







pandas
python提供了csv库专门用于csv文件的读写,但它的功能不是很强大。
而pandas则弥补了这些问题:
- 有专门支持读取csv文件的pd.read_csv()函数
- 读取为DataFrame格式
- 支持通过列名查找特定列
- 功能强大,方便扩展
以下是待处理的csv文件:
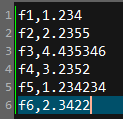
读取
读取csv文件只需要一行代码:
#--coding: utf-8--
import pandas as pd
file_path = r'./demo.csv'
df = pd.read_csv(file_path, header=None, encoding="utf-8-sig", index_col = 0)
print(df)
搞定,输出如下:
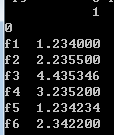
说明:
- read_csv方法返回dataframe
- 可以把 dataframe 看作是一个有行index和列colums的数据结构
- dataframe默认会自动生成自然序号的行index,并以文件第一行内容作为列colums名
- read_csv方法提供了丰富的参数进行定制化地文件读取
- header=None 指定了文件没有表头,不要把第一行当作列名,这里列名是自然序号
- encoding=“utf-8-sig” 指定编码,防止不同操作系统间出现编码问题
- index_col = 0 指定以第一列(0为列的序号)作为行index,这里也可以指定列名
- 还有其它参数,如 usecols=[“a”, “b”] 指定要读取的列名,这时只会读取指定的列
- 也可以使用 names=[“a”, “b”, “c”, “d”] 指定列名,如果已经有列名,则原列名被覆盖
写入
可以先生成一个DataFrame对象,然后直接写入csv文件:
data = {'animal': ['cat', 'dog'],
'age': [2.5, 3],
'name': ['kitty', 'huanghuang'],
'owner': ['kk', 'hh']}
df = pd.DataFrame(data)
print(df)
# 默认自然序号的index会保存到csv文件
df.to_csv("test.csv")
# 不保存index
df.to_csv("test_1.csv", index=False)
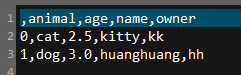
正如注释一样,生成的文件如下:
test.csv:
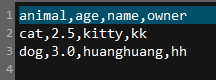
test_1.csv:
在写入中增加选项 columns=["animal", "age"] 可以只把指定的列写入文件:
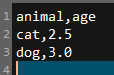
小结
可见,使用pandas操作csv文件是很简单的。
当然,还有很多参数没有列出,如果有需求,可以直接查询相关接口。















 673
673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









