









前言
写了两篇博文介绍了:
这一篇将更加深入OCR的世界!
不得不把一些和本专栏(后面会整理出一个系列)相关的参考资料列出来,帮助大家建立知识体系。
1 Tesseract的环境安装 –> 谷震平的传送门
2 Tesseract的使用方法:主要是命令行的使用 –> 传送门
3 Tesseract的Python调用 –> 传送门
4 Tesseract的核心API函数的中文注解 –> 传送门
5 Tesseract的英文API –> 传送门
6 Tesseract原理的必读专业论文(大牛Ray Smith所写) –> 传送门
最最最重要的一个网址,所有资料都是从这里衍生的!那就是Tesseract-ocr在Github上的Wiki,这里是Tesseract最权威的参考资料,没有之一。
权威资料:谷震平的传送门!
Tesseract API
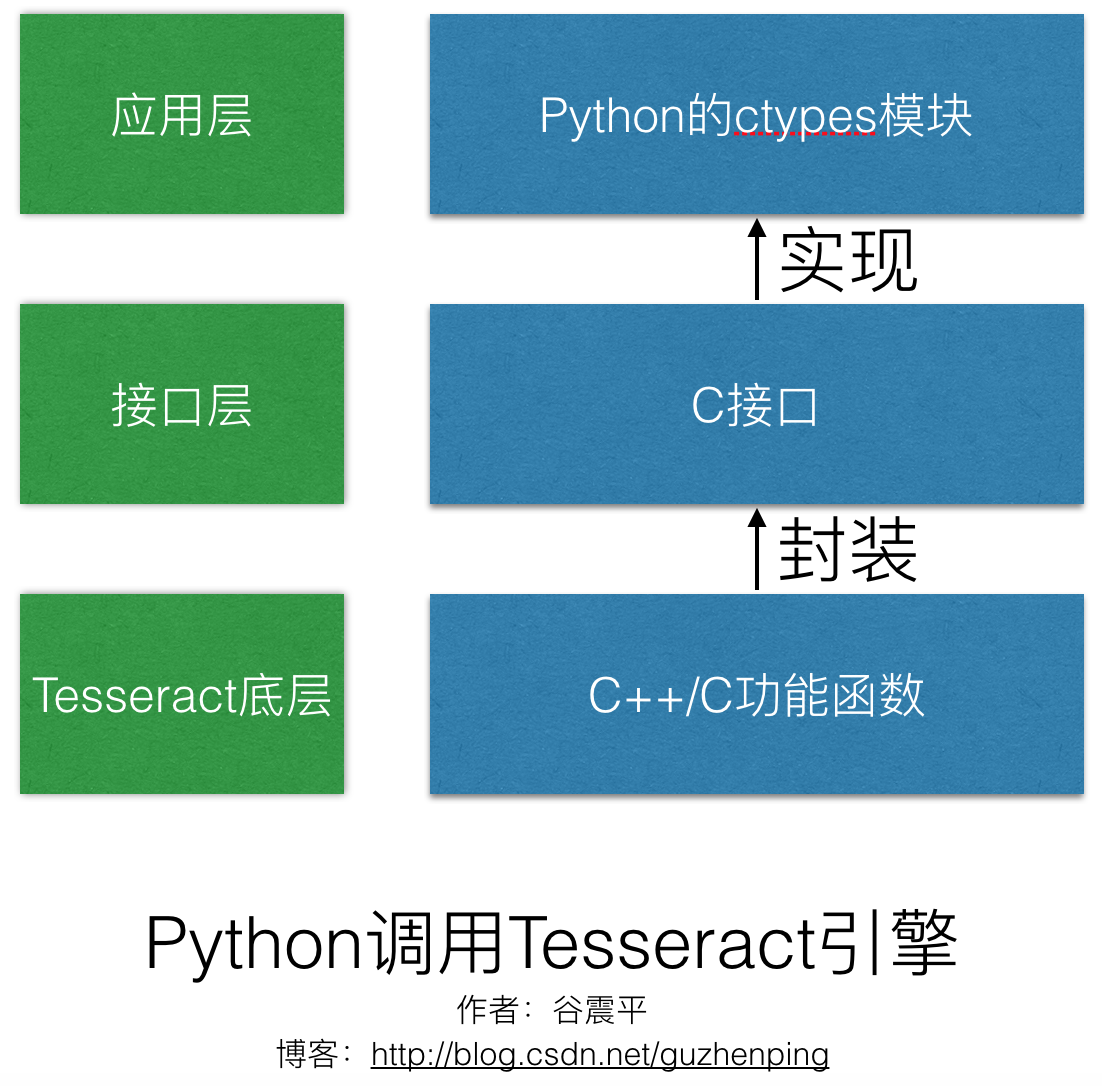
我是在使用Python来做OCR的开发,所以和直接用C/C++的童鞋有点区别。
提个问题:
在Python调用该TessBaseAPI类(Tesseract的核心类)时,使用的是C++ 的API,还是C的API,为什么不是Python自己的API???
答案:Tesseract是C++和C混编而成,核心的代码都是C++写的。当然,核心类TessBaseAPI也是C++。想用Python语言再实现一遍Tesseract的核心类是不现实的,只能让Python自己去调用C++提供的接口。但这是万万不能的,因为Python无法调用C++。BUT!Python可以通过ctypes模块(Python2.4以后的标准库之一)调用C语言。于是,Tesseract的维护者们通过C语言将C++函数的功能封装成接口,再通过Python(ctypes模块)去对接C接口。这样,Python语言可以使用Tesseract引擎了。
所以,Python调用TessBaseAPI类时,使用的是C的API,不是Python的,更不是C++的。
概括下,原理就是:C++实现Tesseract的功能,C作为一个桥梁(桥接),连接Python。这样是不影响执行效率的,因为在做运算时,都是C++,非常快。
TessBaseAPI类
Python调用TessBaseAPICreate()的方法【第一个调用的方法】,就是为了使用TessBaseAPI这个类。不知所以的童鞋,请去API检索TessBaseAPICreate(),它return new TessBaseAPI。
TessBaseAPI这是Tesseract引擎的核心类,搞定它是第一步。该类的内部function请自己查阅API。特别是关于Init() ,setImage()的。
Init()官方源码:
276 int TessBaseAPI::Init(const char* datapath, const char* language,
277 OcrEngineMode oem, char **configs, int configs_size,
278 const GenericVector<STRING> *vars_vec,
279 const GenericVector<STRING> *vars_values,
280 bool set_only_non_debug_params) {
281 PERF_COUNT_START("TessBaseAPI::Init")
282 // 默认识别语言是English:"eng"
283 if (language == NULL) language = "eng";
284 // 如果数据路径,OCR引擎模型或者识别语言被改变,就再次启动引擎
285 // Note that the language_ field stores the last requested language that was
286 // initialized successfully, while tesseract_->lang stores the language
287 // actually used. They differ only if the requested language was NULL, in
288 // which case tesseract_->lang is set to the Tesseract default ("eng").
289 if (tesseract_ != NULL &&
290 (datapath_ == NULL || language_ == NULL ||
291 *datapath_ != datapath || last_oem_requested_ != oem ||
292 (*language_ != language && tesseract_->lang != language))) {
293 delete tesseract_;
294 tesseract_ = NULL;
295 }
296 // PERF_COUNT_SUB("delete tesseract_")
297 #ifdef USE_OPENCL
298 OpenclDevice od;
299 od.InitEnv();
300 #endif
301 PERF_COUNT_SUB("OD::InitEnv()")
302 bool reset_classifier = true;
303 if (tesseract_ == NULL) {
304 reset_classifier = false;
305 tesseract_ = new Tesseract;
306 if (tesseract_->init_tesseract(
307 datapath, output_file_ != NULL ? output_file_->string() : NULL,
308 language, oem, configs, configs_size, vars_vec, vars_values,
309 set_only_non_debug_params) != 0) {
310 return -1;
311 }
312 }
313 PERF_COUNT_SUB("update tesseract_")
314 // 需要最新且有效的初始化,才能更新数据路径和识别语言
315 if (datapath_ == NULL)
316 datapath_ = new STRING(datapath);
317 else
318 *datapath_ = datapath;
319 if ((strcmp(datapath_->string(), "") == 0) &&
320 (strcmp(tesseract_->datadir.string(), "") != 0))
321 *datapath_ = tesseract_->datadir;
322
323 if (language_ == NULL)
324 language_ = new STRING(language);
325 else
326 *language_ = language;
327 last_oem_requested_ = oem;
328 // PERF_COUNT_SUB("update last_oem_requested_")
329 // 对于同样的识别语言和数据路径,只需要重置自适应分类器(the adaptive classifier)
330 if (reset_classifier) {
331 tesseract_->ResetAdaptiveClassifier();
332 PERF_COUNT_SUB("tesseract_->ResetAdaptiveClassifier()")
333 }
334 PERF_COUNT_END
335 return 0;
336 }上述代码可以看到:tesseract_->init_tesseract(datapath, output_file_ != NULL ? output_file_->string() : NULL, language, oem, configs, configs_size, vars_vec, vars_values,set_only_non_debug_params) 这条语句才是核心!
好吧,再去Tesseract类里找init_tesseract()方法。官方源码:
281 // Initialize for potentially a set of languages defined by the language
282 // string and recursively any additional languages required by any language
283 // traineddata file (via tessedit_load_sublangs in its config) that is loaded.
284 // See init_tesseract_internal for args.
285 int Tesseract::init_tesseract(
286 const char *arg0, const char *textbase, const char *language,
287 OcrEngineMode oem, char **configs, int configs_size,
288 const GenericVector<STRING> *vars_vec,
289 const GenericVector<STRING> *vars_values,
290 bool set_only_non_debug_params) {
291 GenericVector<STRING> langs_to_load;
292 GenericVector<STRING> langs_not_to_load;
293 ParseLanguageString(language, &langs_to_load, &langs_not_to_load);
294
295 sub_langs_.delete_data_pointers();
296 sub_langs_.clear();
297 // Find the first loadable lang and load into this.
298 // Add any languages that this language requires
299 bool loaded_primary = false;
300 // Load the rest into sub_langs_.
301 for (int lang_index = 0; lang_index < langs_to_load.size(); ++lang_index) {
302 if (!IsStrInList(langs_to_load[lang_index], langs_not_to_load)) {
303 const char *lang_str = langs_to_load[lang_index].string();
304 Tesseract *tess_to_init;
305 if (!loaded_primary) {
306 tess_to_init = this;
307 } else {
308 tess_to_init = new Tesseract;
309 }
310
311 int result = tess_to_init->init_tesseract_internal(
312 arg0, textbase, lang_str, oem, configs, configs_size,
313 vars_vec, vars_values, set_only_non_debug_params);
314
315 if (!loaded_primary) {
316 if (result < 0) {
317 tprintf("Failed loading language '%s'\n", lang_str);
318 } else {
319 if (tessdata_manager_debug_level)
320 tprintf("Loaded language '%s' as main language\n", lang_str);
321 ParseLanguageString(tess_to_init->tessedit_load_sublangs.string(),
322 &langs_to_load, &langs_not_to_load);
323 loaded_primary = true;
324 }
325 } else {
326 if (result < 0) {
327 tprintf("Failed loading language '%s'\n", lang_str);
328 delete tess_to_init;
329 } else {
330 if (tessdata_manager_debug_level)
331 tprintf("Loaded language '%s' as secondary language\n", lang_str);
332 sub_langs_.push_back(tess_to_init);
333 // Add any languages that this language requires
334 ParseLanguageString(tess_to_init->tessedit_load_sublangs.string(),
335 &langs_to_load, &langs_not_to_load);
336 }
337 }
338 }
339 }
340 if (!loaded_primary) {
341 tprintf("Tesseract couldn't load any languages!\n");
342 return -1; // Couldn't load any language!
343 }
344 if (!sub_langs_.empty()) {
345 // In multilingual mode word ratings have to be directly comparable,
346 // so use the same language model weights for all languages:
347 // use the primary language's params model if
348 // tessedit_use_primary_params_model is set,
349 // otherwise use default language model weights.
350 if (tessedit_use_primary_params_model) {
351 for (int s = 0; s < sub_langs_.size(); ++s) {
352 sub_langs_[s]->language_model_->getParamsModel().Copy(
353 this->language_model_->getParamsModel());
354 }
355 tprintf("Using params model of the primary language\n");
356 if (tessdata_manager_debug_level) {
357 this->language_model_->getParamsModel().Print();
358 }
359 } else {
360 this->language_model_->getParamsModel().Clear();
361 for (int s = 0; s < sub_langs_.size(); ++s) {
362 sub_langs_[s]->language_model_->getParamsModel().Clear();
363 }
364 if (tessdata_manager_debug_level)
365 tprintf("Using default language params\n");
366 }
367 }
368
369 SetupUniversalFontIds();
370 return 0;
371 }上述代码可以看到:int result = tess_to_init->init_tesseract_internal(arg0, textbase, lang_str, oem, configs, configs_size,vars_vec, vars_values, set_only_non_debug_params); 这条语句才是核心代码!
就这样。。。你需要一个一个地去看。想看的懂代码,就需要自己去积累、去琢磨。写到这里,后续更新!
The End
欢迎交流,不得不说,人家花10年搞出来的东西,你想改核心代码,还是很困难的。好就好在,人可以坚持不懈,可以团结合作!
内容来自谷震平的blog,尊重原创,转载注明出处!
谢谢大家,希望批评交流!
新开通微信公众号,欢迎关注原创文章:
















 696
696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









