







 本文介绍BeautifulSoup库中的四大核心对象——Tag、NavigableString、BeautifulSoup和Comment,以及如何通过它们解析和操作HTML文档。通过示例展示了获取Tag的name和attrs属性,以及对内容和属性的修改操作。还提到了NavigableString对象用于获取标签内的文本,以及处理Comment对象的注意事项。
本文介绍BeautifulSoup库中的四大核心对象——Tag、NavigableString、BeautifulSoup和Comment,以及如何通过它们解析和操作HTML文档。通过示例展示了获取Tag的name和attrs属性,以及对内容和属性的修改操作。还提到了NavigableString对象用于获取标签内的文本,以及处理Comment对象的注意事项。
四大对象种类
BeautifulSoup将复杂HTML文档转换成一个复杂的树形结构。如图所示
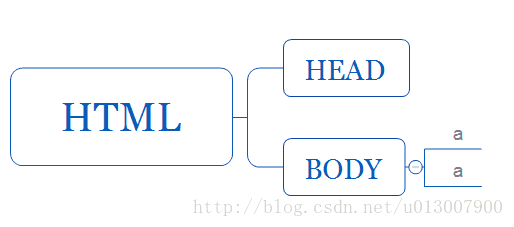
每个节点都是Python对象,我们只用根据节点进行查询就可以了,因为解析工作交给了框架本身。所有对象可以归纳为4种:
- Tag
- NavigableString
- BeautifulSoup
- Comment
Tag
什么是Tag,举几个例子
<title>The Dormouse's story</title>
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>上面的title a 等等 HTML 标签加上里面包括的内容就是 Tag。
在前几次的文章中,我们就是通过Tag来获取信息的。
如获得标签<title>
print soup.title
#<title>The Dormouse's story</title>我们可以利用 bs4加标签名轻松地获取这些标签的内容,比用正则表达式求方便很多。
不过有一点是,它查找的是在所有内容中的第一个符合要求的标签,如果要查询所有的标签,则需要使用find()和find_all()(findAll())这两个函数,后面两个函数在目前的代码中来看功能和语法是一样的,如果后期有什么区别,我会再返回来讲的。
for item in soup.findAll('a'):
print item,'\n'
print soup.find('a')
print soup.find_all('a', limit = 1)[0]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3619
3619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









