






1,下载kafka
kafka_2.12-3.0 版本
2,下载zookeeper
apache-zookeeper-3.5.9 版本
3,解压zookeeper
tar -zxvf zpache-zookeeper
然后保存退出配置环境变量
vi /etc/profile
4,存放路径
export ZOOKEEPER_INSTALL=/root/zookeeper/
export PATH=$PATH:$ZOOKEEPER_INSTALL/bin
5,立即生效
source /etc/profile
6,修改zookeeper配置文件
cd /zookeeper/conf/zoo......cfg
这里要改为
mv zoo-....cfg zoo.cfg 改名
7,在修改配置文件 vi zoo.cfg
这两个必须加上,没有路径mkdir新建data log就行了
dataDir=/tmp/zookeeper/data
dataLogDir=/tmp/zookeeper/log
8,最后启动,来到bin/目录下的
./zkServer.sh start
查看是否安装成功
jps
9,yum安装jdk快速安装配置
yum install -y java-1.8.0-openjdk-devel.x86_64
10.关闭防火墙
systemctl stop firewalld
11,解压kafka
tar -zxvf kafka_2.12-3.0
12,进入到kafka的配置文件
cd kafka/conf/
# 超级重要允许外部访问的-----这是线上的配置-------------第一种配置----------------
# 阿里云私网ip
listeners=PLAINTEXT://172.22.239.137:9092
# 阿里云公网ip
advertised.host.name=8.135.54.87
# 阿里云私网ip
host.name=172.22.239.137
# 映射端口
prot=9092
# 底部的zookeeper 配置
zookeeper.connect=172.22.239.137:2181
# 超级重要允许外部访问的-----这是本地虚拟机的配置-------------第二种配置----------------
这里的ip地址均为虚拟机ip地址,不可变动
# 阿里云私网ip
listeners=PLAINTEXT://172.22.239.137:9092
# 底部的zookeeper 配置
zookeeper.connect=172.22.239.137:2181
13,全局启动kafka
./kafka-server-start.sh -daemon ../config/server.properties
14,启动成功后创建对应的主体/生产者/消费者
高版本kafka创建主体---------
./kafka/bin/kafka-topics.sh --create --bootstrap-server 192.168.1.158:9092 --replication-factor 1 --partitions 1 --topic stationTopic
./kafka/bin/kafka-topics.sh --create --bootstrap-server 192.168.1.158:9092 --replication-factor 1 --partitions 1 --topic etlTopic
创建生产者---------------------------------------------------------------------------
#模拟生产者
./kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic stationTopic
./kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic etlTopic
创建消费者…
#模拟消费者
./kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.1.158:9092 --topic stationTopic --from-beginning
./kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.1.158:9092 --topic etlTopic --from-beginning
windows开发配置spark3.0
1,这里3.0 3.2都可以对应配置hadoop的环境变量
spark-3.2.0-bin-hadoop3.2
spark下载地址
http://spark.apache.org/downloads.html
hadoop下载地址
https://hadoop.apache.org/releases.html
https://dlcdn.apache.org/hadoop/common/hadoop-3.2.2/hadoop-3.2.2-src.tar.gz
2,hadoop必须下载的文件,因为这是linux的解压文件没有windows启动命令,所以需要下载
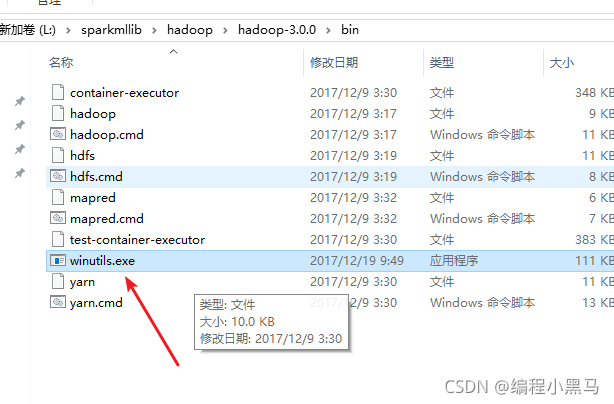
下载地址
hadoop.dll文件下载地址:
链接:https://pan.baidu.com/s/1Rb5ROUQMSqp7SeQINlLZkA 提取码:n8t6
3,spark和hadoop文件配置在windos环境变量中

4,下载scalasdk并配置环境变量
下载地址
https://get-coursier.io/docs/cli-installation
打开后滑动到最底部下载对应的版本 windows linxu mac.........
下载完后配置环境变量,同上spark hadoop
5,打开idea编辑器,选择所用版本,

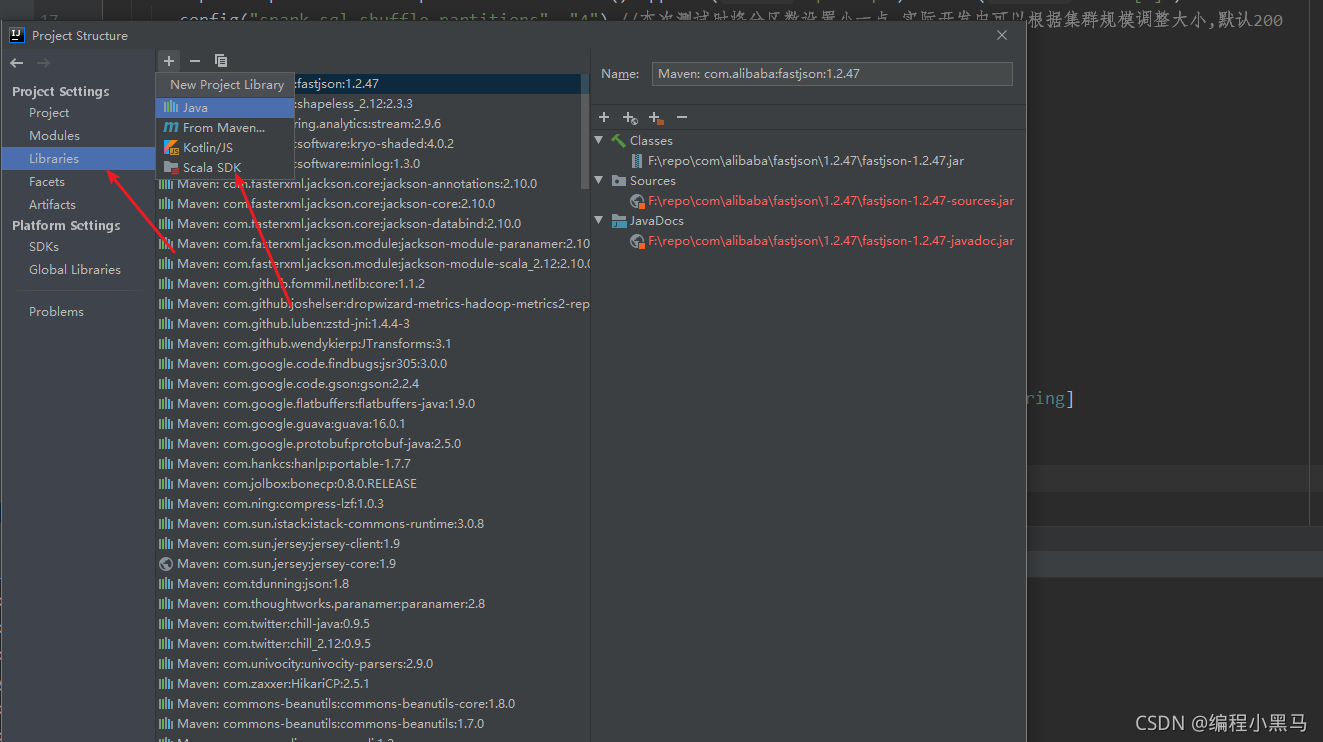
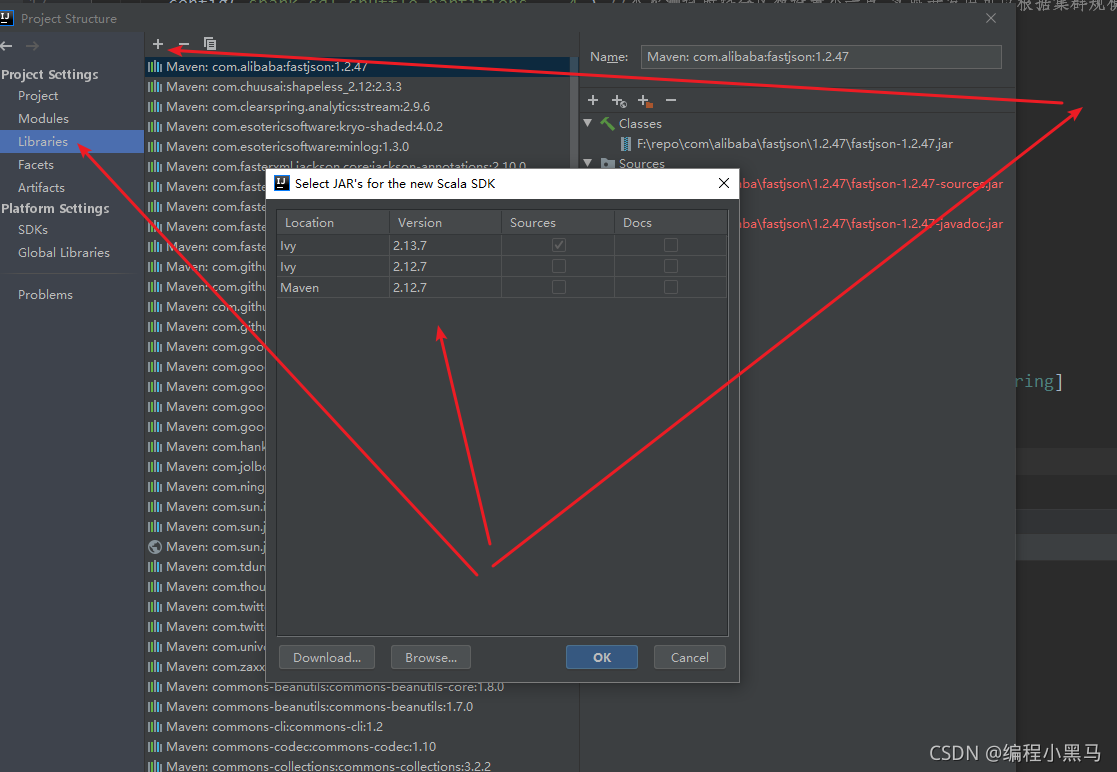
6,新建maven环境并导入依赖
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>apache</id>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<properties>
<encoding>UTF-8</encoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<scala.version>2.12.11</scala.version>
<spark.version>3.0.1</spark.version>
<hadoop.version>2.7.5</hadoop.version>
</properties>
<dependencies>
<!--依赖Scala语言-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!--SparkCore依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- spark-streaming-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!--spark-streaming+Kafka依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!--SparkSQL依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!--SparkSQL+ Hive依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive-thriftserver_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!--StructuredStreaming+Kafka依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- SparkMlLib机器学习模块,里面有ALS推荐算法-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.7</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.2</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<!-- 指定编译java的插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
</plugin>
<!-- 指定编译scala的插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
7,修改maven 的地址,以及setting.xml 以及repo包存放路径
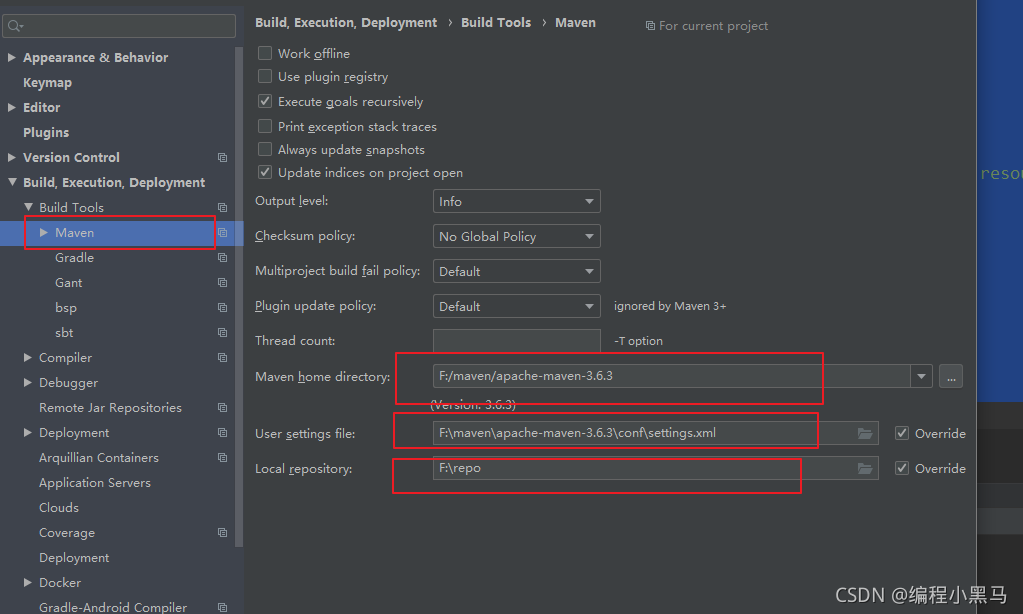
8,创建一个scala模拟数据文件
MockStationLog
stationTopic是在linux创建的主题,是往kafka里面发的
bootstrap.servers 对应是kafka的路径
package cn.itcast.structured
import java.util.Properties
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializer
import scala.util.Random
/**
* 模拟产生基站日志数据,实时发送Kafka Topic中
* 数据字段信息:
* 基站标识符ID, 主叫号码, 被叫号码, 通话状态, 通话时间,通话时长
*/
object MockStationLog {
def main(args: Array[String]): Unit = {
// 发送Kafka Topic
val props = new Properties()
props.put("bootstrap.servers", "192.168.1.158:9092")
props.put("acks", "1")
props.put("retries", "3")
props.put("key.serializer", classOf[StringSerializer].getName)
props.put("value.serializer", classOf[StringSerializer].getName)
val producer = new KafkaProducer[String, String](props)
val random = new Random()
val allStatus = Array(
"fail", "busy", "barring", "success", "success", "success",
"success", "success", "success", "success", "success", "success"
)
while (true) {
val callOut: String = "1860000%04d".format(random.nextInt(10000))
val callIn: String = "1890000%04d".format(random.nextInt(10000))
val callStatus: String = allStatus(random.nextInt(allStatus.length))
val callDuration = if ("success".equals(callStatus)) (1 + random.nextInt(10)) * 1000L else 0L
// 随机产生一条基站日志数据
val stationLog: StationLog = StationLog(
"station_" + random.nextInt(10),
callOut,
callIn,
callStatus,
System.currentTimeMillis(),
callDuration
)
println(stationLog.toString)
Thread.sleep(100 + random.nextInt(100))
val record = new ProducerRecord[String, String]("stationTopic", stationLog.toString)
producer.send(record)
}
producer.close() // 关闭连接
}
/**
* 基站通话日志数据
*/
case class StationLog(
stationId: String, //基站标识符ID
callOut: String, //主叫号码
callIn: String, //被叫号码
callStatus: String, //通话状态
callTime: Long, //通话时间
duration: Long //通话时长
) {
override def toString: String = {
s"$stationId,$callOut,$callIn,$callStatus,$callTime,$duration"
}
}
}
9,创建过滤消费者…Demo09_Kafka_ETL
//TODO 1.加载数据-kafka-stationTopic 实在kafka拉取模拟发送来得大数据,从kafka里面拉取数据来过滤清洗
//TODO 2.处理数据-ETL-过滤出success的数据 需要过滤带有那些字符串的数据…
//TODO 3.输出结果-kafka-etlTopic 是往kafka另外创建的一个主题里面发送过滤完的集合信息,方便业务主体1业务主体2业务主体3不通项目组拉取数据做展示…相当于过滤完存放在另一个队列,等着其他业务部门拉取数据
package cn.itcast.structured
import org.apache.spark.SparkContext
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* Author itcast
* Desc 演示StructuredStreaming整合Kafka,
* 从stationTopic消费数据 -->使用StructuredStreaming进行ETL-->将ETL的结果写入到etlTopic
*/
object Demo09_Kafka_ETL {
def main(args: Array[String]): Unit = {
//TODO 0.创建环境
//因为StructuredStreaming基于SparkSQL的且编程API/数据抽象是DataFrame/DataSet,所以这里创建SparkSession即可
val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[2]")
.config("spark.sql.shuffle.partitions", "4") //本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
//TODO 1.加载数据-kafka-stationTopic
val kafkaDF: DataFrame = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "192.168.1.158:9092")
.option("subscribe", "stationTopic")
.load()
val valueDS: Dataset[String] = kafkaDF.selectExpr("CAST(value AS STRING)").as[String]
//TODO 2.处理数据-ETL-过滤出success的数据
val etlResult: Dataset[String] = valueDS.filter(_.contains("success"))
print(etlResult)
//TODO 3.输出结果-kafka-etlTopic
etlResult.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "192.168.1.158:9092")
.option("topic", "etlTopic")
.option("checkpointLocation", "L:\\sparkmllib\\checled")
//TODO 4.启动并等待结束
.start()
.awaitTermination()
print(etlResult)
//TODO 5.关闭资源
spark.stop()
}
}
//0.kafka准备好
//1.启动数据模拟程序
//2.启动控制台消费者方便观察
//3.启动Demo09_Kafka_ETL
**
以上,一个完整的大数据处理就完成了,这是是真实项目环境中需要用到的
**















 2549
2549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









