







MS COCO数据集介绍以及pycocotools使用
1、MS COCO数据集简介

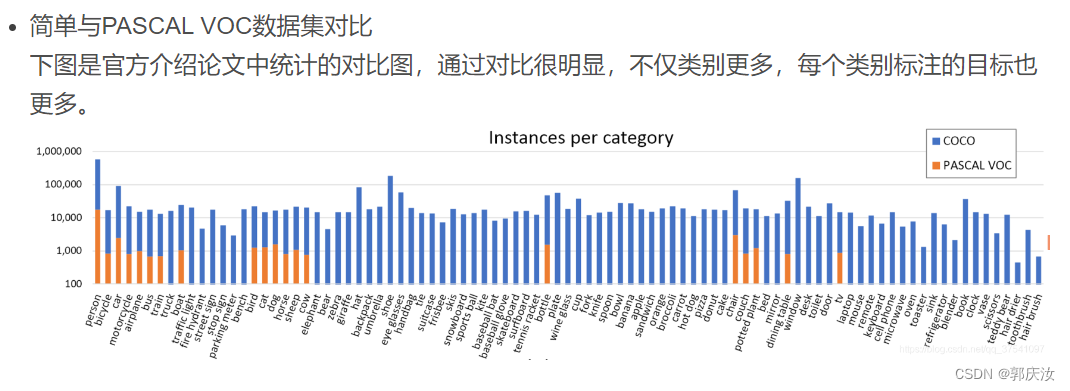
2、MS COCO数据集目录结构

├── coco2017: 数据集根目录
├── train2017: 所有训练图像文件夹(118287张)
├── val2017: 所有验证图像文件夹(5000张)
└── annotations: 对应标注文件夹
├── instances_train2017.json: 对应目标检测、分割任务的训练集标注文件
├── instances_val2017.json: 对应目标检测、分割任务的验证集标注文件
├── captions_train2017.json: 对应图像描述的训练集标注文件
├── captions_val2017.json: 对应图像描述的验证集标注文件
├── person_keypoints_train2017.json: 对应人体关键点检测的训练集标注文件
└── person_keypoints_val2017.json: 对应人体关键点检测的验证集标注文件夹
3、 MS COCO标注文件格式
3.1 使用Python的json库查看

import json
json_path = "/data/coco2017/annotations/instances_val2017.json"
json_labels = json.load(open(json_path, "r"))
print(json_labels["info"])
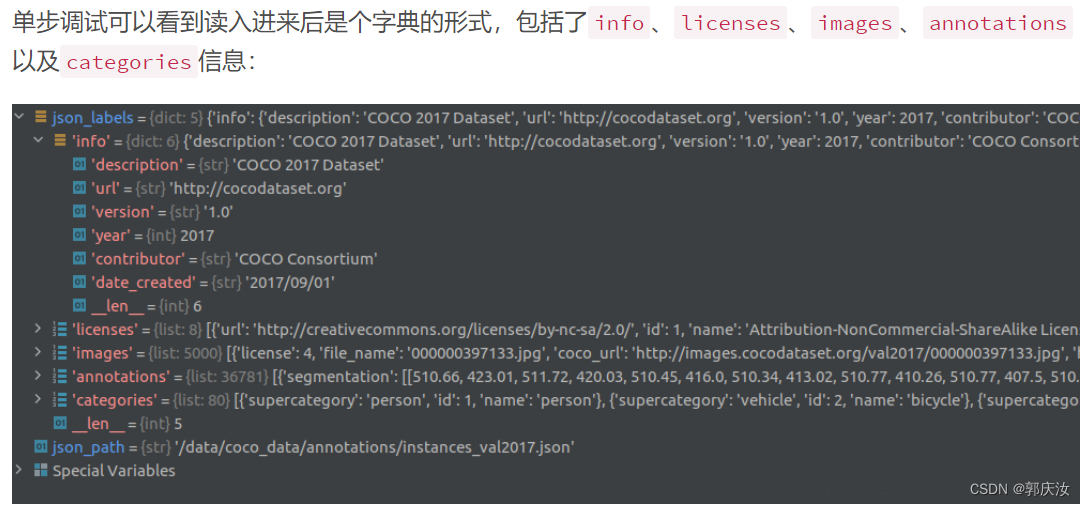
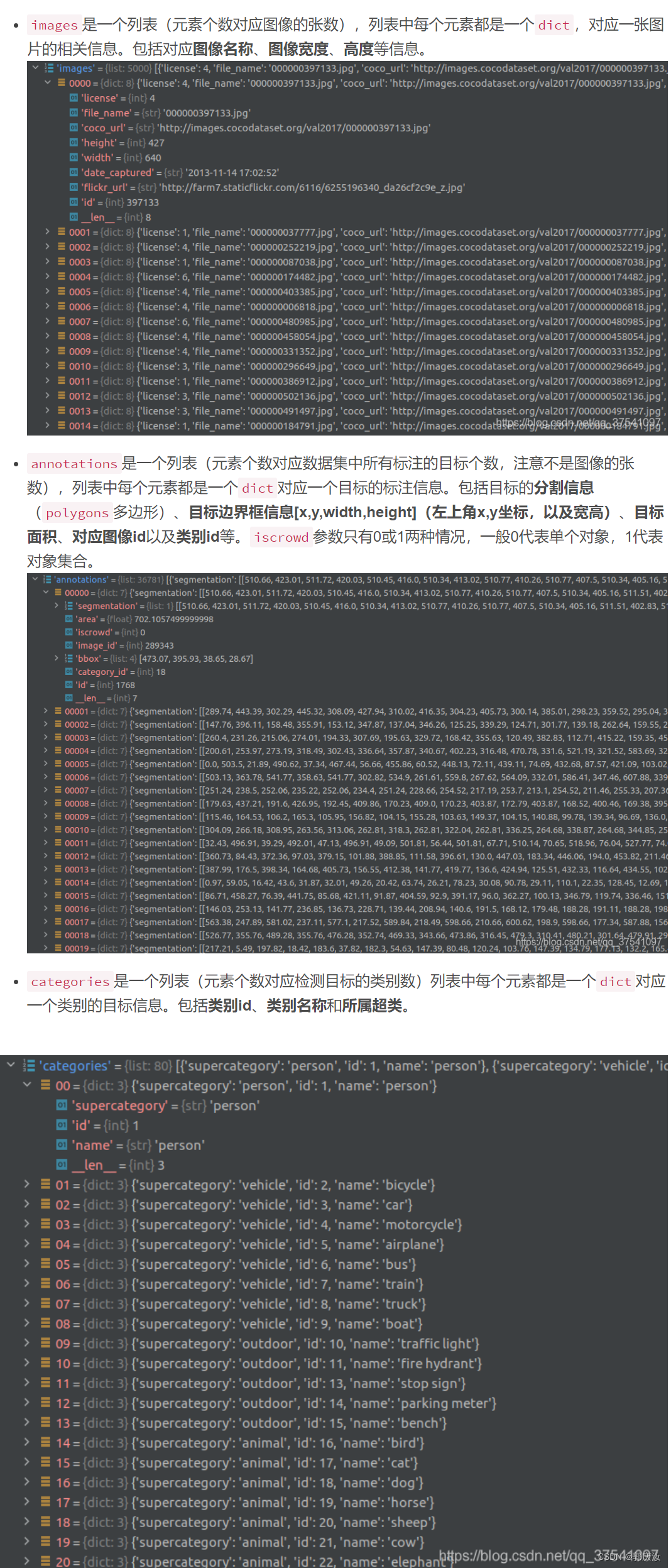
3.2 使用官方cocoAPI查看
安装:
# ubuntu
pip install pycocotools
# Windows
pip install pycocotools-windows
读取每张图片的bbox信息
下面是使用pycocotools读取图像以及对应bbox信息的简单示例:
import os
from pycocotools.coco import COCO
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
json_path = "/data/coco2017/annotations/instances_val2017.json"
img_path = "/data/coco2017/val2017"
# load coco data
coco = COCO(annotation_file=json_path)
# get all image index info
ids = list(sorted(coco.imgs.keys()))
print("number of images: {}".format(len(ids)))
# get all coco class labels
coco_classes = dict([(v["id"], v["name"]) for k, v in coco.cats.items()])
# 遍历前三张图像
for img_id in ids[:3]:
# 获取对应图像id的所有annotations idx信息
ann_ids = coco.getAnnIds(imgIds=img_id)
# 根据annotations idx信息获取所有标注信息
targets = coco.loadAnns(ann_ids)
# get image file name
path = coco.loadImgs(img_id)[0]['file_name']
# read image
img = Image.open(os.path.join(img_path, path)).convert('RGB')
draw = ImageDraw.Draw(img)
# draw box to image
for target in targets:
x, y, w, h = target["bbox"]
x1, y1, x2, y2 = x, y, int(x + w), int(y + h)
draw.rectangle((x1, y1, x2, y2))
draw.text((x1, y1) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7245
7245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









