









新发地获取蔬菜水果等食品价格
爬取信息具体如下:
1.食品名称 2.最低价 3.最高价 4.平均价 5.规格 6.产地 7.单位 8.发布日期
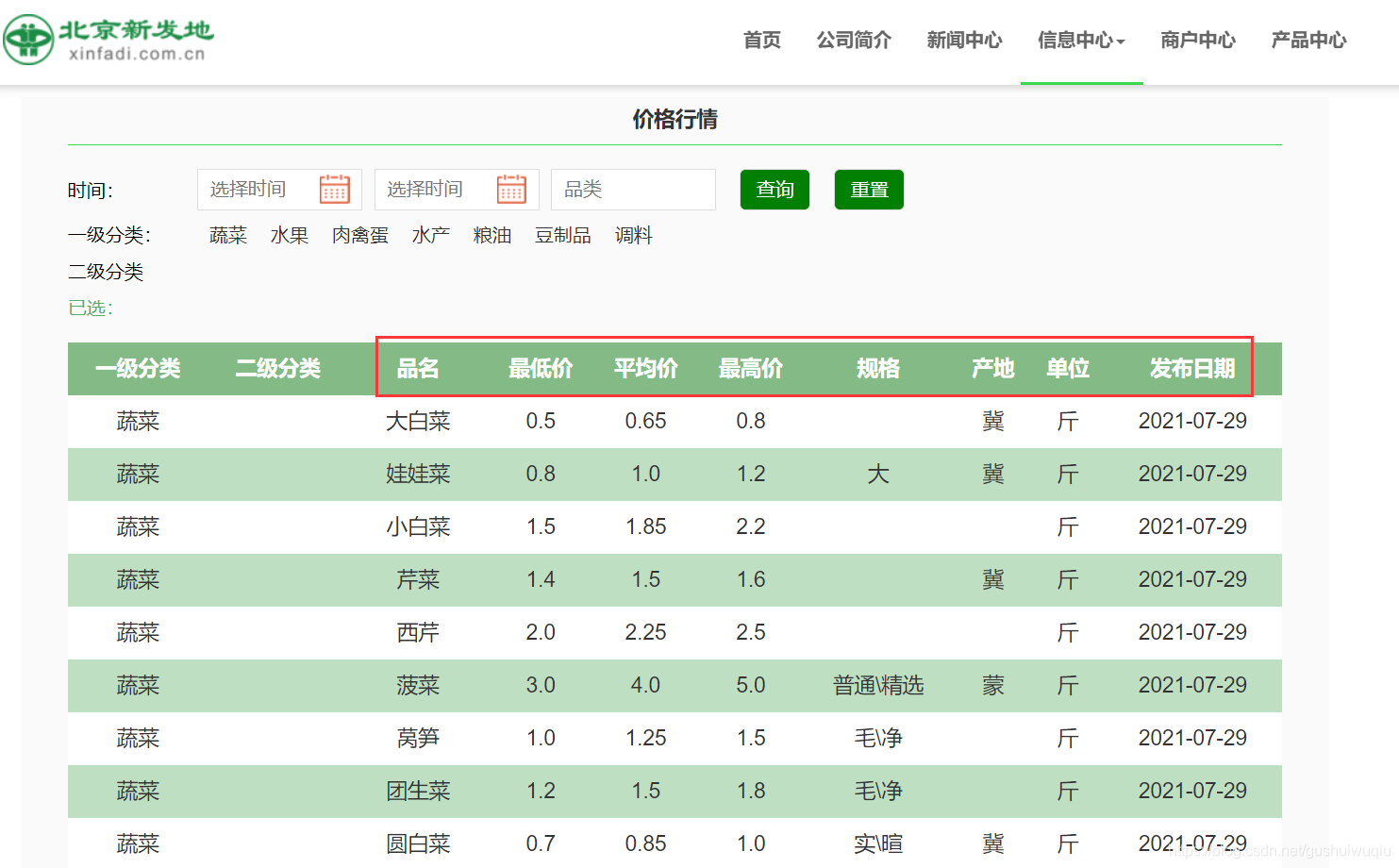
1.检查网页源码
通过检查源码可以看出数据并不在网页源码当中,需通过动态加载获取信息,打开开发者工具进行抓包
2.抓包
刷新页面,抓取商品信息,发现一页共20条商品信息。
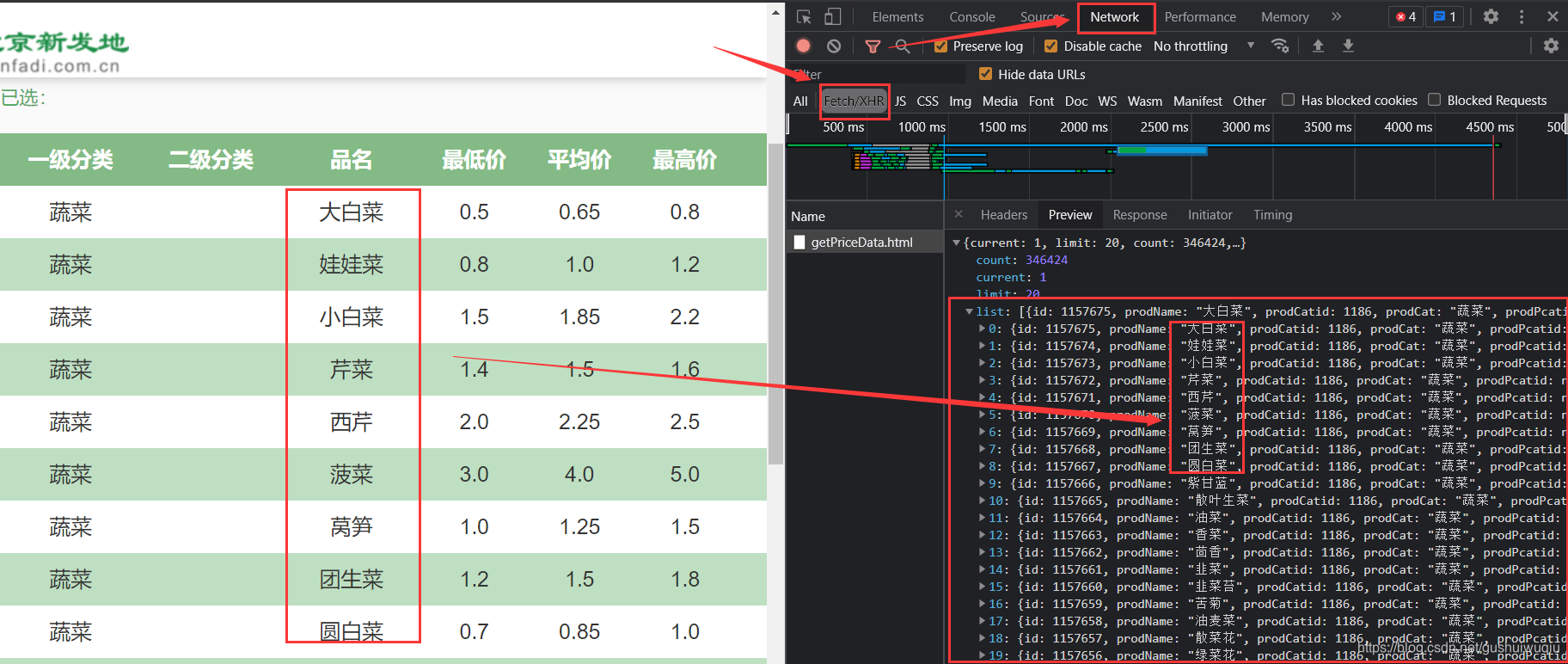
3.分析
查看请求头信息,比对其他页请求地址发现请求地址统一为:
url = 'http://www.xinfadi.com.cn/getPriceData.html'
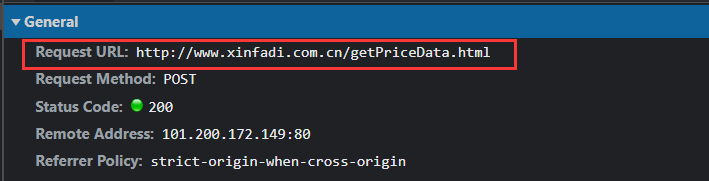
请求头没有特殊内容,直接复制即可
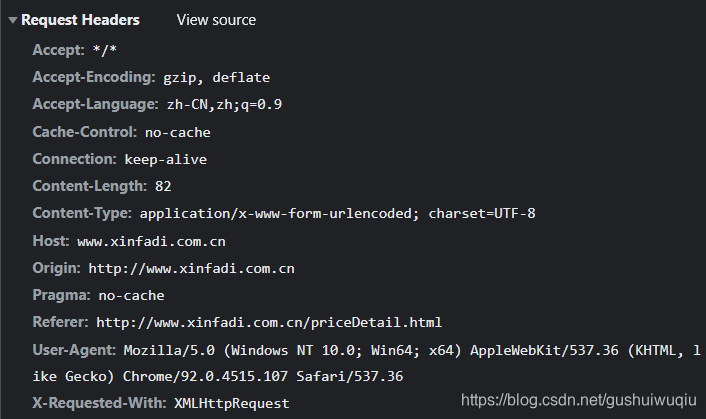
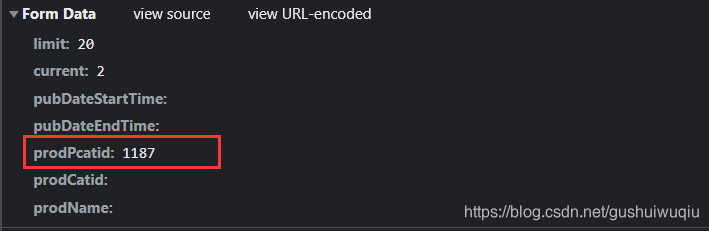
data信息包含关键参数,选取蔬菜点击刷新重新进行抓取发现有三个参数分别是:limit,current,prodPcatid。
第1页data信息
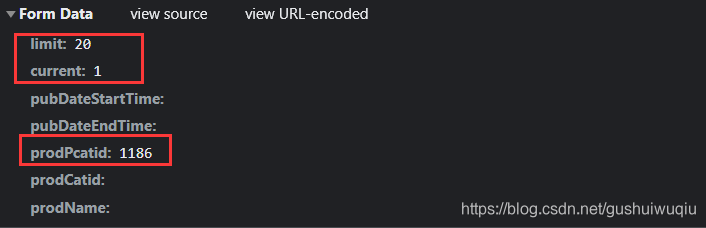
第2页data信息
我们可以看出前前两个参数的用处分别是
- limit :商品数量
- current :页数
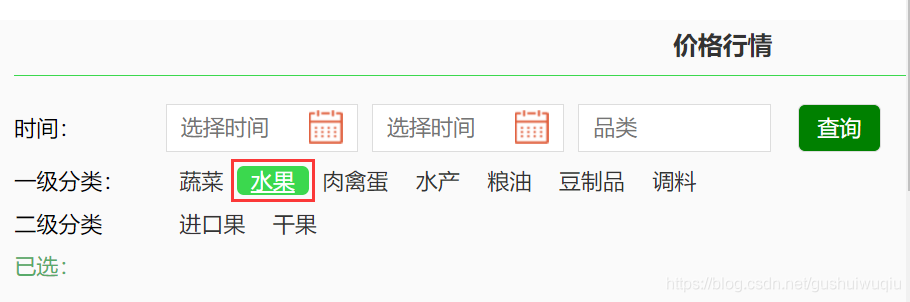
我们选择水果类再重新抓取进行分析,发现prodPcatid改变,我们知道该参数的作用是不同类的id
4.编写代码
import json
import requests
import threading
import pandas as pd
#新发地官网:http://www.xinfadi.com.cn/priceDetail.html
#页数
page = 1
#商品总列表
count=list()
#json列表
jsons=list()
#解析网页函数
def url_parse(page):
#请求地址
url = 'http://www.xinfadi.com.cn/getPriceData.html'
headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Content-Length": "89",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Host": "www.xinfadi.com.cn",
"Origin": "http://www.xinfadi.com.cn",
"Pragma": "no-cache",
"Referer": "http://www.xinfadi.com.cn/priceDetail.html",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36",
"X-Requested-With": "XMLHttpRequest",
}
data = {
"limit": "20",
"current": page,
"pubDateStartTime": "",
"pubDateEndTime": "",
"prodPcatid": "1186", #商品类id
"prodCatid": "",
"prodName": "",
}
response=requests.post(url=url,headers=headers,data=data).text
#获取商品信息
response=json.loads(response)['list']
#生成线程锁对象
lock=threading.RLock()
#上锁
lock.acquire()
#添加到json列表中
jsons.append(response)
#解锁
lock.release()
#解析json函数
def json_parse(product):
lock=threading.RLock()
lock.acquire()
dic = {'品名': product['prodName'], "最低价": product['lowPrice'], '最高价': product['highPrice'],
'平均价': product['avgPrice'], '规格': product['specInfo'], '产地': product['place'], '单位': product['unitInfo'],
'发布日期': product['pubDate']}
print(dic)
#将商品信息添加到商品总列表中
count.append(dic)
lock.release()
def run():
num=int(input('请输入爬取页数:'))
#多进程解析网页
for i in range(1,num+1):
x=threading.Thread(target=url_parse,args=(i,))
x.start()
x.join()
# 多进程解析json
for i in jsons:
for product in i:
y=threading.Thread(target=json_parse,args=(product,))
y.start()
y.join()
#生成excel
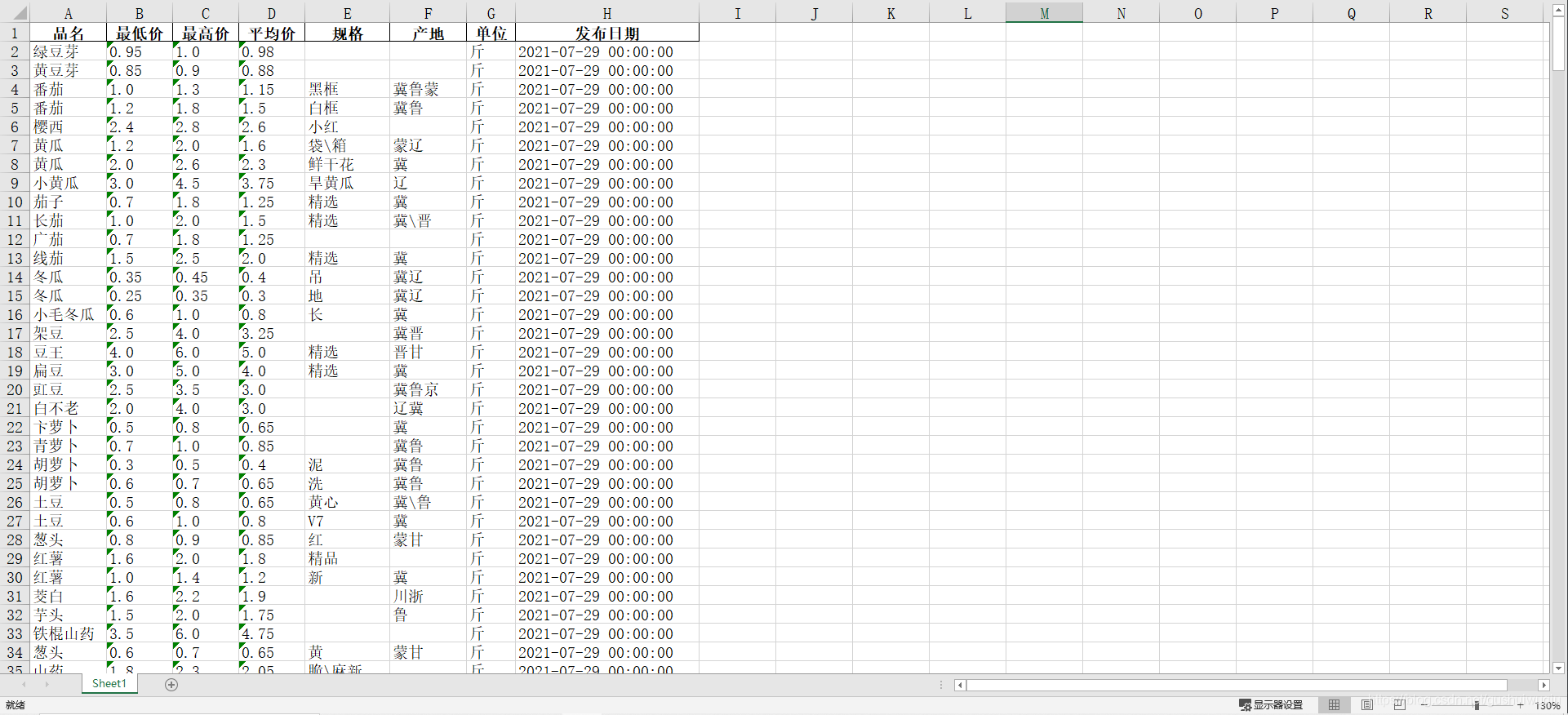
data = pd.DataFrame(count)
data.to_excel('蔬菜.xlsx', index=None)
if __name__ == '__main__':
run()
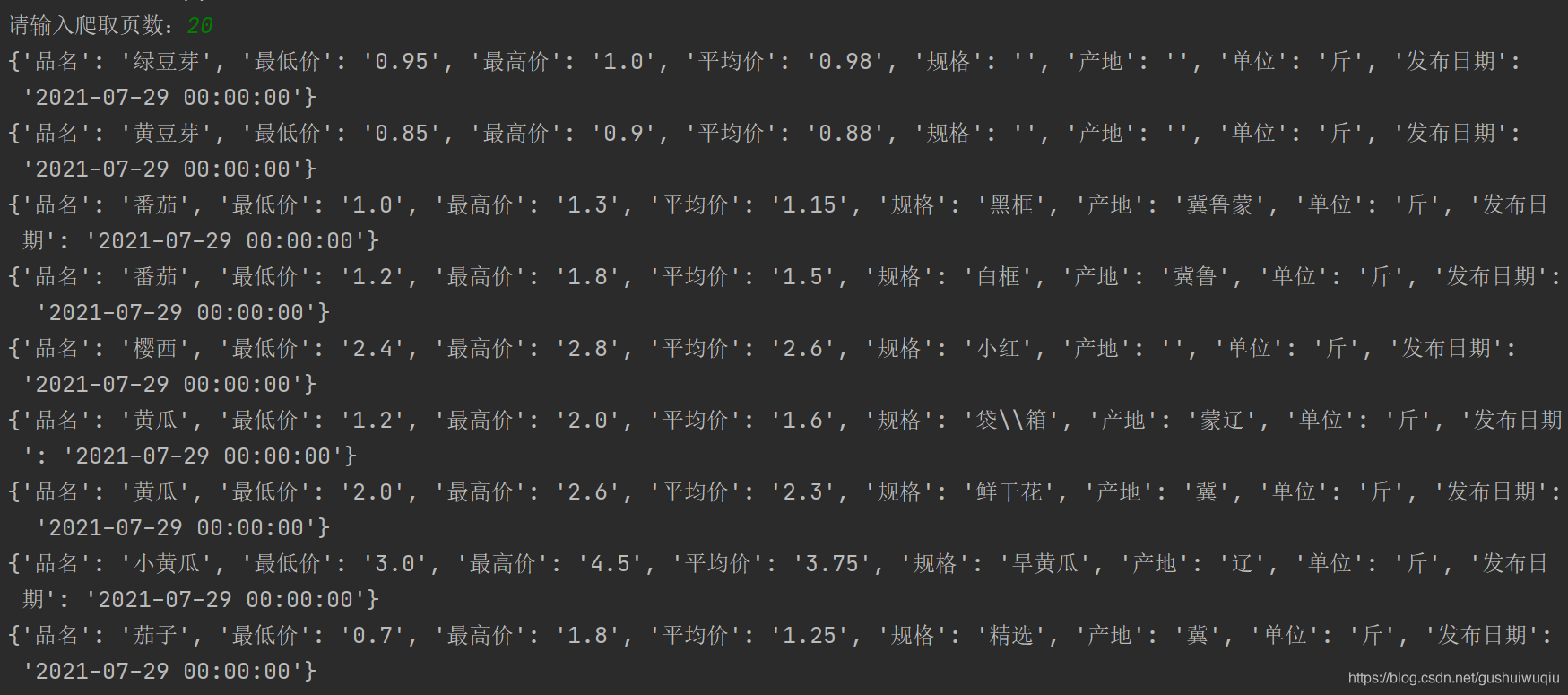
5.运行结果
不到3秒钟就爬完了20页内容


















 2064
2064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









