






数组
Java 语言中提供的数组是用来存储固定大小的同类型元素。
你可以声明一个数组变量,如 numbers[100] 来代替直接声明 100 个独立变量 number0,number1,…,number99。
声明数组变量
首先必须声明数组变量,才能在程序中使用数组。下面是声明数组变量的语法:
dataType[] arrayRefVar; // 首选的方法
double[] myList;
或
dataType arrayRefVar[]; // 效果相同,但不是首选方法
double myList[];
//创建数组
arrayRefVar = new dataType[arraySize];
//数组变量的声明,和创建数组
dataType[] arrayRefVar = new dataType[arraySize];
处理数组
数组的元素类型和数组的大小都是确定的,所以当处理数组元素时候,我们通常使用基本循环或者 For-Each 循环。
多维数组
多维数组可以看成是数组的数组,比如二维数组就是一个特殊的一维数组,其每一个元素都是一个一维数组,例如:
String[][] str = new String[3][4];
Arrays 类
java.util.Arrays 类能方便地操作数组,它提供的所有方法都是静态的。
具有以下功能:
- 给数组赋值:通过 fill 方法。
- 对数组排序:通过 sort 方法,按升序。
- 比较数组:通过 equals 方法比较数组中元素值是否相等。
- 查找数组元素:通过 binarySearch 方法能对排序好的数组进行二分查找法操作。
具体说明请查看下表:
| 序号 | 方法和说明 |
|---|---|
| 1 | public static int binarySearch(Object[] a, Object key) 用二分查找算法在给定数组中搜索给定值的对象(Byte,Int,double等)。数组在调用前必须排序好的。如果查找值包含在数组中,则返回搜索键的索引;否则返回 (-(插入点) - 1)。 |
| 2 | public static boolean equals(long[] a, long[] a2) 如果两个指定的 long 型数组彼此相等,则返回 true。如果两个数组包含相同数量的元素,并且两个数组中的所有相应元素对都是相等的,则认为这两个数组是相等的。换句话说,如果两个数组以相同顺序包含相同的元素,则两个数组是相等的。同样的方法适用于所有的其他基本数据类型(Byte,short,Int等)。 |
| 3 | public static void fill(int[] a, int val) 将指定的 int 值分配给指定 int 型数组指定范围中的每个元素。同样的方法适用于所有的其他基本数据类型(Byte,short,Int等)。 |
| 4 | public static void sort(Object[] a) 对指定对象数组根据其元素的自然顺序进行升序排列。同样的方法适用于所有的其他基本数据类型(Byte,short,Int等)。 |
集合
数组的缺点
储存数据个数不确定:数组定长;有序存储,不方便添加移除数据;不能存储键值对。
集合类关系图
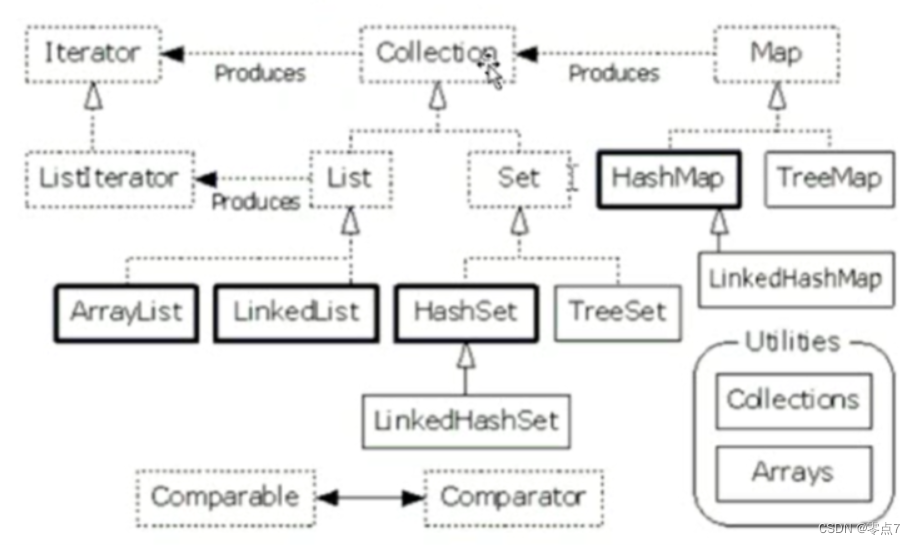
| 类型 | 描述 |
|---|---|
| Collection | Collection 是最基本的集合接口,一个 Collection 代表一组 Object,即 Collection 的元素, Java不提供直接继承自Collection的类,只提供继承于的子接口(如List和set)。 Collection 接口存储一组不唯一,无序的对象。 |
| List接口 | List接口是一个有序的 Collection,使用此接口能够精确的控制每个元素插入的位置,能够通过索引(元素在List中位置,类似于数组的下标)来访问List中的元素,第一个元素的索引为 0,而且允许有相同的元素。 List 接口存储一组不唯一,有序(插入顺序)的对象。 |
| set | Set 具有与 Collection 完全一样的接口,只是行为上不同,Set 不保存重复的元素。 Set 接口存储一组唯一,无序的对象。 |
Set和List的区别
- Set 接口实例存储的是无序的,不重复的数据。List 接口实例存储的是有序的,可以重复的元素。
- Set 检索效率低下,删除和插入效率高,插入和删除不会引起元素位置改变 <实现类有HashSet,TreeSet>。
- List 和数组类似,可以动态增长,根据实际存储的数据的长度自动增长 List 的长度。查找元素效率高,插入删除效率低,因为会引起其他元素位置改变 <实现类有ArrayList,LinkedList,Vector> 。
ArrayList
ArrayList 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。
ArrayList 继承了 AbstractList ,并实现了 List 接口。
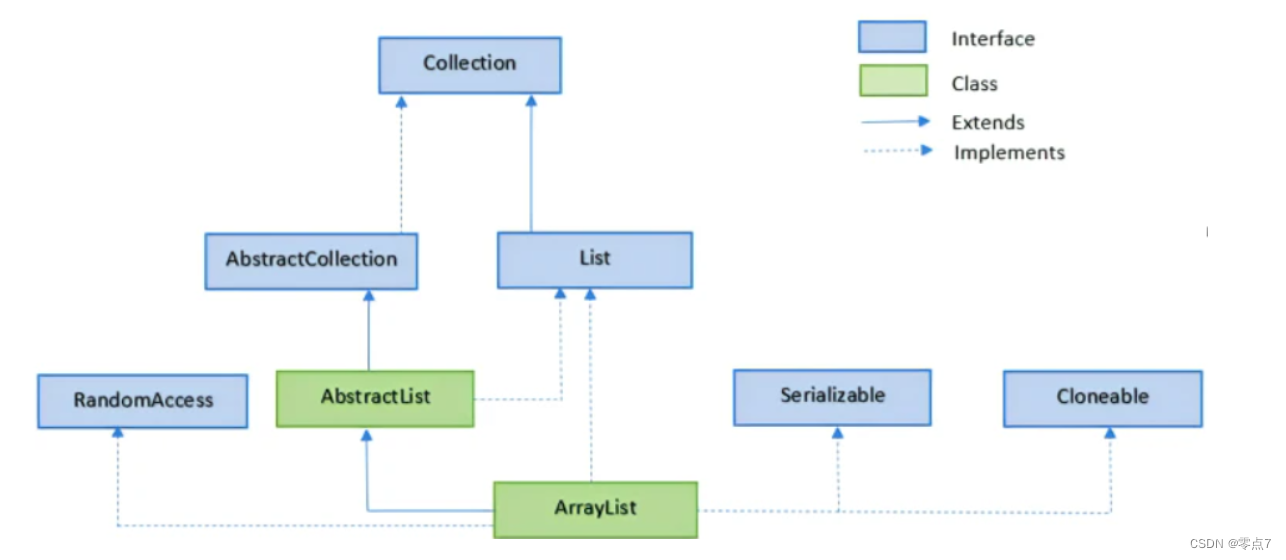
ArrayList 初始化
import java.util.ArrayList; // 引入 ArrayList 类
ArrayList<E> objectName =new ArrayList<>(); // 初始化
- E: 泛型数据类型,用于设置 objectName 的数据类型,只能为引用数据类型。
- objectName: 对象名。
方法
| 方法 | 描述 |
|---|---|
| add() | 将元素插入到指定位置的 arraylist 中 |
| addAll() | 添加集合中的所有元素到 arraylist 中 |
| clear() | 删除 arraylist 中的所有元素 |
| clone() | 复制一份 arraylist |
| contains() | 判断元素是否在 arraylist |
| get() | 通过索引值获取 arraylist 中的元素 |
| indexOf() | 返回 arraylist 中元素的索引值 |
| removeAll() | 删除存在于指定集合中的 arraylist 里的所有元素 |
| remove() | 删除 arraylist 里的单个元素 |
| size() | 返回 arraylist 里元素数量 |
| isEmpty() | 判断 arraylist 是否为空 |
| subList() | 截取部分 arraylist 的元素 |
| set() | 替换 arraylist 中指定索引的元素 |
| sort() | 对 arraylist 元素进行排序 |
| toArray() | 将 arraylist 转换为数组 |
| toString() | 将 arraylist 转换为字符串 |
| ensureCapacity() | 设置指定容量大小的 arraylist |
| lastIndexOf() | 返回指定元素在 arraylist 中最后一次出现的位置 |
| retainAll() | 保留 arraylist 中在指定集合中也存在的那些元素 |
| containsAll() | 查看 arraylist 是否包含指定集合中的所有元素 |
| trimToSize() | 将 arraylist 中的容量调整为数组中的元素个数 |
| removeRange() | 删除 arraylist 中指定索引之间存在的元素 |
| replaceAll() | 将给定的操作内容替换掉数组中每一个元素 |
| removeIf() | 删除所有满足特定条件的 arraylist 元素 |
| forEach() | 遍历 arraylist 中每一个元素并执行特定操作 |
去重
1、双重for循环
for (int i = 0; i < list.size(); i++) {
for (int j = 0; j < list.size(); j++) {
if(i!=j&&list.get(i)==list.get(j)) {
list.remove(list.get(j));
}
}
}
2、利用List集合的contains方法循环遍历,清空,重新添加
private static void removeDuplicate(List<String> list) {
List<String> result = new ArrayList<String>(list.size());
for (String str : list) {
if (!result.contains(str)) {
result.add(str);
}
}
list.clear();
list.addAll(result);
}
3、利用HashSet不能重复的特性,但由于HashSet不能保证顺序,所以只能判断条件保证顺序
private static void removeDuplicate(List<String> list) {
HashSet<String> set = new HashSet<String>(list.size());
List<String> result = new ArrayList<String>(list.size());
for (String str : list) {
if (set.add(str)) {
result.add(str);
}
}
list.clear();
list.addAll(result);
}
14、使用java8特性的stream进行List去重
要从arraylist中删除重复项,我们也可以使用java 8 stream api。
使用steam的distinct()方法返回一个由不同数据组成的流,通过对象的equals()方法进行比较。收集所有区域数据List使用Collectors.toList()。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<Integer> numbersList = new ArrayList<>(Arrays.asList(1, 1, 2, 3, 3, 3, 4, 5, 6, 6, 6, 7, 8));
System.out.println(numbersList);
List<Integer> listWithoutDuplicates = numbersList.stream().distinct().collect(Collectors.toList());
System.out.println(listWithoutDuplicates);
}
}
5、(最佳)使用LinkedHashSet删除ArrayList中的重复数据
LinkedHashSet是在一个ArrayList删除重复数据的最佳方法。
LinkedHashSet在内部完成两件事:
删除重复数据
保持添加到其中的数据的顺序
遍历
System.out.print("普通for循环:");
//write your code here.....
for(int i=0;i<list.size();i++){
System.out.print(list.get(i)+"");
}
system.out.print("增强for循环:");
//write your code here......
for(int i:list){
System.out.print(i+"");
}
system.out .println();
system.out.print("迭代器遍历:");
//write your code here.....
Iterator iterator = list.iterator();
while(iterator.hasNext()){
System.out.print(iterator.next()+" ");
}
LinkedList
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的地址。
链表可分为单向链表和双向链表。
一个单向链表包含两个值: 当前节点的值和一个指向下一个节点的链接。

一个双向链表有三个整数值: 数值、向后的节点链接、向前的节点链接。

Java LinkedList(链表) 类似于 ArrayList,是一种常用的数据容器。
与 ArrayList 相比,LinkedList 的增加和删除的操作效率更高,而查找和修改的操作效率较低。
以下情况使用 ArrayList :
- 频繁访问列表中的某一个元素。
- 只需要在列表末尾进行添加和删除元素操作。
以下情况使用 LinkedList :
- 你需要通过循环迭代来访问列表中的某些元素。
- 需要频繁的在列表开头、中间、末尾等位置进行添加和删除元素操作。
常用方法
| 方法 | 描述 |
|---|---|
| public boolean add(E e) | 链表末尾添加元素,返回是否成功,成功为 true,失败为 false。 |
| public void add(int index, E element) | 向指定位置插入元素。 |
| public boolean addAll(Collection c) | 将一个集合的所有元素添加到链表后面,返回是否成功,成功为 true,失败为 false。 |
| public boolean addAll(int index, Collection c) | 将一个集合的所有元素添加到链表的指定位置后面,返回是否成功,成功为 true,失败为 false。 |
| public void addFirst(E e) | 元素添加到头部。 |
| public void addLast(E e) | 元素添加到尾部。 |
| public boolean offer(E e) | 向链表末尾添加元素,返回是否成功,成功为 true,失败为 false。 |
| public boolean offerFirst(E e) | 头部插入元素,返回是否成功,成功为 true,失败为 false。 |
| public boolean offerLast(E e) | 尾部插入元素,返回是否成功,成功为 true,失败为 false。 |
| public void clear() | 清空链表。 |
| public E removeFirst() | 删除并返回第一个元素。 |
| public E removeLast() | 删除并返回最后一个元素。 |
| public boolean remove(Object o) | 删除某一元素,返回是否成功,成功为 true,失败为 false。 |
| public E remove(int index) | 删除指定位置的元素。 |
| public E poll() | 删除并返回第一个元素。 |
| public E remove() | 删除并返回第一个元素。 |
| public boolean contains(Object o) | 判断是否含有某一元素。 |
| public E get(int index) | 返回指定位置的元素。 |
| public E getFirst() | 返回第一个元素。 |
| public E getLast() | 返回最后一个元素。 |
| public int indexOf(Object o) | 查找指定元素从前往后第一次出现的索引。 |
| public int lastIndexOf(Object o) | 查找指定元素最后一次出现的索引。 |
| public E peek() | 返回第一个元素。 |
| public E element() | 返回第一个元素。 |
| public E peekFirst() | 返回头部元素。 |
| public E peekLast() | 返回尾部元素。 |
| public E set(int index, E element) | 设置指定位置的元素。 |
| public Object clone() | 克隆该列表。 |
| public Iterator descendingIterator() | 返回倒序迭代器。 |
| public int size() | 返回链表元素个数。 |
| public ListIterator listIterator(int index) | 返回从指定位置开始到末尾的迭代器。 |
| public Object[] toArray() | 返回一个由链表元素组成的数组。 |
| public T[] toArray(T[] a) | 返回一个由链表元素转换类型而成的数组。 |
HashMap
- HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
- HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,不支持线程同步。
- ConcurrentHashMap时线程安全的
- HashMap 是无序的,即不会记录插入的顺序。
- HashMap 继承于AbstractMap,实现了 Map、Cloneable、java.io.Serializable 接口。
- 健可以为null或者“”,只能一个
以下实例我们创建一个 HashMap 对象 Sites, 整型(Integer)的 key 和字符串(String)类型的 value:
HashMap<Integer, String> Sites = new HashMap<Integer, String>();
Java HashMap 常用方法列表如下:
| 方法 | 描述 |
|---|---|
| clear() | 删除 hashMap 中的所有键/值对 |
| clone() | 复制一份 hashMap |
| isEmpty() | 判断 hashMap 是否为空 |
| size() | 计算 hashMap 中键/值对的数量 |
| put() | 将键/值对添加到 hashMap 中 |
| putAll() | 将所有键/值对添加到 hashMap 中 |
| putIfAbsent() | 如果 hashMap 中不存在指定的键,则将指定的键/值对插入到 hashMap 中。 |
| remove() | 删除 hashMap 中指定键 key 的映射关系 |
| containsKey() | 检查 hashMap 中是否存在指定的 key 对应的映射关系。 |
| containsValue() | 检查 hashMap 中是否存在指定的 value 对应的映射关系。 |
| replace() | 替换 hashMap 中是指定的 key 对应的 value。 |
| replaceAll() | 将 hashMap 中的所有映射关系替换成给定的函数所执行的结果。 |
| get() | 获取指定 key 对应对 value |
| getOrDefault() | 获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值 |
| forEach() | 对 hashMap 中的每个映射执行指定的操作。 |
| entrySet() | 返回 hashMap 中所有映射项的集合集合视图。 |
| keySet() | 返回 hashMap 中所有 key 组成的集合视图。 |
| values() | 返回 hashMap 中存在的所有 value 值。 |
| merge() | 添加键值对到 hashMap 中 |
| compute() | 对 hashMap 中指定 key 的值进行重新计算 |
| computeIfAbsent() | 对 hashMap 中指定 key 的值进行重新计算,如果不存在这个 key,则添加到 hasMap 中 |
| computeIfPresent() | 对 hashMap 中指定 key 的值进行重新计算,前提是该 key 存在于 hashMap 中。 |
遍历
for (Map.Entry<String, String> entry : map.entrySet()) {
String mapKey = entry.getKey();
String mapValue = entry.getValue();
System.out.println(mapKey + ":" + mapValue);
}
Iterator<Entry<String, String>> entries = map.entrySet().iterator();
while (entries.hasNext()) {
Entry<String, String> entry = entries.next();
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + ":" + value);
}
for(String key : map.keySet()){
String value = map.get(key);
System.out.println(key+":"+value);
}
注意:
- key和value可以同时为null
- key为空,把数据存储到索引值为0的位置
- 可以为空只能存一次,存在第一个位置
key和value可以为list ;但是key的list不可在变;如果作为健的集合内容发生改变,会产生新的key值。key值是根据 列表指向的内存地址以及长度内容生成的hash值 判断是否一致
HashSet
- HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合。
- HashSet 允许有 null 值。
- HashSet 是无序的,即不会记录插入的顺序。
- HashSet 不是线程安全的, 如果多个线程尝试同时修改 HashSet,则最终结果是不确定的。 您必须在多线程访问时显式同步对 HashSet 的并发访问。
方法
| 方法 | 说明 |
|---|---|
| add() | 添加元素 |
| contains() | 使用 contains() 方法来判断元素是否存在于集合当中 |
| remove() | 删除集合中的元素 |
| clear | 删除集合中所有元素 |
| size() | 计算 HashSet 中的元素数量 |















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









