






想学python,苦于无资源,偶然得知有人说有全套麦某学院的教学视频,赶紧留了个邮箱,几天无果,只能自己动手了
来到麦某学院的官方网站,发现网站上的视频都是免费的,是直接用html5视频的,于是一颗爬虫的种子悄然的发芽了
第一步:打开网站的源代码,用截取各阶段的相应章节地址
1. 从主页上看,python教学视频分成了四个阶段,我们需要把每个阶段的一系列视频都捕获到
2.分析该页面的源代码,发现所有视频链接都在 class=“lead-img”的<a href="" .....里面

于是通过代码:
<span style="font-size:18px;">pythonreg = re.compile(r'lead-img">.+?<a href="(.+?)" title="(.+?)"', re.DOTALL)
pagedata = pythonreg .findall(html)</span><span style="font-size:18px;">/course/python/425-5465</span>
第二步:根据第一步所截取的所有章节的地址获取所有章节的课程地址
1. 随手打开一个章节,发现最右边有全部课程的相关链接

2.再看网页源代码

所有信息都在<div id = “playlist” 的 <li 的 href=""中
于是可通过代码:
<span style="font-size:18px;">partreg = re.compile(r'id="playlist".+?<div>', re.DOTALL) # 获取课程数据的一部分
datareg = re.compile(r'<li.+?href="(.+?)"', re.DOTALL) # 将课程链接剥离出来
coursedata = datareg.findall(partreg.findall(html))</span><span style="font-size:18px;">/course/python/425-5466/</span>

<span style="font-size:18px;">mp4reg = re.compile(r'id="microohvideo".+?src="(.+?)"', re.DOTALL)</span>www.xxxx.com/csshtml3.m4v
至此已经得到了麦x学院的所有python教学视频链接
我将这些链接地址全部存入mysql中,最后附上代码
<pre name="code" class="python"># -*-coding:utf-8-*-
# --------------------
# 爬取麦x学院python教程的大纲链接
# 2015.10.26
# ---------------------
import re # 正则表达式
import urllib2 # 从地址获取网页源代码
import saveDate2DB # 数据库的操作
# 打开网页utl
# 用reg规则返回自己要的数据
def getdata(url,reg):
webpage = urllib2.urlopen(url, timeout=10)
html = webpage.read()
pagedata = reg.findall(html)
return pagedata
pythonurl = "http://www.maiziedu.com/course/python/" # 数据源网址
pythonreg = re.compile(r'lead-img">.+?<a href="(.+?)" title="(.+?)"', re.DOTALL) # 各阶段的章节地址
pythons = getdata(pythonurl, pythonreg) # python大纲中的子地址
urls = []
for course in pythons: # 从python大纲把所有课程链接找出来
print '-----------------正在获取', course[1], '课程链接---------------------'
partreg = re.compile(r'id="playlist".+?<div>', re.DOTALL) # 获取playlist部分
datareg = re.compile(r'<li.+?href="(.+?)"', re.DOTALL) # 将playlist部分中的课程链接剥离出来
mp4reg = re.compile(r'id="microohvideo".+?src="(.+?)"', re.DOTALL) # 将视频匹配出来
courseurl = "http://www.maiziedu.com" + course[0]
coursedata = datareg.findall(getdata(courseurl, partreg)[0]) # 获取所有课程视频的链接
mp4urls = [] # 将所有视频地址存入list中
for mp4html in coursedata:
mp4url = getdata('http://www.maiziedu.com'+mp4html, mp4reg)
print mp4url[0]
mp4urls.append(mp4url[0])
# saveDate2DB.savedata(course[1], mp4urls) # 将数据存入数据库
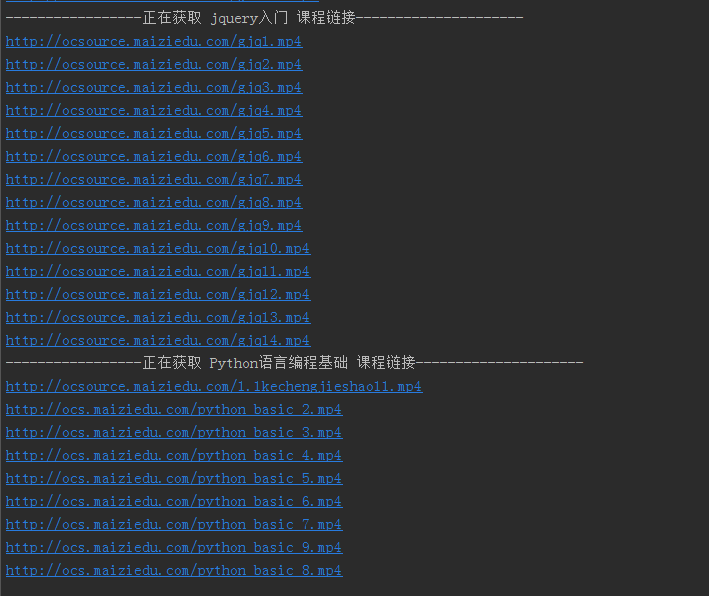
程序运行结果:
另外,我还做了另一项有趣的行动
将下载链接转换为qq旋风下载链接
用程序打开qq旋风并且将数据一个个下载














 533
533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









