







在之前的博客 SVM解释:二、SVM的数学基础 中,我已经大致介绍了支持向量机(SVM)的数学理论基础。从本文开始,我将逐步推导SVM是如何运用于数据分类的。由简入难,我先来介绍比较简单的,通过训练线性可分的数据分类。
在我写的SVM的第一篇博客中,已经大致介绍了SVM是做什么的,大概是怎样一个思路,所以本文我们直接进入正题,从介绍最大边缘超平面的计算方法开始。
1. 最大边缘超平面
一个给定的数据集如Fig.1所示。数据集被标注为两类(黑点和白点),我们发现,此时数据集是“线性可分的”:即可以找到一个超平面,将数据集按类别分开,如图中虚线所示。当然,在二维空间内是一条线,那么在多维空间中,自然就是一个超平面了。
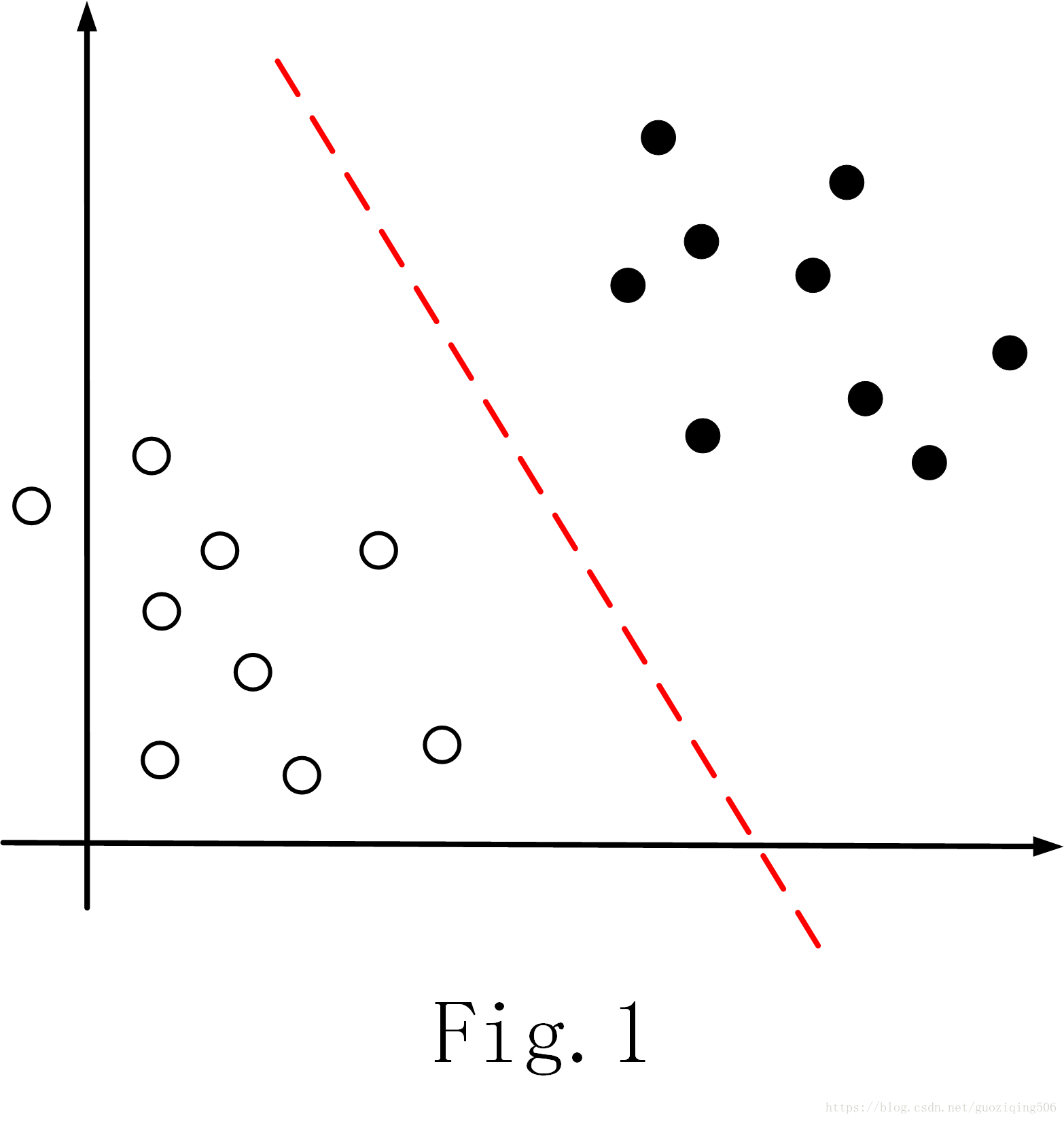
不难想到,我们自然可以把这样一个超平面当做分类器。对于新的未知分类的数据点,可以根据这个点和超平面的位置关系,预测其所在分类。但是现在的问题是,这样的超平面可以有很多,我们显然应该用“最好”的那个,“最好”的定义可以这样解释:它能尽可能地区分属于不同类的数据。那你说咋样算是能尽可能区分呢,直观来说就是为现在的两类数据找一个分离超平面,使得这个平面分别与两类数据的最近的数据点之间的距离之和最大。看下面的Fig.2(a)和Fig.2(b)就明白了:Fig.2(a)中两条蓝色虚线之间的距离显然小于Fig.2(b)中两条蓝色虚线之间的距离。我们把蓝色虚线之间的距离定义为“边缘”,它就是两类数据距离分离超平面的距离之和,而分离超平面,就是与蓝色虚线平行且等距的超平面。这里,显然Fig.2(b)中红色实线是更好地分离超平面。

下面定义几个概念:
- 最大边缘超平面(MMH):即我上面说的“最佳”的分离超平面。它距离两类数据中最近的元组的距离之和最大,且与相应元组等距,比如Fig2.(b)中的红色实线;
- 侧面:与MMH平行,且正好经过类1和类2数据中距离MMH最近的数据点的超平面,记为 H1,H2 H 1 , H 2 ,比如Fig2.(b)中的蓝色虚线;
- 支持向量:在 H1 H 1 和 H2 H 2 上的训练元组(即数据点)被称为“支持向量”,他们离MMH一样近,比如我在Fig.2(b)中用红色标出的数据元组;
综上所述,SVM在训练数据线性可分的情况下,要解决的问题可以用一句话概括:根据训练数据,找到最大边缘超平面(MMH).
2. 计算过程推导
设训练数据集为 X={ X1,X2,…,Xn} X = { X 1 , X 2 , … , X n } ,每个元组 Xi X i 都被标注了一个类别,类别号记为1或者-1(后面我会解释类标号的选取不影响算法,这样标只是为了方便推导)。
假设找到的MMH的方程为:
其中 W={ w1,w2,…,wm} W = { w 1 , w 2 , … , w m } 为权重向量,其维度 m m 也是训练数据的属性数; 为标量。显然,根据这个方程,我们可以找到这两个不同类的数据元组满足的特征,即:
- 在MMH上方的数据元组(即属于类1的数据元组),满足 WX+b≥0 W X + b ≥ 0 ;
- 在MMH下方的数据元组(即属于类-1的数据元组),满足 WX+b≤0 W X + b ≤ 0 ;
据此,我们可以接着写出侧面 H1,H2 H 1 , H 2 的方程:
注1:解释一下 H1 H 1 和 H2 H 2 的方程右侧为什么要用1和-1,其实任意两个绝对值相等的正负数都是可以的。比如我们设为 k k 和 ,等式两边同时除 k k 后,和上式就是一样的了,那能不能设置成任意两个数呢,比如2和3,也是可以的,但是你的MMH的方程就要发生变化了,所以没有这个必要,为了方便计算推导,就直接设为1和-1就行了。
上面说过,两个类的类标号为1和-1,那根据
和 H2 H 2 的方程,对数据集中任意的元组 Xi X i 而言,下面的不等式一定成立:
其中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2273
2273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









