







字符串前加 r
"r"的作用是去除转义字符.
即如果是“\n”那么表示一个反斜杠字符,一个字母n,而不是表示换行了。
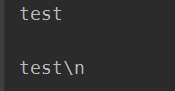
print('test\n')
print(r'test\n')
输出:
字符串前加 f
import time
t0 = time.time()
time.sleep(1)
name = 'processing' # 以 f开头表示在字符串内支持大括号内的python 表达
print(f'{name} done in {time.time() - t0:.2f} s')
输出:
processing done in 1.00 s
字符串前加 b
例: response = b’
Hello World!
’ # b’ ’ 表示这是一个 bytes 对象作用:
b" "前缀表示:后面字符串是bytes 类型。
用处:
网络编程中,服务器和浏览器只认bytes 类型数据。
如:_send 函数的参数和 recv 函数的返回值都是 bytes 类型
字符串前加 u
例:u"我是含有中文字符组成的字符串。"
作用:
后面字符串以 Unicode 格式 进行编码,一般用在中文字符串前面,防止因为源码储存格式问题,导致再次使用时出现乱码。
Python 3中对于bytes 和 str 的互相转换方式(编解码)是 :
str转为bytes:str.encode(‘utf-8’)
bytes转为str:bytes.decode(‘utf-8’)
注意:
使用bytes.decode()的时候可以提示解码错误,那是因为decode所传的编码与bytes类型数据的编码不一致造成的。
我们可以使用chardet模块来查看bytes类型数据的编码,再根据得到的编码类型进行解码,如:
import chardet
bytes_GB2312 = '离离原上草,一岁一枯荣。'.encode('GB2312')
bytes_utf8 = '离离原上草,一岁一枯荣。'.encode('utf-8')
print(bytes_GB2312)
print('所占的字节数:%d' % len(bytes_GB2312))
print(chardet.detect(bytes_GB2312))
# print(bytes_GB2312.decode('utf-8')) # UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc0 in position 0: invalid start byte
print(bytes_GB2312.decode(chardet.detect(bytes_GB2312).get('encoding')))
print('------------------')
print(bytes_utf8)
print('所占的字节数:%d' % len(bytes_utf8))
print(chardet.detect(bytes_utf8))
print(bytes_utf8.decode(chardet.detect(bytes_utf8).get('encoding')))

由chardet.detect()可知,bytes类型字节码的编码类型。
同时,根据len()函数,我们知道:
可见,一个常用汉字用 GB2312/GBK格式编码后占 2 个字节,用 UTF-8 格式编码后占 3 个字节。因为存储或传输时,也用 UTF-8 编码,所以一个汉字占的空间就是 3 个字节。














 570
570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









