







一 论文/方法
1、paper:Amazon.com:Recommendations:Item-to-Item Collaborative Filtering(I to I)
文章归纳了2003年为止的3种推荐系统,并提出一种新的推荐系统
| 名称 | 简介 | 优劣点 | 特点 |
| 协同过滤 | 1、比较用户与用户之间的相似程度。即:A = [Item0,0,……,0,Itemk],B = [Item0,1,……,0,Itemn],如果A和B的余弦值较大,认为A和B相似,维护一个usr to usr的矩阵。 2、排序item,指标为:多少相似的usr买了这款item并进行推荐。 | 随规模增加,伸缩性(Scalability)较差; 可以给用户推荐新产品,很难解释用户为什么喜欢产品。 | 每个向量×一个归一化系数:usr买了n件商品,系数为1/n |
| 基于聚类 | 1、无监督学习把用户分类成若干类。 2、第二步和上述协同过滤相同。 | 伸缩性强于前者;但如果需要好的表现,需要online数据,代价高昂。 | |
| 基于路径 | 如果A用户买了教父的DVD,会(根据作者、艺术家、导演等特征开始推理)把作者的其他作品推荐给他。 | 在数据量小的时候表现好;但无法推测“下一个心头好”,只能推荐已经喜欢过的产品类型 |
作者提出的协同过滤是Item-to-Item的过滤。这种过滤依然是基于COS值,和前者协同过滤相比,这种协同过滤是把A = [usr1,usr2,0,0,0,0……,usrk],B = [usr0,1,0,0,……,usrn],相比用户,这个的向量长度是用户数目,低于协同过滤的向量长度(物品数量)。维护一个item to item的离线矩阵。
比如A产品和B产品相似,用户买过A产品,那么给用户推荐B产品。缺点:无法给用户推荐新产品。

2、KNN(K-nearest neighbor)协同过滤算法
3、Item - based Collaborative Filtering Recommendation Algorithm
文章提出两个指标,两个指标在现实场景中都具有真实的意义。
Prediction-根据每个用户,对item的喜好程度,定义一个矩阵or向量。如,item = [0,4,2,1,....5] 代表usr0对其喜好程度为0,usr1对其喜好程度为4,以此类推。
Recommendation-给每个用户推荐他尚未买过的K件商品。
整个系统分两步骤:
步骤一:计算item相似程度。给了3种计算方法:

法1:直接计算cos值。i和j向量代表所有usr在item_i和item_j的喜好程度,是个Rating score形成的向量。

法2:Ru,i代表第u个用户在第i个产品的喜好程度。这其实也是个cos值的公式,但i向量是原i向量- avg(Ri),j向量是原j向量-avg(Rj)

法3:仍然是cos值公式,i向量是原i向量- avg(Ru),j向量是原j向量-avg(Ru)
步骤二:计算Prediction
提供两种办法:

法1:用户对第i个物品的Prediction计算方法为,(i物品和所有物品的相似程度*所有物品的Rating score)/(i和所有物品的相似程度)
法1是一种加权计算方法,把其他物品的喜好程度按权重加分在本物品上。
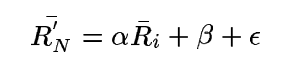
法2:是法1的改进,不再直接使用R_u,N,而是使用法2的公式对R_u,N进行线性回归后计算出数值。α和β是由rating向量确定的参数,e是错误率。
步骤三:真实场景中的模型修正。对每个item,步骤1里similarity是找k个最相似的进行后续计算。
个人思考:可以找K个最相似的,或者按某个阈值找若干个,或者由于数据的问题无法找到合适的推荐。















 366
366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









