public static final Alphabet LOWERCASE = new Alphabet("abcdefghijklmnopqrstuvwxyz");
/**
* The uppercase alphabet { A, B, C, ..., Z }.
*/
public static final Alphabet UPPERCASE = new Alphabet("ABCDEFGHIJKLMNOPQRSTUVWXYZ");
/**
* The protein alphabet { A, C, D, E, F, G, H, I, K, L, M, N, P, Q, R, S, T, V, W, Y }.
*/
public static final Alphabet PROTEIN = new Alphabet("ACDEFGHIKLMNPQRSTVWY");
/**
* The base-64 alphabet (64 characters).
*/
public static final Alphabet BASE64 = new Alphabet("ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/");
/**
* The ASCII alphabet (0-127).
*/
public static final Alphabet ASCII = new Alphabet(128);
/**
* The extended ASCII alphabet (0-255).
*/
public static final Alphabet EXTENDED_ASCII = new Alphabet(256);
public static final Alphabet UNICODE16 = new Alphabet(65536);
private char[] alphabet; // the characters in the alphabet
private int[] inverse; // indices
private int R; // the radix of the alphabet
public Alphabet(String alpha) {
// check that alphabet contains no duplicate chars
boolean[] unicode = new boolean[Character.MAX_VALUE];
for (int i = 0; i < alpha.length(); i++) {
char c = alpha.charAt(i);
if (unicode[c])
throw new IllegalArgumentException("Illegal alphabet: repeated character = '" + c + "'");
unicode[c] = true;
}
alphabet = alpha.toCharArray();
R = alpha.length();
inverse = new int[Character.MAX_VALUE];
for (int i = 0; i < inverse.length; i++)
inverse[i] = -1;
// can't use char since R can be as big as 65,536
for (int c = 0; c < R; c++)
inverse[alphabet[c]] = c;
}
private Alphabet(int R) {
alphabet = new char[R];
inverse = new int[R];
this.R = R;
// can't use char since R can be as big as 65,536
for (int i = 0; i < R; i++)
alphabet[i] = (char) i;
for (int i = 0; i < R; i++)
inverse[i] = i;
}
public Alphabet() {
this(256);
}
public boolean contains(char c) {
return inverse[c] != -1;
}
public int R() {
return R;
}
public int lgR() {
int lgR = 0;
for (int t = R-1; t >= 1; t /= 2)
lgR++;
return lgR;
}
public int toIndex(char c) {
if (c >= inverse.length || inverse[c] == -1) {
throw new IllegalArgumentException("Character " + c + " not in alphabet");
}
return inverse[c];
}
public int[] toIndices(String s) {
char[] source = s.toCharArray();
int[] target = new int[s.length()];
for (int i = 0; i < source.length; i++)
target[i] = toIndex(source[i]);
return target;
}
public char toChar(int index) {
if (index < 0 || index >= R) {
throw new IndexOutOfBoundsException("Alphabet index out of bounds");
}
return alphabet[index];
}
public String toChars(int[] indices) {
StringBuilder s = new StringBuilder(indices.length);
for (int i = 0; i < indices.length; i++)
s.append(toChar(indices[i]));
return s.toString();
}
}字符串排序
索引计数法
输入字符串和字符串对应的组别(组别也是字符串的键),在满足组别有小到大排序的情况下,将字符串按字母顺序排序
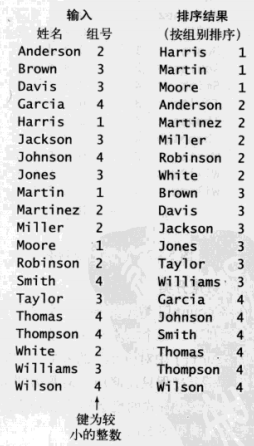
1. 记录组别的频率(为了得到某个字符串在排序后的范围,比如它肯定小于比它组别大的字符串,大于比它组别小的字符串)
cout记录频率,记录的位置是键值+1,加1是方便后期更新键的位置起点。
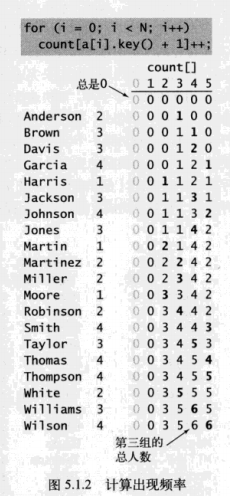
2. 转化为索引(得到每个组别的位置起点)
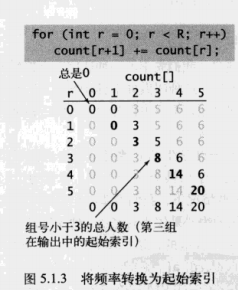
3. 排序、分类
先排序(本例输入是排好的序),排好了再分类(分类是该类有一个元素位置放好了,就把该类别的下限+1,给后面该类的元素放)


索引计数法是稳定的(就排序的稳定性来说)
低位优先排序

结合索引排序,从字符串的低位(从右面开始),从右到左,每个字符都当一次该字符串的键,给整个字符串排序,每一次往高位排,字符串的顺序可能跟之前的不一样了,但整个过程走完,字符串是有序的。(还是稳定性的性质是关键,什么是稳定,就是假如出现了高位时相同的,字符串的顺序肯定也是按次高位排的)
public class LSD {
private static final int BITS_PER_BYTE = 8;
// do not instantiate
private LSD() { }
public static void sort(String[] a, int W) {
int N = a.length;
int R = 256; // extend ASCII alphabet size
String[] aux = new String[N];
for (int d = W-1; d >= 0; d--) {
// sort by key-indexed counting on dth character
// compute frequency counts
int[] count = new int[R+1];
for (int i = 0; i < N; i++)
count[a[i].charAt(d) + 1]++;
// compute cumulates
for (int r = 0; r < R; r++)
count[r+1] += count[r];
// move data
for (int i = 0; i < N; i++)
aux[count[a[i].charAt(d)]++] = a[i];
// copy back
for (int i = 0; i < N; i++)
a[i] = aux[i];
}
}
public static void sort(int[] a) {
int BITS = 32; // each int is 32 bits
int W = BITS / BITS_PER_BYTE; // each int is 4 bytes
int R = 1 << BITS_PER_BYTE; // each bytes is between 0 and 255
int MASK = R - 1; // 0xFF
int N = a.length;
int[] aux = new int[N];
for (int d = 0; d < W; d++) {
// compute frequency counts
int[] count = new int[R+1];
for (int i = 0; i < N; i++) {
int c = (a[i] >> BITS_PER_BYTE*d) & MASK;
count[c + 1]++;
}
// compute cumulates
for (int r = 0; r < R; r++)
count[r+1] += count[r];
// for most significant byte, 0x80-0xFF comes before 0x00-0x7F
if (d == W-1) {
int shift1 = count[R] - count[R/2];
int shift2 = count[R/2];
for (int r = 0; r < R/2; r++)
count[r] += shift1;
for (int r = R/2; r < R; r++)
count[r] -= shift2;
}
// move data
for (int i = 0; i < N; i++) {
int c = (a[i] >> BITS_PER_BYTE*d) & MASK;
aux[count[c]++] = a[i];
}
// copy back
for (int i = 0; i < N; i++)
a[i] = aux[i];
}
}
public static void main(String[] args) {
String[] a = StdIn.readAllStrings();
int N = a.length;
// check that strings have fixed length
int W = a[0].length();
for (int i = 0; i < N; i++)
assert a[i].length() == W : "Strings must have fixed length";
// sort the strings
sort(a, W);
// print results
for (int i = 0; i < N; i++)
StdOut.println(a[i]);
}
}
高位优先字符串排序
在字符串长度不一定相同的情况下,从左至右排序。和上面不同的是,这里排完一个高位,就忽略这个高位,然后对同样的高位再用次高位排序(根据高位切分字符串),一直到最右
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









