







# -*- coding:utf-8 -*-
import requests
from lxml import etree
import os1.获取网页,通过requests工具包实现(集成环境自带)
如果没有就手动安装 pip install requestsurl = "http://www.ivsky.com/tupian/ziranfengguang/"
response = requests.get(url)# 200 表示成功/ok
# 404 资源不存在
# 500 服务器错误
print(response.content) # bytes类型----open("1.html","wb")# r=read
# w=write
# a=append
# wb=writebytes
f = open("1.html", "wb")
f.write(response.content)
f.close()2.解析网页 引入lxml工具包
root = etree.HTML(response.content)
a_list = root.xpath("//ul[@class='tpmenu']/li/a")
# 缺点:会破坏列表中的数据
# a_list.pop(0)
# a_list.remove("所有分类")
3.文件夹操作
绝对路径 c:/desktop/phone
# 相对路径 相对于当前文件所在路径
for a in a_list[1:]:
title = a.xpath("text()")[0]
# print(title)
url1 = "http://www.ivsky.com" + a.xpath("@href")[0]
# print(url1)
# 3.文件夹操作,导入os 模块,OperationSystem(操作系统)
# os.makedirs("文件夹路径")
# 绝对路径 c:/desktop/phone
# 相对路径 相对于当前文件所在路径
# if not os.path.exists("imgs/"+title):
# os.makedirs("imgs/"+title)
res = requests.get(url1)
# print(res.content)
root1 = etree.HTML(res.content)
b_list = root1.xpath("//div[@class='sline']/div/a")
for b in b_list[1:]:
title1 = b.xpath("text()")[0]
# print(title1)
if not os.path.exists("imgs/" + title + "/" + title1):
os.makedirs("imgs/" + title + "/" + title1)
完整代码:
# -*- coding:utf-8 -*-
import requests
from lxml import etree
import os
# 1.获取网页,通过requests工具包实现(集成环境自带)
# 如果没有就手动安装 pip install requests
url = "http://www.ivsky.com/tupian/ziranfengguang/"
response = requests.get(url)
# 响应码/状态码
# 200 表示成功/ok
# 404 资源不存在
# 500 服务器错误
print(response.content) # bytes类型----open("1.html","wb")
# print(response.text) # 字符串类型----open("1.html","w")
# r=read
# w=write
# a=append
# wb=writebytes
f = open("1.html", "wb")
f.write(response.content)
f.close()
# 2.解析网页 引入lxml工具包
root = etree.HTML(response.content)
a_list = root.xpath("//ul[@class='tpmenu']/li/a")
# 缺点:会破坏列表中的数据
# a_list.pop(0)
# a_list.remove("所有分类")
for a in a_list[1:]:
title = a.xpath("text()")[0]
# print(title)
url1 = "http://www.ivsky.com" + a.xpath("@href")[0]
# print(url1)
# 3.文件夹操作,导入os 模块,OperationSystem(操作系统)
# os.makedirs("文件夹路径")
# 绝对路径 c:/desktop/phone
# 相对路径 相对于当前文件所在路径
# if not os.path.exists("imgs/"+title):
# os.makedirs("imgs/"+title)
res = requests.get(url1)
# print(res.content)
root1 = etree.HTML(res.content)
b_list = root1.xpath("//div[@class='sline']/div/a")
for b in b_list[1:]:
title1 = b.xpath("text()")[0]
# print(title1)
if not os.path.exists("imgs/" + title + "/" + title1):
os.makedirs("imgs/" + title + "/" + title1)运行结果:
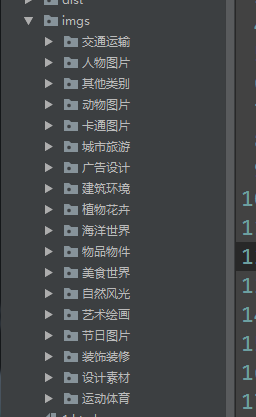
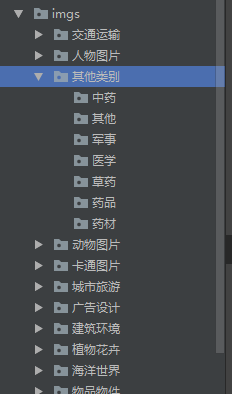
第二部分:下载图片
完整代码;
# -*- coding:utf-8 -*-
import requests
url = "http://img.ivsky.com/img/tupian/pre/201711/30/hangpai-004.jpg"
res1 = requests.get(url)
f = open("2.jpg", "wb")
f.write(res1.content)
f.close()
运行结果:
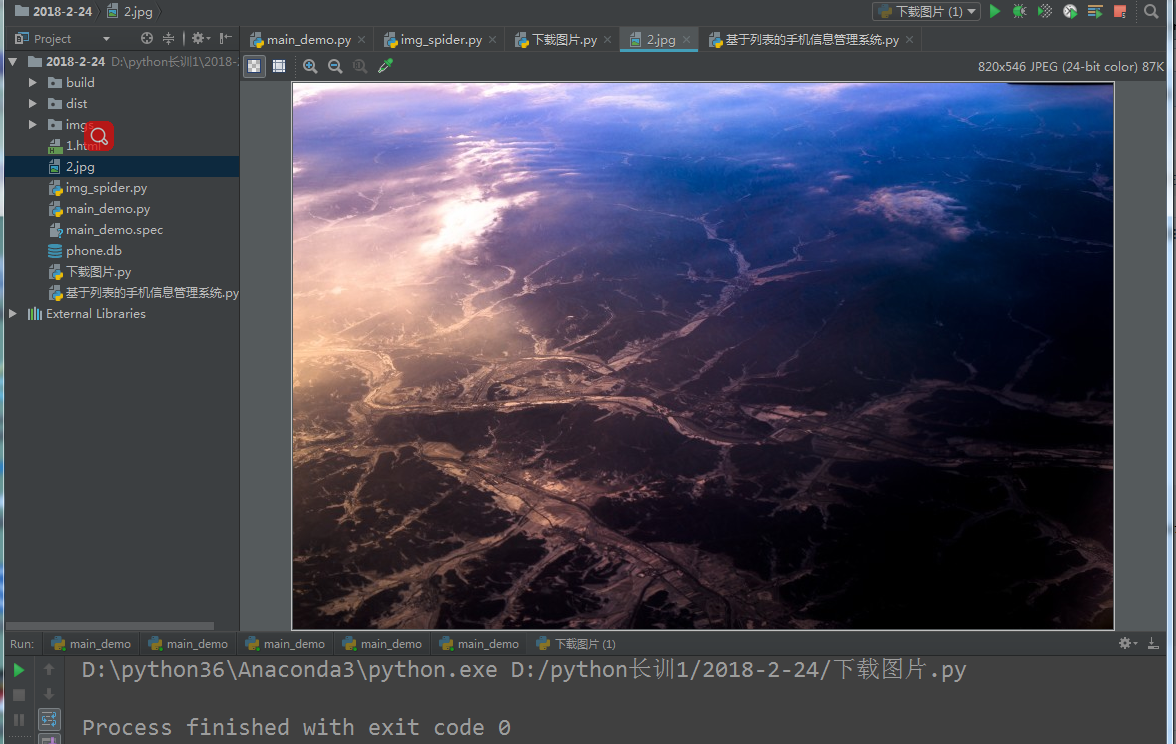















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









