







一、环境准备:
1.准备环境
centos 、jdk7(配置环境变量尽量在root/.bashrc,如果配置在/etc/profile或者/root/.bashrc_profile,必须在启动hadoop的时候
需要修改headoop-env.sh添加JAVA_HOME环境变量.,)、其他依赖环境如gcc
2.解压hadoop-2.6.0.tar.gz到usr(我习惯解压到usr下)
3.关闭防火墙(为了做测试用,关闭防火墙)
4.做本机的免密码登录(一定做密码登录,不然Hadoop集群受影响)
生成公私钥对
ssh-keygen -t dsa -P '' -f /root/.ssh/id_dsa
添加信任
cat .ssh/id_dsa.pub >> .ssh/authorized_keys
测试 ssh ip
5.配置本机主机名 在 /etc/hosts配置主机名
192.168.23.20 yecy
映射IP 在 etc/sysconfig/network
HOSTNAME=yecy
6
.配置Hadoop:
①/usr/hadoop-2.6.0/etc/hadoop/core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://主机名:9999</value>
</property>
②/usr/hadoop-2.6.0/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
③/usr/hadoop-2.6.0/etc/hadoop/slaves
将localhost修改为 主机名
7.
格式化hadoop的namenode 只需要在第一次搭建hadoop集群的时候执行
./bin/hdfs namenode -format
作用:是生成namenode所需的fsimage镜像文件 默认/tmp/hadoop-用户名
8.启动、关闭Hadoop
./sbin/start-dfs.sh ./sbin/stop-dfs.sh
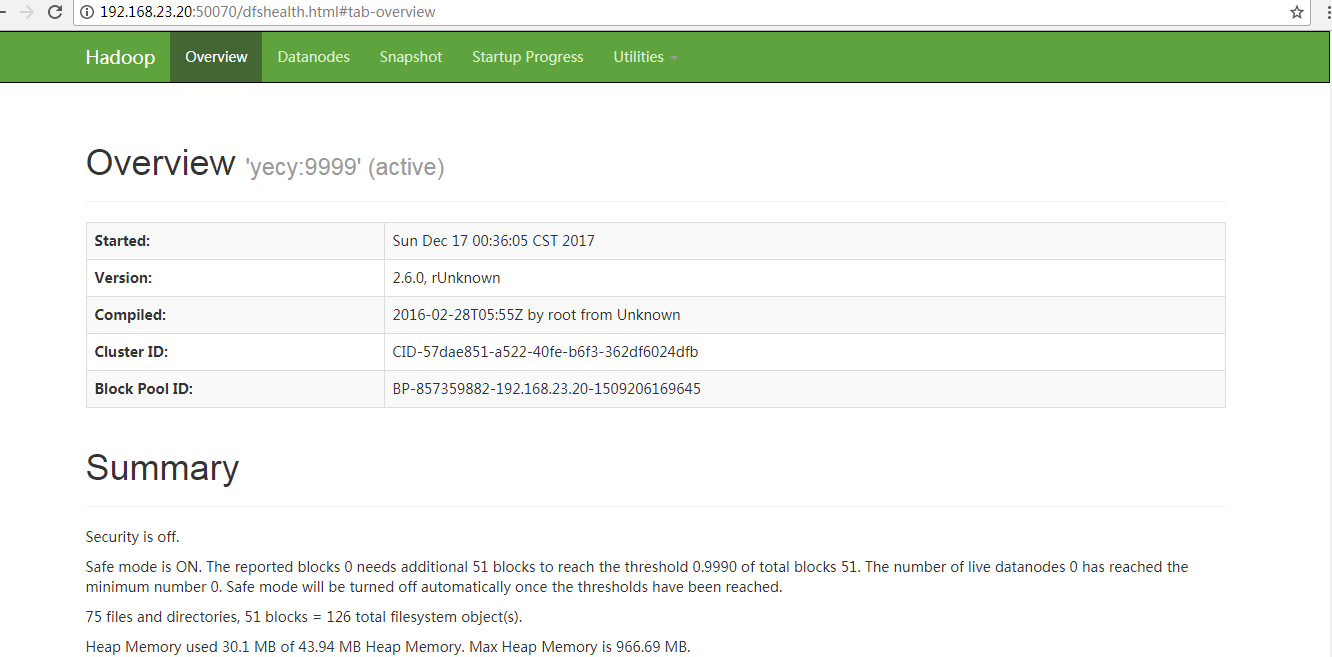
9.启动成功三个线程 jps 或者地址栏 IP:50070
2333 NameNode
2586 SecondaryNameNode
2426 DataNode
2586 SecondaryNameNode
2426 DataNode
问题:
如果以上是Centos32位没什么事,如果是64位,需要在Hadoop安装目录的lib和lib/native添加64位lib包 下载地址
http://dl.bintray.com/sequenceiq/sequenceiq-bin/
(1.)
tar -xvf hadoop-
native
-
64
-
2.7
.
0
.tar -C hadoop-
2.7
.
2
/lib/
native
tar -xvf hadoop-
native
-
64
-
2.7
.
0
.tar -C hadoop-
2.7
.
2
/lib
(2.)改变环境变量
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/
native
export HADOOP_OPTS=
"-Djava.library.path=$HADOOP_HOME/lib"
(3.)环境变量生效
二、基本测试
1.配置Hadoop环境变量:HADOOP_HOME F:\hadoop-2.6.0
2.方便本地开发,需要在IDE工具中引入Hadoop的jar包是common和hdfsj的ar包,分别在解压后的F:\hadoop-2.6.0下的share下Hadoop里边,
3.添加完成自定义jar包后,开始基本的测试,有创建文件夹,删除,上传、下载。可以查看Hadoop官网,
我做一个创建,和上传
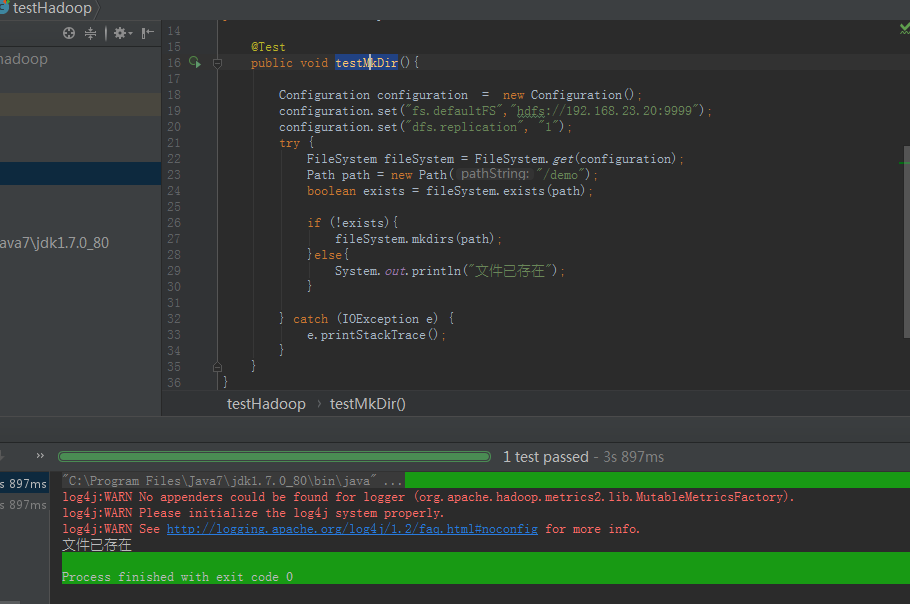
创建并判断是否存在
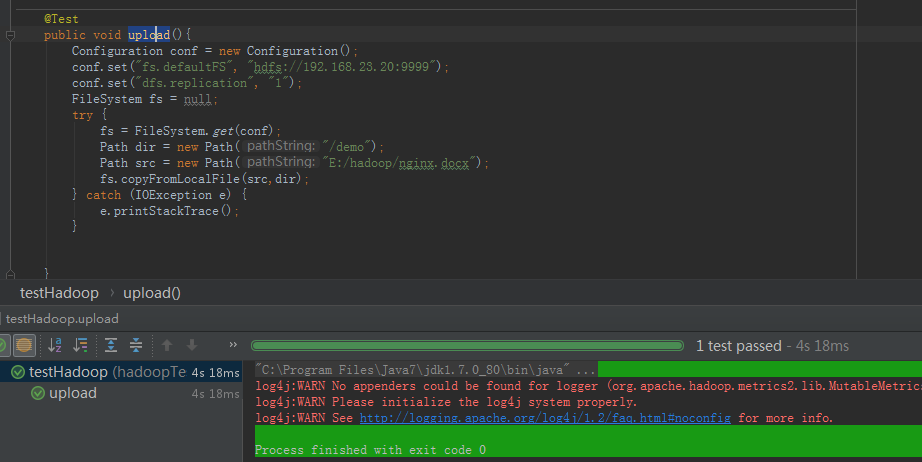
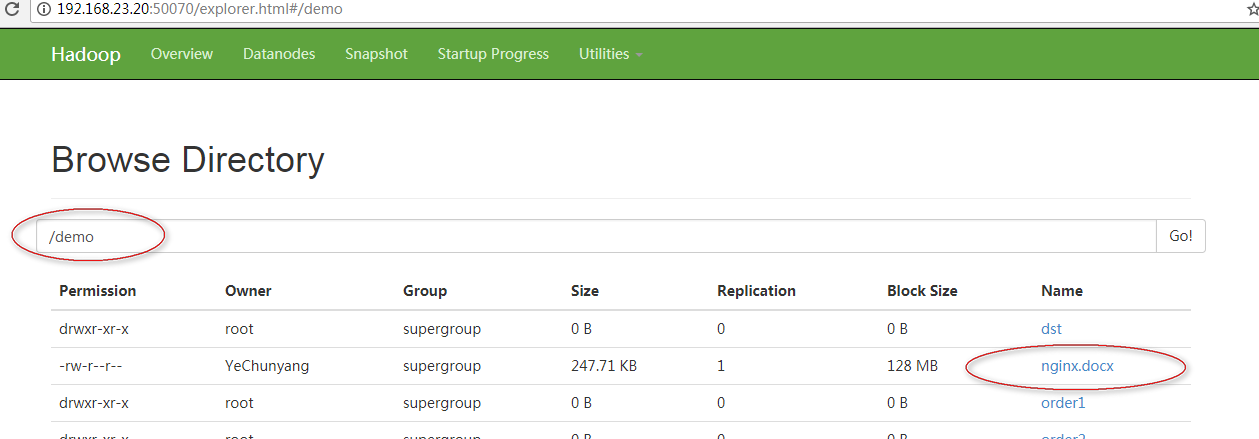
上传
下载只是API不一样,请自行测试,
接下来的篇章会继续Hadoop入门篇章字符统计和求城市温度最大以及联合订单查询!















 136
136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









