







 本文详细介绍了TensorFlow的Wide & Deep模型,该模型结合线性模型和深度学习的优势,用于分类和回归任务。文章涵盖了模型定义、特征处理、训练过程,包括sparse column、embedding column、线性模型和DNN模型的参数。此外,还探讨了模型的优缺点以及在Google Play应用推荐中的应用。
本文详细介绍了TensorFlow的Wide & Deep模型,该模型结合线性模型和深度学习的优势,用于分类和回归任务。文章涵盖了模型定义、特征处理、训练过程,包括sparse column、embedding column、线性模型和DNN模型的参数。此外,还探讨了模型的优缺点以及在Google Play应用推荐中的应用。
作者简介:汪剑,现在在出门问问负责推荐与个性化。曾在微软雅虎工作,从事过搜索和推荐相关工作。
责编:何永灿(heyc@csdn.net)
本文首发于CSDN,未经允许不得转载。
Wide and deep 模型是 TensorFlow 在 2016 年 6 月左右发布的一类用于分类和回归的模型,并应用到了 Google Play 的应用推荐中 [1]。wide and deep 模型的核心思想是结合线性模型的记忆能力(memorization)和 DNN 模型的泛化能力(generalization),在训练过程中同时优化 2 个模型的参数,从而达到整体模型的预测能力最优。
结合我们的产品应用场景同 Google Play 的推荐场景存在较多的类似之处,在经过调研和评估后,我们也将 wide and deep 模型应用到产品的推荐排序模型,并搭建了一套线下训练和线上预估的系统。鉴于网上对 wide and deep 模型的相关描述和讲解并不是特别多,我们将这段时间对 TensorFlow1.1 中该模型的调研和相关应用经验分享出来,希望对相关使用人士带来帮助。
wide and deep 模型的框架在原论文的图中进行了很好的概述。wide 端对应的是线性模型,输入特征可以是连续特征,也可以是稀疏的离散特征,离散特征之间进行交叉后可以构成更高维的离散特征。线性模型训练中通过 L1 正则化,能够很快收敛到有效的特征组合中。deep 端对应的是 DNN 模型,每个特征对应一个低维的实数向量,我们称之为特征的 embedding。DNN 模型通过反向传播调整隐藏层的权重,并且更新特征的 embedding。wide and deep 整个模型的输出是线性模型输出与 DNN 模型输出的叠加。
如原论文中提到的,模型训练采用的是联合训练(joint training),模型的训练误差会同时反馈到线性模型和 DNN 模型中进行参数更新。相比于 ensemble learning 中单个模型进行独立训练,模型的融合仅在最终做预测阶段进行,joint training 中模型的融合是在训练阶段进行的,单个模型的权重更新会受到 wide 端和 deep 端对模型训练误差的共同影响。因此在模型的特征设计阶段,wide 端模型和 deep 端模型只需要分别专注于擅长的方面,wide 端模型通过离散特征的交叉组合进行 memorization,deep 端模型通过特征的 embedding 进行 generalization,这样单个模型的大小和复杂度也能得到控制,而整体模型的性能仍能得到提高。
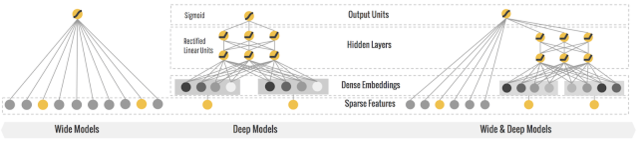
Wide And Deep 模型定义
定义 wide and deep 模型是比较简单的,tutorial 中提供了比较完整的模型构建实例:
获取输入
模型的输入是一个 python 的 dataframe。如 tutorial 的实例代码,可以通过 pandas.read_csv 从 CSV 文件中读入数据构建 data frame。
定义 feature columns
tf.contrib.layers 中提供了一系列的函数定义不同类型的 feature columns:
- tf.contrib.layers.sparse_column_with_XXX 构建低维离散特征
sparse_feature_a = sparse_column_with_hash_bucket(…)
sparse_feature_b = sparse_column_with_hash_bucket(…) - tf.contrib.layers.crossed_column 构建离散特征的组合
sparse_feature_a_x_sparse_feature_b = crossed_column([sparse_feature_a, sparse_feature_b], …) - tf.contrib.layers.real_valued_column 构建连续型实数特征
real_feature_a = real_valued_column(…) - tf.contrib.layers.embedding_column 构建 embedding 特征
sparse_feature_a_emb = embedding_column(sparse_id_column=sparse_feature_a, )
定义模型
定义分类模型:
m = tf.contrib.learn.DNNLinearCombinedClassifier(
n_classes = n_classes, // 分类数目
weight_column_name = weight_column_name, // 训练实例的权重
model_dir = model_dir, // 模型目录
linear_feature_columns = wide_columns, // 输入线性模型的 feature columns
linear_optimizer = tf.train.FtrlOptimizer(...), // 线性模型权重更新的 optimizer
dnn_feature_columns = deep_columns, // 输入 DNN 模型的 feature columns
dnn_hidden_units=[100, 50],// DNN 模型的隐藏层单元数目
dnn_optimizer=tf.train.AdagradOptimizer(...) // DNN 模型权重更新的 optimizer
)
需要指出的是:模型的 model_dir 同下面会提到的 export 模型的目录是 2 个不同的目录,model_dir 存放模型的 graph 和 summary 数据,如果 model_dir 存放了上一次训练的模型数据,训练时会从 model_dir 恢复上一次训练的模型并在此基础上进行训练。我们用 tensorboard 加载显示的模型数据也是从该目录下生成的。模型 export 的目录则主要是用于 tensorflow server 启动时加载模型的 servable 实例,用于线上预测服务。
如果要使用回归模型,可以如下定义:
m = tf.contrib.learn.DNNLinearCombinedRegressor(
weight_column_name = weight_column_name,
linear_feature_columns = wide_columns,
linear_optimizer = tf.train.FtrlOptimizer(...),
dnn_feature_columns = deep_columns,
dnn_hidden_units=[100, 50],
dnn_optimizer=tf.train.AdagradOptimizer(...)
)
训练评测
训练模型可以使用 fit 函数:m.fit(input_fn=input_fn(df_train)),评测使用 evaluate 函数:m.evaluate(input_fn=input_fn(df_test))。Input_fn 函数定义如何从输入的 dataframe 构建特征和标记:
def input_fn(df)
// tf.constant 构建 constant tensor,df[k].values 是对应 feature column 的值构成的 list
continuous_cols = {k: tf.constant(df[k].values) for k in CONTINUOUS_COLUMNS}
// tf.SparseTensor 构建 sparse tensor,SparseTensor 由 indices,values, dense_shape 三
// 个 dense tensor 构成,indices 中记录非零元素在 sparse tensor 的位置,values 是
// indices 中每个位置的元素的值,dense_shape 指定 sparse tensor 中每个维度的大小
// 以下代码为每个 category column 构建一个 [df[k].size,1] 的二维的 SparseTensor。
categorical_cols = {
k: tf.SparseTensor( indices=[[i, 0] for i in range(df[k].size)],
values=df[k].values,
dense_shape=[df[k].size, 1])
for k in CATEGORICAL_COLUMNS
}
// 可以用以下示意图来表示以上代码构建的 sparse tensor
// label 是一个 constant tensor,记录每个实例的 label
label = tf.constant(df[LABEL_COLUMN].values)
// features 是 continuous_cols 和 categorical_cols 的 union 构成的 dict
// dict 中每个 entry 的 key 是 feature column 的 name,value 是 feature column 值的 tensor
return features, label
输出
模型通过 export 输出到一个指定目录,tensorflow serving 从该目录加载模型提供在线预测服务:m.export(export_dir=export_dir,input_fn = export._default_input_fn
use_deprecated_input_fn=True,signature_fn=signature_fn)
input_fn 函数定义生成模型 servable 实例的特征,signature_fn 函数定义模型输入输出的 signature。
由于在 TensorFlow1.0 之后 export 已经 deprecate,需要用 export_savedmodel 来替代,所以本文就不对 export 进行更多讲解,只在文末给出我们是如何使用它的,建议所有使用者以后切换到最新的 API。
模型详解
wide and deep 模型是基于 TF.learn API 来实现的,其源代码实现主要在 tensorflow.contrib.learn.python.learn.estimators 中。以分类模型为例,wide 与 deep 结合的分类模型对应的类是 DNNLinearCombinedClassifier,实现在源文件 dnn_linear_combined.py。我们先看看 DNNLinearCombinedClassifier 的初始化函数的完整定义,看构造一个 wide and deep 模型可以输入哪些参数:
def __init__(self, model_dir=None, n_classes=2, weight_column_name=None, linear_feature_columns=None,
linear_optimizer=None, joint_linear_weights=False, dnn_feature_columns=None,
dnn_optimizer=None, dnn_hidden_units=None, dnn_activation_fn=nn.relu, dnn_dropout=None,
gradient_clip_norm=None, enable_centered_bias=False, config=None,
feature_engineering_fn=None, embedding_lr_multipliers=None):
我们可以将类的构造函数中的参数分为以下几组
基础参数
model_dir
我们训练的模型存放到 model_dir 指定的目录中。如果我们需要用 tensorboard 来 DEBUG 模型,将 tensorboard 的 logdir 指向该目录即可:tensorboard –logdir=$model_dirn_classes
分类数。默认是二分类,>2 则进行多分类。weight_column_name
定义每个训练样本的权重。训练时每个训练样本的训练误差乘以该样本的权重然后用于权重更新梯度的计算。如果需要为每个样本指定权重,input_fn 返回的 features 里需要包含一个以 weight_column_name 为列名的列,该列的长度为训练样本的数目,列中每个元素对应一个样本的权重,数据类型是 float,如以下伪代码:
weight = tf.constant(df[WEIGHT_COLUMN_NAME].values, dtype=float32);
features[weight_column_name] = weightconfig
指定运行时配置参数eature_engineering_fn
对输入函数 input_fn 输出的 (features, label) 进行后处理生成新的 (features』, label』) 然后输入给模型训练函数 model_fn 使用。
call_model_fn():
feature, labels = self._feature_engineering_fn(feature, labels)
线性模型相关参数
linear_feature_columns
线性模型的输入特征linear_optimizer
线性模型的优化函数,定义权重的梯度更新算法,默认采用 FTRL。所有默认支持的 linea
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7316
7316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









