







模型总体架构
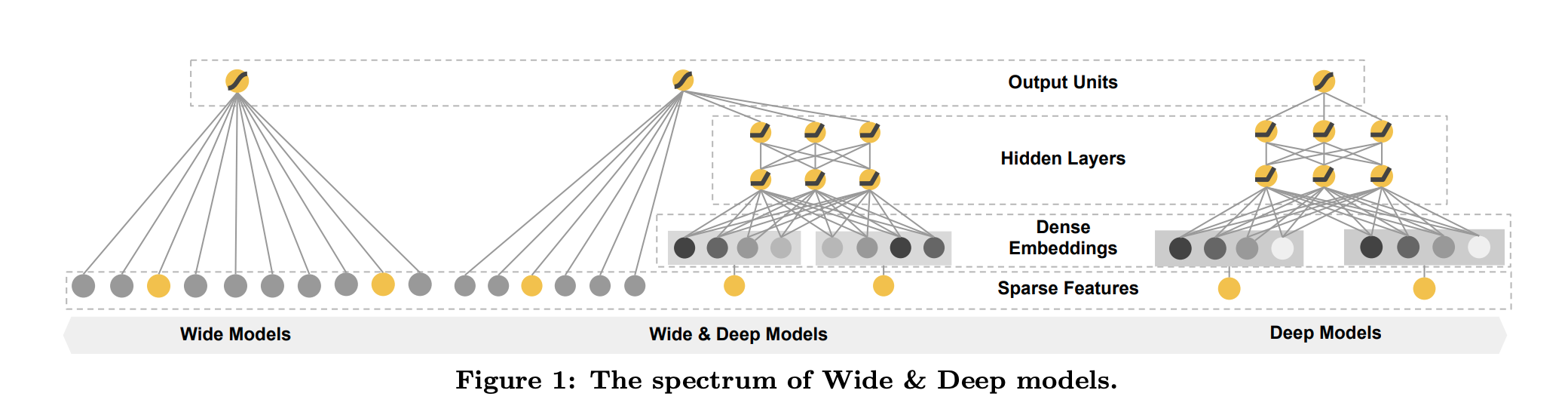
设计动机
模型包含两个部分
Wide部分:
这个部分就是一个简单的LR模型,负责“Memorization”,通过一系列人工的特征叉乘(Cross Product)来构造这些非线性特征,捕捉稀疏特征之间的高阶相关性,即“记忆” 历史数据中曾共同出现过的特征对。
比如,特征1:性别={男,女},特征2:兴趣={电子游戏,舞蹈},这两个特征的组合特征是:
男×电子游戏,男×舞蹈,女×电子游戏,女×舞蹈
这些交叉特征输入到Wide部分,可以让模型记住特征之间的相关性。
Deep部分:
这个部分就是一个前馈网络,这部分负责“Generalization”,为稀疏特征学习低维的Dense Embeddings来捕获特征相关性,这里可以学习到新的特征组合,提高推荐物品的多样性。
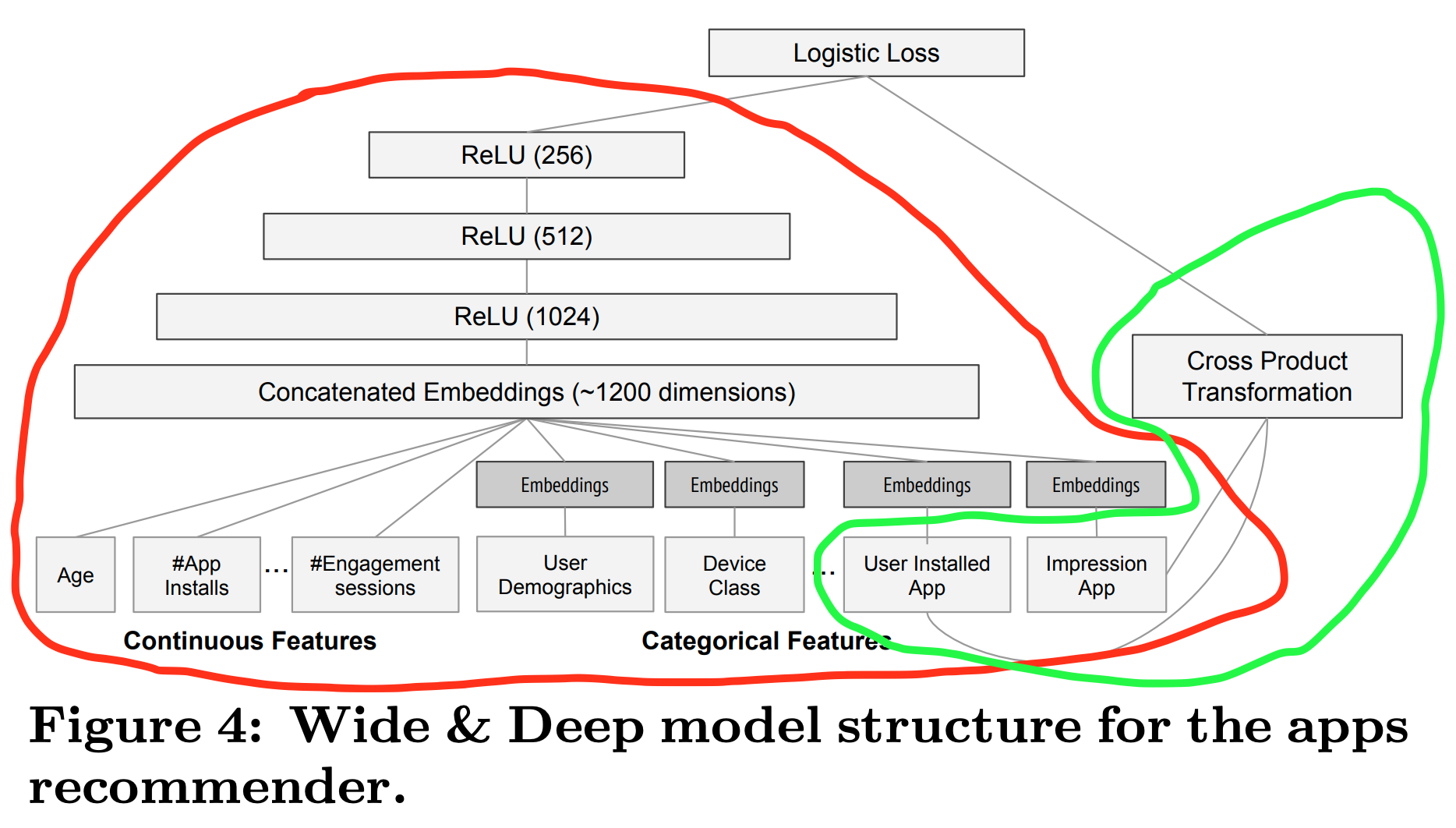
模型本身的结构是非常简单的,但是需要根据具体问题决定哪些特征放在Wide部分,哪些放在Deep部分。
Wide部分的特征,上图绿色部分
输入是用户安装的App(User Installed App)和当前曝光App(Impression App)的交叉特征,这两个都是类别型特征(Categorical Feature),而且App的数量一般都是百万级别,因此这里维数会非常高
Deep部分的特征,上图红色部分
对于类别型特征(Categorical Features),比如User Demographic,Device Class,User Installed App,Impression App等,首先学习一个32维的Embedding向量,然后再跟连续型特征进行拼接,组成一个约1200维的Concatenated Embeddings,之后紧接3层ReLU全连接层,最终输出一个256维的向量
训练时,Wide部分采用带L1正则化的FTRL(Follow The Regularized Leader )优化器,Deep部分采用AdaGrad优化器。FTRL的优点是获得稀疏解,也就是让大部分权重都为0,类似L1正则化,上文说到Wide部分的特征维度是非常高的,所以采用FTRL可以剔除大部分无关特征,起到降维作用。而AdaGrad是深度神经网络常用的优化器。
训练集规模:5千亿(500 billion)
参考:
[1] Wide&Deep模型原理与实现
[2] 见微知著,你真的搞懂Google的Wide&Deep模型了吗?
[3] TensorFlow Wide And Deep 模型
[4] 详解 Wide & Deep 结构背后的动机
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











