







TensorFlow 中的自然语言处理 (吴恩达视频)
TensorFlow 中的自然语言处理
【吴恩达团队Tensorflow2.0实践系列课程第三课】TensorFlow2.0中的自然语言处理
这个暑假计划学习NLP,看的是吴恩达老师的视频,已经看到第三课,大家有兴趣的可以看看之前的视频,我觉得讲得非常好。写博客是为了更好的学习,将其中一些细节写下来避免遗忘。
1 简单短例子
Tokenizer是一个用于向量化文本,或将文本转换为序列(即单词在字典中的下标构成的列表,从1算起)的类。
构造参数
- num_words:None或整数,处理最大单词数量。若被设置为整数,则分词器将被限制为待处理数据集中最常见的num_words个单词
- filters:需要滤除的字符的列表或连接形成的字符串,例如标点符号。默认值为 ‘!"#$%&()*+,-./:;<=>?@[]^_`{|}~\t\n’,包含标点符号,制表符和换行符等
- lower:布尔值,是否将序列设为小写形式
- split:字符串,单词的分隔符,如空格
- char_level:如果为True,每个字符将被视为一个标记
- oov_token :如果给出,会添加到词索引中,用来替换超出词表的字符。
类方法
- fit_on_texts(texts)
- texts:要用以训练的文本序列
- texts_to_sequences(texts)
- texts:待转为序列的文本列表
- 返回值:序列的列表,列表中每个序列对应于一段输入文本
- fit_on_sequences(sequences)
- sequences:要用以训练的序列列表
- sequences_to_matrix(sequences)
- sequences:待向量化的序列列表
- mode:‘binary’,‘count’,‘tfidf’,‘freq’之一,默认为’binary’
- 返回值:形如(len(sequences), nb_words)的numpy array
属性
- word_counts:字典,将单词(字符串)映射为它们在训练期间出现的次数。仅在调用fit_on_texts之后设置。
- word_docs: 字典,将单词(字符串)映射为它们在训练期间所出现的文档或文本的数量。仅在调用fit_on_texts之后设置。
- word_index: 字典,将单词(字符串)映射为它们的排名或者索引。仅在调用fit_on_texts之后设置。
- document_count: 整数。分词器被训练的文档(文本或者序列)数量。仅在调用fit_on_texts或fit_on_sequences之后设置
代码
import tensorflow as tf
from tensorflow import keras
from keras.preprocessing.text import Tokenizer
sentences = [
'I love my dog',
'I love my cat',
'You love my dog! '
]
tokenizer = Tokenizer(num_words = 100,
filters='!"#$%&()*+,-./:;<=>?@[]^_`{|}~tn',
lower=True,
split=' ',
oov_token='<00f>',
char_level=False)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(word_index)
输出:
{'love': 1, 'my': 2, 'i': 3, 'dog': 4, 'ca': 5, 'you': 6}
我的理解:
将文本中每个词进行编码,然后每个词就有唯一一个索引,这个文本就转换为了数字。
2 tensorflow.keras实现IMDB情感分类实战
数据文件下载
口令:hygu9z
2.1 数据准备
import numpy as np
import tensorflow as tf
import tensorflow.keras as keras
import os
origin_dir = 'E:\\黑马课程\\数据集'
train_dir = origin_dir + '\\aclImdb\\train'
test_dir = origin_dir + '\\aclImdb\\test'
texts = []
labels = []
for fname in os.listdir(train_dir+'\\neg'):
with open(train_dir+'\\neg\\'+fname,'r',encoding='utf8') as f:
texts.append(f.read())
labels.append(0)
for fname in os.listdir(train_dir+'\\pos'):
with open(train_dir+'\\pos\\'+fname,'r',encoding='utf8') as f:
texts.append(f.read())
labels.append(1)
from sklearn.model_selection import train_test_split
training_sentences,testing_sentences, training_labels,testing_labels = train_test_split(texts,labels, test_size=0.2)
2.2 数据预处理
分词与编码:用 keras.preprocessing.text.Tokenizer 匹配文本 texts. 再用 tokenizer 将文本列表转化为数字列表 sequences(列表中的每个元素都是由整数构成的列表)。
word_index 是将单词对应到整数的字典:{‘the’:1, ‘and’:2, ‘a’:3, … }
再用 keras.preprocessing.pad_sequences 将列表中每个元素都变成长为 200的整数列表。 返回值是 ndarray,形状为 (25000,200)
vocab_size = 10000 #每个评论加载的最大数据
max_length = 200
trunc_type='post'
oov_tok = "<OOV>"
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer(num_words = vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(training_sentences)
# 填充或者截断评论
padded = pad_sequences(sequences,maxlen=max_length, truncating=trunc_type)
testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences,maxlen=max_length)
# 将键值对换,数字标识在前
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
# 查看处理后的数据和之前的数据
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
2.3 模型训练
简单地建立一个Sequential模型,由三层构成:Embedding,Flatten , Dense.
模型输入参数形状是 (batch_size, 200),表示由 batch_size 个长度200的整数向量构成。
Embedding层的设定参数是(10000,16),表示将10000个整数映射到10000个长度为16的向量。
Flatten将向量转换为一维
Dense全连接层用sigmoid激活函数输出一个值,将其二分类。
训练模型10个epoch,batch_size=32
embedding_dim = 16
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
model.summary()
# 转换数据,放入模型训练
training_labels_final = np.array(training_labels)
testing_labels_final = np.array(testing_labels)
num_epochs = 10
model.fit(padded, training_labels_final, epochs=num_epochs, validation_data=(testing_padded, testing_labels_final))
2.4 可视化训练效果
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
plt.plot(np.arange(1,len(acc)+1), acc)
plt.plot(np.arange(1,len(acc)+1), val_acc)
plt.legend(['acc','val_acc'])
plt.title('Accuracy (Non-pretrained embedding & LSTM)')
plt.figure()
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(np.arange(1,len(loss)+1), loss)
plt.plot(np.arange(1,len(val_loss)+1), val_loss)
plt.legend(['loss','val_loss'])
plt.title('Loss (Non-pretrained embedding & LSTM)')
plt.show()
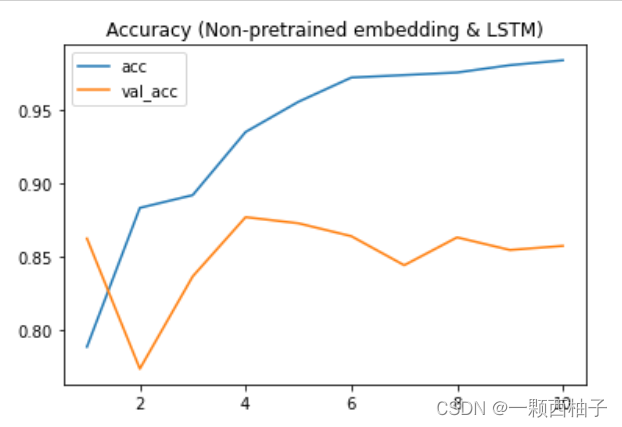
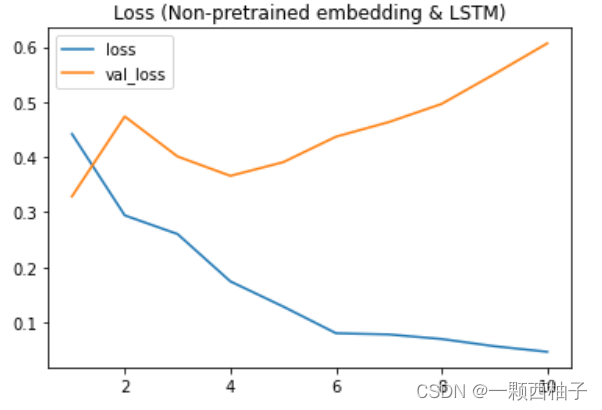
2.5 结果预测
预测测试集中前10个,如果需要预测新的文本,需要处理格式为向量
print(model.predict(testing_padded[:10]))















 6941
6941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









