







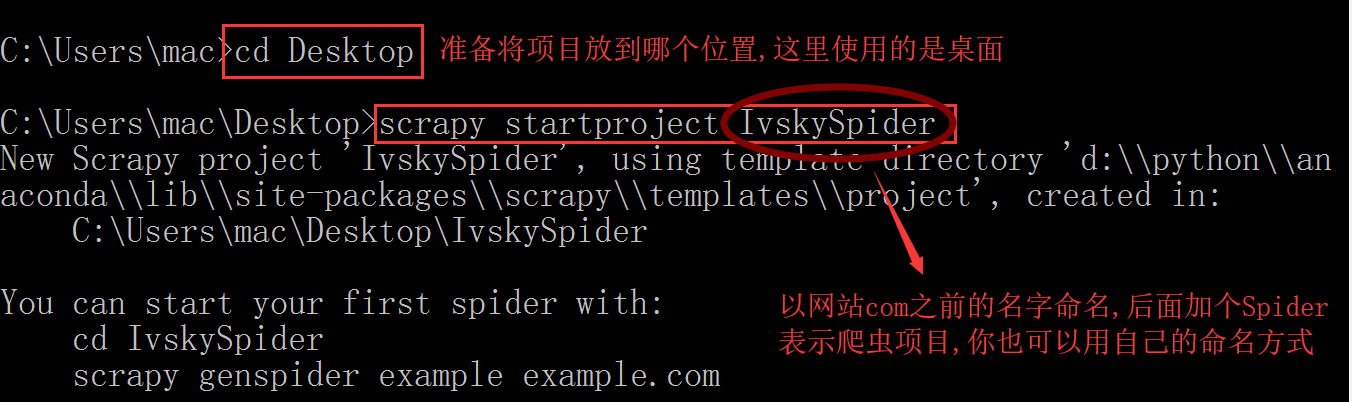
1.第一步:创建爬虫项目
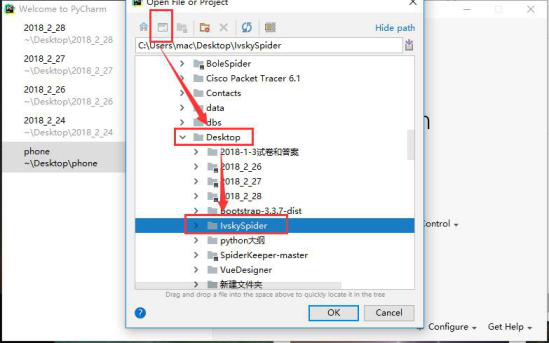
2.使用pycharm打开爬虫项目
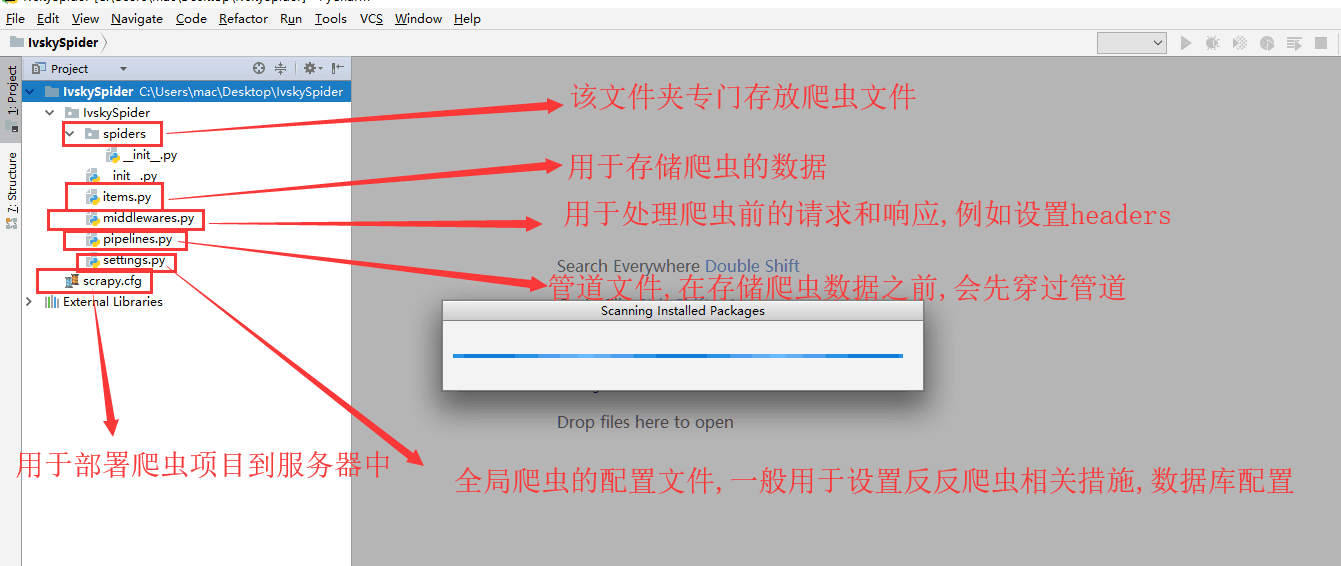
打开结果如下(目录结构):
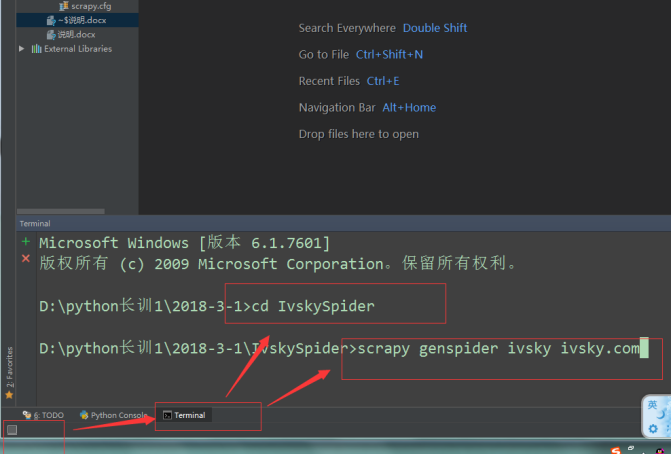
3.第三步:创建爬虫
说明:在ivskyspider文件中创建,所以需要先进入ivskyspider
说明:一个项目可以创建多个爬虫文件
4.第四步:打开新建的爬虫文件ivsky.py
文件结构如下:
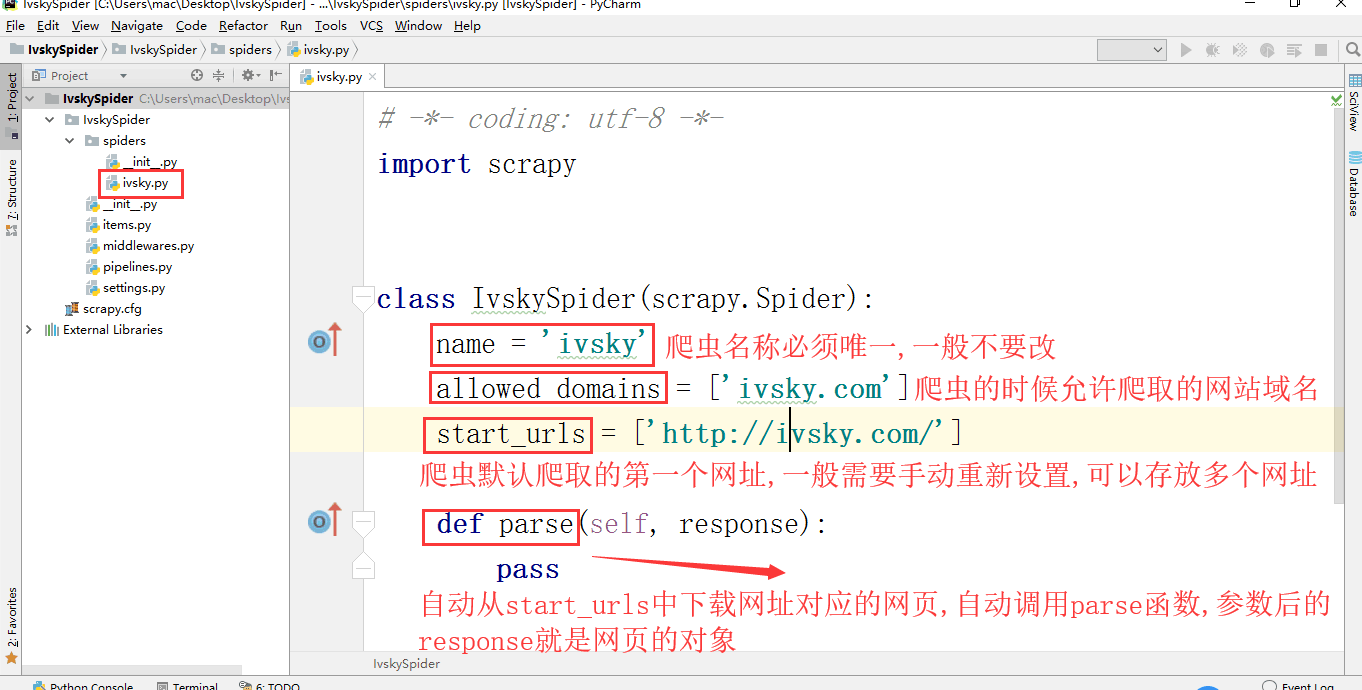
5.
执行代码:
方法一:
打开Teminal
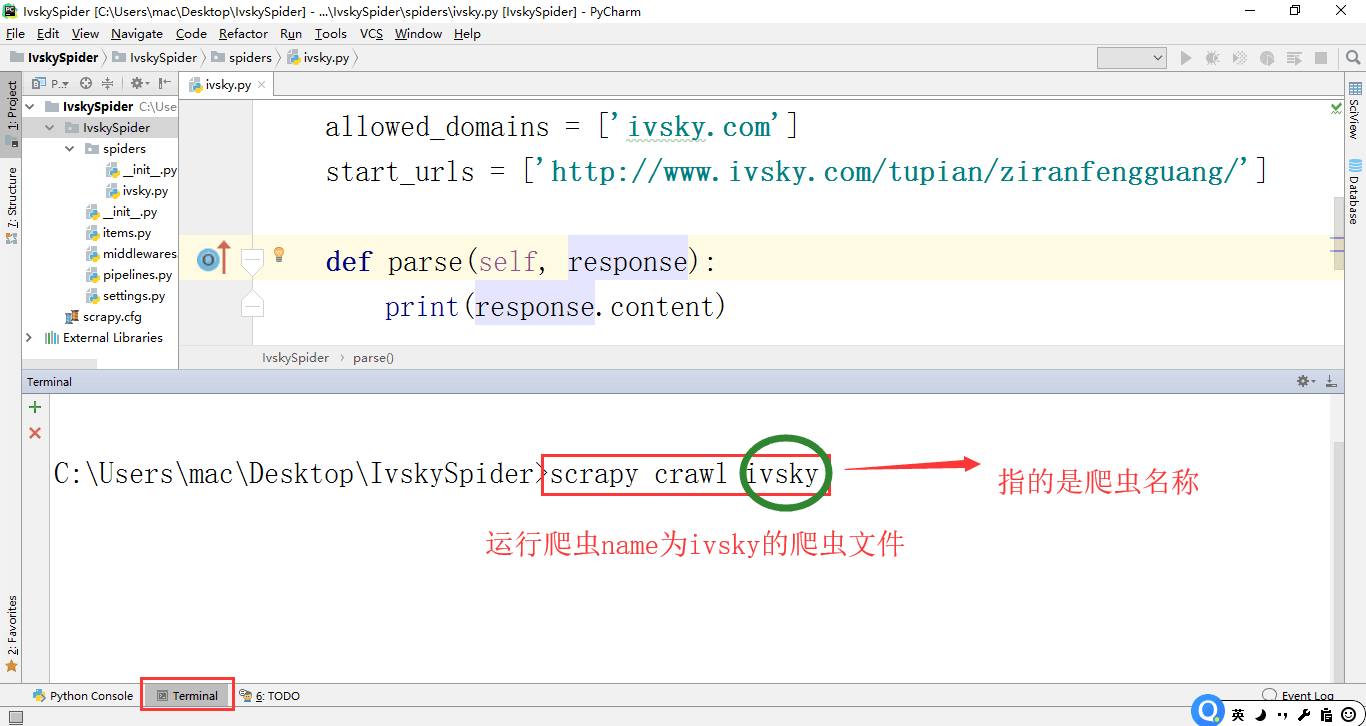
方法二:
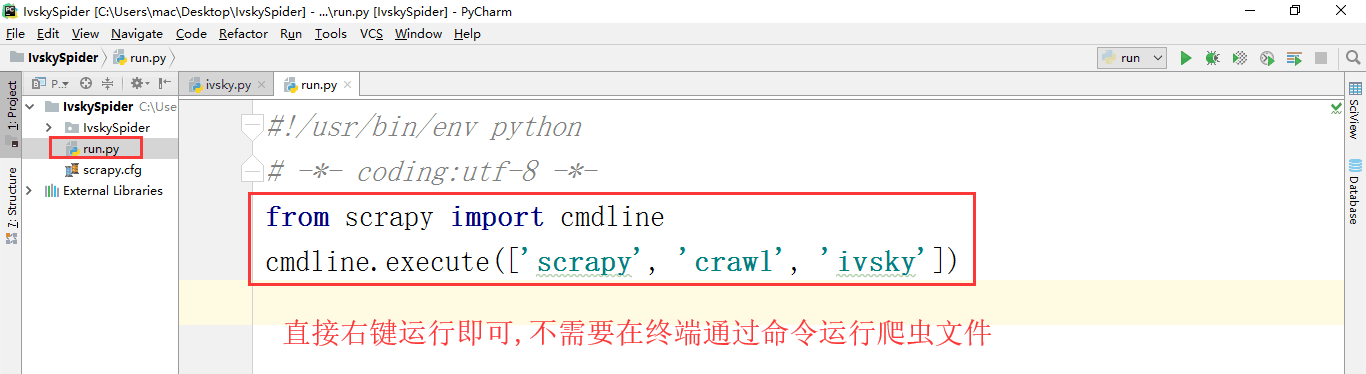
在第一个IvskySpider的位置新建文件
不想在终端运行程序时,先新建此文件,然后运行
from scrapy import cmdline
cmdline.execute(['scrapy', 'crawl', 'ivsky'])
爬取数据:
scrapy的基本用法
1. 通过命令创建项目
scrapy startproject 项目名称
2. 用pycharm打开项目
3. 通过命令创建爬虫
scrapy genspider 爬虫名称 域名
4. 配置settings
robots_obey=False
Download_delay=0.5
Cookie_enable=False
5. 自定义UserAgentMiddleWare
可以直接粘现成的
或者自己通过研究源码实现
6. 开始解析数据
1) 先大致规划一下需要几个函数
2) 函数1跳转到函数2使用 yield scrapy.Request(url,callback,meta,dont_filter)
7. 将数据封装到items,记得yield item
8. 自定义pipelines将数据存储到数据库/文件中
1. 通过命令创建项目
scrapy startproject 项目名称
2. 用pycharm打开项目
3. 通过命令创建爬虫
scrapy genspider 爬虫名称 域名
4. 配置settings
robots_obey=False
Download_delay=0.5
Cookie_enable=False
5. 自定义UserAgentMiddleWare
可以直接粘现成的
或者自己通过研究源码实现
6. 开始解析数据
1) 先大致规划一下需要几个函数
2) 函数1跳转到函数2使用 yield scrapy.Request(url,callback,meta,dont_filter)
7. 将数据封装到items,记得yield item
8. 自定义pipelines将数据存储到数据库/文件中















 1203
1203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









