







| Boost C++ Libraries 的 PropertyTree 這個函式庫(官方文件),基本上是一種通用型的樹狀資料結構的資料結構;在這棵資料樹裡面的每一個節點,都有它自己的資料、以及下方的成員清單。他每一個節點的內部資料結構,在概念上可以看成類似下面的形式: struct ptree
{
data_type data;
list< pair<key_type, ptree> > children;
}; 而在使用上呢,Property Tree 除了類似 STL container 的操作方法外,也有提供以 key(索引值)組合出來的路徑(path)來做資料存取的能力,功能算是滿強大的!另外,PropertyTree 除了提供這樣的資料結構外,也提供了 XML、INI、JSON 這幾種常見的檔案標種的 parser,讓程式開發者可以簡單地透過這個函式庫,來讀取/寫入這些檔案,把他們變成結構化的資料。 這一篇文章,基本上就是來講一下,要怎麼使用 PropertyTree 這個函式庫,來處理 XML 檔案了。而當然,這邊也會提到一些 PropertyTree 的資料結構的存取概念,所以理論上之後要用在其他格式上,問題應該也不大。 XML 的讀取/寫入Boost PropertyTree 所提供的 XML Parser 基本上是基於 RapidXML 這個 OpenSource 的 XML parser 來的;而官方文件裡也有提到,他並沒有完整地支援 XML 所有的標準(例如他無法處理 DTD、也不支援 encoding 的處理),這是在使用上要注意的地方。不過對於一般使用來說,基本上應該是夠用了。 在使用上,Boost PropertyTree 在 boost/property_tree/xml_parser.hpp 這個 header 檔裡,提供了 read_xml() 和 write_xml() 這兩種函式,可以將 XML 檔案(或者從 input stream)讀取成 Property Tree 定義的資料結構,也可以將 Property Tree 寫入到 XML 檔案(或指定的 output stream)。 這些函式都在 boost::property_tree::xml_parser 這個 namespace 下,形式是: void read_xml( istream &stream, ptree &pt, int flags ); void read_xml( const string &filename, ptree &pt, int flags, const std::locale &loc ); void write_xml( ostream &stream, const ptree &pt, const xml_writer_settings& settings ); void write_xml( const string &filename, const ptree &pt, const std::locale &loc, const xml_writer_settings& settings ); 以 read_xml() 來說,第一個參數就是資料來源,如果給他一個 string 的話,就是代表是一個檔案名稱,如果是一個 istream 的話,他就會以標準的 input stream(參考)的方法、來讀取資料;而讀取完成的資料,就會儲存在第二個參數、也就是型別為 ptree 的變數中。 而 ptree 這個型別是被定義在 <boost/property_tree/ptree.hpp> 這個 header 檔裡,他的 namespace 是 boost::property_tree,實際上的型別是 basic_ptree<string, string>,也就是每一個節點的索引和值的型別都是 string 的通用型的標準節點;如果有需要的話,應該也是可以使用額外的型別,不過這邊就不提了。(註 1) 實際使用呢,很簡單,就是: std::string sFilename = "a.xml"; boost::property_tree::ptree bPTree; boost::property_tree::xml_parser::read_xml( sFilename, bPTree ); 這樣就可以把 a.xml 的內容,讀取到 bPTree 裡了! 而如果 XML 的資料來源不是檔案的話,只要可以轉換成 input stream 的形式,也都可以用這個 parser 來處理~例如 XML 已經是字串的話,就可以透過 STL 的 string stream 這樣寫: stringstream ss; ss << "<?xml ?><root><test /></root>"; boost::property_tree::ptree bPTree; boost::property_tree::xml_parser::read_xml( ss, bPTree ); 至於輸出的部分,其實也是類似的,只要改用 write_xml()、來源檔案變成要輸出的檔案,或是由 intput stream 變成 output stream 而已~下面就是一個簡單的例子: boost::property_tree::ptree bPTree; //..... boost::property_tree::xml_parser::write_xml( "test.xml", bPTree );
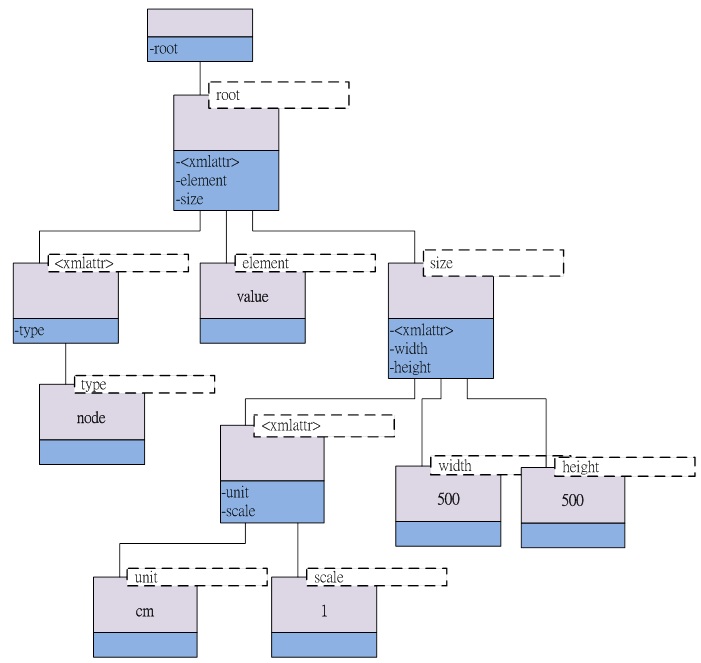
ptree 形式的 XML 的資料形式既然已經把 XML 的資料都塞到 ptree 這個形式的資料結構裡了,接下來,自然就是看要怎麼把他讀出來了~ 基本上,ptree 這個資料結構,是代表 XML 中的單一元素(element),但是它本身不會記錄自己的名稱,而是把名稱交給自己的上一層來做紀錄。所以它基本上只會記錄自己的值,以及用一個 pair<string, ptree> 的 list 來記錄屬於自己的其他資料,例如底下的 child element 和 attribute;其中,list 裡的每一個 pair 的第一項就是名稱、第二項則是以 ptree 形式來記錄的資料。 要注意的是,針對 XML 的資料來源,Property Tree 會有一些特別的索引值,像是所有的 attribute 都會被群組起來,放在一個名為 下面就是一個簡單的例子: <root type="node"> <element>value</element> <size unit="cm" scale="1"> <width>500</width> <height>500</height> </size> </root> 以上方的 XML 片段來說,當透過 Boost 的 Property Tree 的 XML Parser 來分析、以 ptree 的形式來做儲存的時候,它的結構大概會變成是下面這樣:
上面的示意圖裡,每一個方塊都代表一個 ptree 的節點,而上半部淺紫色的部分,是代表這個節點本身的資料(型別是 string),可以透過 data() 這個函式取得;下半部藍色的部分,則是這個節點的 child 的 list(裡面每一項的資料型別都是 pair< string, ptree>)的索引值、也就是 child 的名稱,基本上是以類似 STL container 的 iterator 的形式來做存取。 而右上方的虛線框的部分,則是代表這個節點的名稱,但是如同前面所說的,實際上個別節點並不會真的紀錄自己的名稱,名稱的部分實際上是以 pair 的第一個元素的形式,儲存在 parent 的 child list 中。也因此可以發現,實際上他會用一個沒有名稱、也沒有值的節點當作整棵樹的「根」,底下才是我們要的 XML 的資料。
資料讀取範例概念講完了,實際操作是怎麼用呢?下面就是 Heresy 針對 ptree 寫的 operator<<,可以用在 STL 的 output stream 上;不過為了可以控制縮排、讓輸出比較漂亮,所以 Heresy 是有用 pair 的方法,再把 ptree 和目前是第幾層包成 pair< int, const ptree& > 的形式,第一項的 int 就是代表要縮排幾層而已。 ostream& operator<<( ostream& os, const pair<int, const ptree&>& rNode ) { int iNext = rNode.first + 2; const ptree& rPT = rNode.second; os << " Value: [" << rPT.data() << "]\n"; for( auto it = rPT.begin(); it != rPT.end(); ++ it ) { os.width( iNext ); os << ""; os << "Name: [" << it->first << "]"; os << pair<int, const ptree&>( iNext, it->second ); } return os; } 其中綠底的部分,就是讀取 ptree 的資料的部分,而黃底的部分,則是用 iterator 的形式讀取 child list 的部分;其中,iterator 取得的每一項實際上都是型別為 pair<string, ptree> 的資料,他的 first 就是這個 child 的名稱(型別為 string), second 就是這個 child 的資料(型別為 ptree)。 而要使用的話,就是類似下面這樣: xml_parser::read_xml( ssXML, PTree ); cout.fill( ' ' ); cout << pair<int, const ptree&>( 0, PTree ) << endl; 然後就會輸出成下面這樣的形式: Value: []
Name: [root] Value: []
Name: [<xmlattr>] Value: []
Name: [type] Value: [node]
Name: [element] Value: [value]
Name: [size] Value: []
Name: [<xmlattr>] Value: []
Name: [unit] Value: [cm]
Name: [scale] Value: [1]
Name: [width] Value: [500]
Name: [height] Value: [500]
從這邊使用的例子應該可以看出來,實際上 ptree 的使用形式就是接近一般的 STL container iterator 的操作,如果對於 STL 使用算熟系的話,這邊要操作應該不會有太大的問題;而實際上,ptree 也有提供 find()、push_back()、erase() 這類 STL container 常見的函式,可以進行資料的操作,不過這邊就不提了,有興趣的可以自己玩看看。
指定路徑的資料存取而除了這樣把整個 ptree 當作 STL container、用 iterator 的形式來掃之外,實際上 ptree 也有提供 get() 的函式,可以直接透過索引值的組合的字串(Property Tree 是把它稱為 path、也就是「路徑」)(註 2)、直接讀取 ptree 下面特定節點的資料。 string s1 = PTree.get<string>( "root.element" ); string s2 = PTree.get<string>( "root.size.<xmlattr>.unit" ); 以上面的例子來說,s1 就會是 element 的值、也就是 value,s2 則會是 size 這個 element 的「unit」這個 attribute 的值,也就是「cm」。 而如果希望做型別轉換的話,也是可以在透過 get() 讀取時,讓他一起做的~例如: float w = PTree.get<float>( "root.size.width" ); 這樣的寫法,就會把 width 的 500 從字串轉換成浮點數,而 w 的值就會是 500.0f;如此一來,在讀取資料的同時,也就可以同時做好資料型別轉換的動作、算是非常方便的~ 不過要注意的是,這種用法在找不到指定的路徑的值、或者型別無法正確轉換的時候,會丟出 exception 來,告訴你資料有問題、無法讀取。 如果想要避免 exception 的話,可以考慮加上第二個參數、來當作預設值,這樣在讀取不到資料的時候,就自動用所給的預設值來替代。 float d1 = PTree.get<float>( "root.size.depth", 500.0f ); float d2 = PTree.get<float>( "root.size.depth" ); 像上面這樣的寫法,由於 XML 資料本身並不包含 depth 的資料,所以 d1 會是得到預設的 500.0f;但是 d2 的時候,則會因為找不到 depth,所以丟出 exception、中斷程式的執行。 除了這兩種方法外,其實 Property Tree 也還可以合併 Boost 的 Opetional 這個函式庫(文件),使用 get_optional() 這個函式、來讀取不一定存在的資料,不過這邊就先不提了。 而要寫入資料該怎麼辦呢?如果是要寫入 ptree 這個節點本身的資料的話,直接使用 put_value() 這個函式就可以了(基本上可以視作對應讀取用的 data());另外,他也可以像 get() 一樣,使用 put() 這個含式、直接去設定這顆樹下面某個節點的值。下面就是一把 width 的值從 500 改成 250 的例子。 PTree.put( "root.size.width", 250 );
另外要注意的是,在使用 put() 的時候,如果路徑指定的節點存在的話,他會把本來的值改掉;但是如果指定的節點不存在的話,他是會把這些本來不存在的節點建立出來,然後再賦予它指定的值的。 而相較於此,ptree 也還有提供一個 add() 的函式,可以強制建立出新的節點;也就是說,就算路徑所指定名稱的節點本來就已經存在了,他還是會再建立一個名稱一模一樣的節點。基本上,應該是不建議這樣使用啦~有興趣的話,可以自己玩看看。 而除了這些函式之外,Property Tree 也還有像是 get_child() 和 put_child() 這類的函式,可以取得特定路徑的節點(ptree)、而非取得該節點的值,不過在這邊就不多提了。
恩,Boost 的 Property Tree 這篇就先寫到這了,基本上內容已經寫的比 Heresy 預期的多不少了…而整個寫完,也又發現不少 Heresy 在用的時候,沒有注意到的地方。 整體來說,Heresy 覺得 Boost 的 Property Tree 對於樹狀結構的資料存取來說,應該算是一個相當強大的資料結構,尤其是根據路徑來做存取的功能,在很多地方應該都算是滿實用的~而如果要拿來做 JSON、INI、XML 或是自訂格式的檔案之間的轉換、應該也會是滿實用的東西。 目前 Heresy 這邊應該是會先把它當作 XML 的 Paser 來用吧~之後可能也會再看看還有沒有什麼其他地方用的到, :) 附註:
|

















05-01
 1880
1880
1880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









