






1、XPath
XPath的选择功能十分强大,它提供了非常简洁明了的路径选择表达式。另外,它还提供了超过100个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等。几乎所有我们想要定位的节点,都可以用XPath来选择。
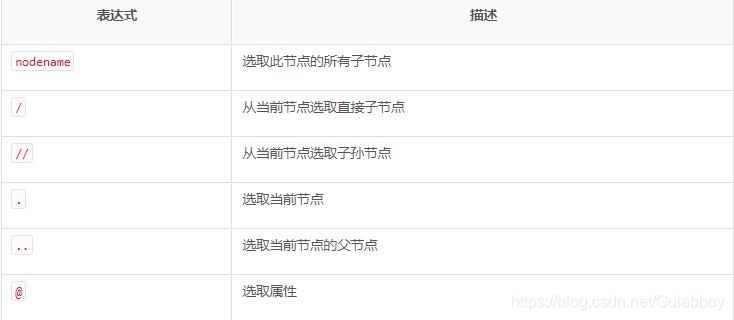
2、XPath常用规则
3、实战
from lxml import etree
import requests
def get_html(url, headers):
response = requests.get(url, headers = headers)
try:
if response.status_code == 200:
return response.text
except:
pass
def get_parse(html):
tree = etree.HTML(html)
user = tree.xpath('//*/table/tbody/tr/td/div/a/text()')
reply = tree.xpath('//*/table/tbody/tr/td/div/div/table/tbody/tr/td/text()')
for users, replys in zip(user, reply):
print('用户名:'+users, '回复内容:'+ replys.strip())
def main():
url = 'http://www.dxy.cn/bbs/thread/626626'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
}
html = get_html(url, headers)
get_parse(html)
if __name__ == '__main__':
main()
输出结果:

参考资料:
https://cuiqingcai.com/5545.html
https://blog.csdn.net/gaifuxi9518/article/details/80859116
https://blog.csdn.net/asdfqwersdv3we/article/details/88124401














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









