







一、前言
在统计计算中,最大期望(EM)算法是在概率模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐藏变量(Latent Variable)。最大期望经常用在机器学习和计算机视觉的数据聚类(Data Clustering)领域。
最大期望算法经过两个步骤交替进行计算,第一步是计算期望(E),利用对隐藏变量的现有估计值,计算其最大似然估计值;第二步是最大化(M),最大化在 E 步上求得的最大似然值来计算参数的值。M步上找到的参数估计值被用于下一个 E 步计算中,这个过程不断交替进行。
其应用在机器学习算法包括KMeans算法、GMM算法等等,通俗来说,是一种参数初始化,不断迭代寻求较优参数的方法。
二、EM算法推导
2.1 对数似然函数
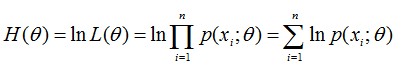
假设我们有一个样本集{x(1),…,x(m)},包含m个独立的样本。但每个样本i对应的类别z(i)是未知的(相当于聚类,联系一下KMeans),也即隐含变量,故我们需要估计概率模型p(x,z)的参数θ,但是由于里面包含隐含变量z,所以很难用最大似然求解。
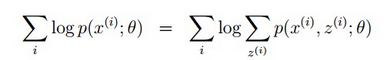
也就是说我们的目标是找到适合的θ和z让L(θ)最大。那我们也许会想,你就是多了一个未知的变量而已啊,我也可以分别对未知的θ和z分别求偏导,再令其等于0,求解出来不也一样吗?本质上这样是可以的,但利用Jensen不等式我们绕开了两个变量求偏导的方式,转而利用通过一个变量最大化函数下界(其实本质也可能是求导)与求一个变量导数相结合的方法。有公式:
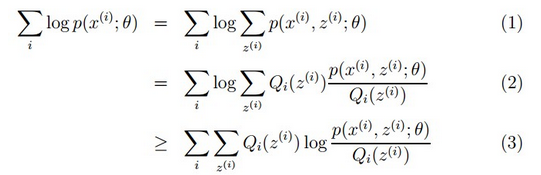
其中(2)式到(3)的转换就是利用了Jensen不等式。
2.2 Jensen不等式
2.2.1 为什么不求偏导
本质上我们是需要最大化(1)式(对(1)式,我们回忆下联合概率密度下某个变量的边缘概率密度函数的求解&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 915
915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









