







1、从灰度图像中提取轮廓,从轮廓中提取特征(skeleton方法)。
2、字符的边界框经常重叠,而字符实际上没有接触。
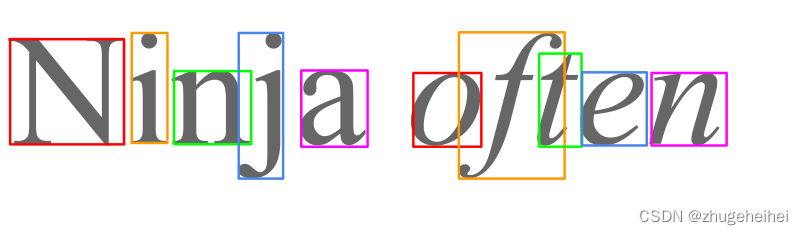
3、经验:对于尽可能多的预期退化,特性必须尽可能不变
4、收缩特性和不适当的统计数据(教训:统计上的独立性是很难回避的)
5、同时期其他ocR:神经网络刚起步,硬件计算能力不行,基于决策树使用类似拓扑的特征。在软件方面非常快。在质量差的情况下,精度下降得非常快。
6、关于测试:获得大量的计算能力和数据。在与训练数据非常不同的数据上进行测试。测试每一个变化。测量多种维度。如果它能打破,它就会打破。让你的代码在等待测试运行时更快。跳出框框思考。
7、最新提升:国际化到100多种语言。添加全布局分析。表检测。方程/公式检测。更好的语言模型。改进的分段搜索。Word Bigrams。输出PDF。训练工具。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









