







十、拼接字段
select concat( mid ,"+",book_name ) from booktemp ;
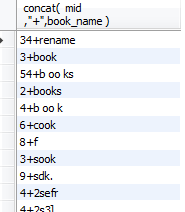
//对拼接的列命名as+名字
select concat( mid ,"+",book_name ) as newname from booktemp ;
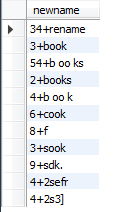
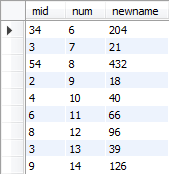
两列数据计算±*/
select mid *num as newname from booktemp ;
十一、数据处理函数
| 名称 | 调用示例 | 示例结果 | 描述 |
|---|---|---|---|
| LEFT | LEFT(‘abc123’, 3) | abc | 返回从左边取指定长度的子串 |
| RIGHT | RIGHT(‘abc123’, 3) | 123 | 返回从右边取指定长度的子串 |
| LENGTH | LENGTH(‘abc’) | 3 | 返回字符串的长度 |
| LOWER | LOWER(‘ABC’) | abc | 返回小写格式字符串 |
| UPPER | UPPER(‘abc’) | ABC | 返回大写格式字符串 |
| LTRIM | LTRIM(’ abc’) | abc | 将字符串左边空格去除后返回 |
| RTRIM | RTRIM('abc ') | abc | 将字符串右边空格去除后返回 |
| SUBSTRING | SUBSTRING(‘abc123’, 2, 3) | bc1 | 从字符串第2位开始截取3位字符 |
| CONCAT | CONCAT(‘abc’, ‘123’, ‘xyz’) | abc123xyz | 将各个字符串参数拼接成一个新的字符串 |
select book_name,concat( mid ,"+",ltrim( book_name) ) as newname from booktemp ;
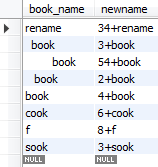
处理日期和时间函数
YEAR(DATE)
返回日期的年份。
MONTH(DATE)
返回日期的月份
DAY(DATE)
返回日期的日
HOUR(time)
返回时间的小时。 对于一天时间值,返回值的范围是0到23。 但是,TIME值的范围实际上要大得多,所以HOUR可以返回大于23的值。
MINUTE(time)
返回时间分钟,范围为0到59。
SECOND(time)
返回时间秒数,范围为0到59。
SELECT YEAR('2018-05-20'); # 2018
SELECT YEAR(20180520); # 2018
SELECT MONTH('2018-05-20'); # 5
SELECT DAY('2018-05-20'); # 20
SELECT hour('12:13:14'); # 12
SELECT hour('122:13:14'); # 122
SELECT hour('12-13-14'); # 0
SELECT hour('2008-09-10 12:13:14'); # 12
SELECT hour('2008-09-10 122:13:14'); # null
SELECT hour('2008-09-10 12-13-14'); # 12
SELECT minute('12:13:14'); # 13
SELECT minute('12:60:14'); # null
SELECT minute('12-13-14'); # 0
SELECT minute('2008-09-10 12:13:14'); # 13
SELECT minute('2008-09-10 122:13:14'); # null
SELECT minute('2008-09-10 12-13-14'); # 13
SELECT second('12:13:14'); # 14
SELECT second('12:13:60'); # null
SELECT second('12-13-14'); # 12
SELECT second('2008-09-10 12:13:14'); # 14
SELECT second('2008-09-10 122:13:14'); # null
SELECT second('2008-09-10 12-13-14'); # 14
SELECT NOW();
SELECT CURRENT_TIMESTAMP();
SELECT CURRENT_TIMESTAMP;
SELECT LOCALTIME();
SELECT LOCALTIME;
SELECT LOCALTIMESTAMP();
SELECT LOCALTIMESTAMP;
注意:
SELECT SYSDATE();
-- sysdate() 日期时间函数跟 now() 类似,
-- 不同之处在于:now() 在执行开始时值就得到了;sysdate() 在函数执行时动态得到值。
-- 看下面的例子就明白了:
SELECT NOW(), SLEEP(3), NOW();
SELECT SYSDATE(), SLEEP(3), SYSDATE();
SELECT CURDATE();-- 当前日期
SELECT CURRENT_DATE();-- 当前日期:等同于 CURDATE()
SELECT CURRENT_DATE;-- 当前日期:等同于 CURDATE()
SELECT CURTIME();-- 当前时间
SELECT CURRENT_TIME();-- 当前时间:等同于 CURTIME()
SELECT CURRENT_TIME;-- 当前时间:等同于 CURTIME()
-- 获得当前 UTC 日期时间函数
SELECT UTC_TIMESTAMP(), UTC_DATE(), UTC_TIME()
-- MySQL 获得当前时间戳函数:current_timestamp, current_timestamp()
SELECT CURRENT_TIMESTAMP, CURRENT_TIMESTAMP();-- 2017-05-15 10:32:21 | 2017-05-15 10:32:21
常用数值处理函数
| 函数 | 说明 |
|---|---|
| Abs() | 返回一个数的绝对值 |
| Cos() | 返回一个角度的余弦 |
| Exp() | 返回一个数的指数值 |
| Mod() | 返回除操作的余数 |
| Pi() | 返回圆周率 |
| Rand() | 返回一个随机数 |
| Sin() | 返回一个角度的正弦 |
| Sqtr() | 返回一个数的平方根 |
| Tan() | 返回一个角度的正切 |
Mysql 聚集函数有5个:
1、COUNT() 记录个数
2、MAX() 最大值
3、MIN() 最小值
4、AVG()平均值
5、SUM() 求和
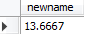
eg 求平均
select avg(mid) as newname from booktemp ;
eg计算列数
select count(*) as newname from booktemp ;
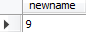
eg:求最大值
select max(mid )as newname from booktemp ;
eg:求和
select sum(mid )as newname from booktemp ;
eg:组合使用,求不同的数据的平均值
select avg (distinct mid) as newname from booktemp ;
十三、数据分组
创建分组
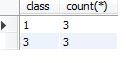
select class,count() from booktemp group by class ;
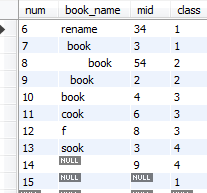
分组结果
count()为组内元素数量
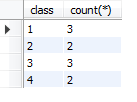
过滤分组,组内数量大于2的
select class,count() from booktemp group by class having count()>2 ;
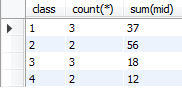
分组经常和聚合函数共同使用
select class,count(*),sum(mid) from booktemp group by class;
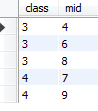
十三、数据的子查询即嵌套查询
eg:
select class,mid from booktemp where mid in( select mid from booktemp where class >2);
十四、 联结表
一 .自然联结
定义:无论何时对表进行联结,应该至少有一个列出现不止一个表中(被联结的列)。标准的联结返回所有数据,甚至相同的列多次出现。自然联结排除多次出现,使每个列只返回一次;(也就是说,自然联结的作用就是排除多次出现,使每个列只返回一次)
文字没描述完了,可能有的同学还不是很理解其中的意思,下面上例子吧,更直观:
例如有表R和表S,表的内容如下:
R表 S表
A B C D B E
1 a 3 2 c 7
2 b 6 3 d 5
3 c 7 1 a 3
现在R和S要进行自然联结
自然联结步骤
1.就是用R表中的每一项乘以S表中的每一项,得到的结果如下
A B C D B E
1 a 3 2 c 7
1 a 3 3 d 5
1 a 3 1 a 3
2 b 6 2 c 7
2 b 6 3 d 5
2 b 6 1 a 3
3 c 7 2 c 7
3 c 7 3 d 5
3 c 7 1 a 3
2.过滤出R.B=S.B的行,结果如下
R.A R.B R.C S.D S.B S.E
1 a 3 1 a 3
3 c 7 2 c 7
3.最后去除一个相同的列,即R.B和S.B其中一个,最后自然联结的结果为
A B C D E
1 a 3 1 3
3 c 7 2 7
二 外联结
表数据:例如有一下两个表,表A和表B
// 表A记录如下
aID aNum
1 a2010
2 a2011
3 a2012
4 a2012
5 a2013
// 表B记录如下:
bID bName
1 b2010
2 b2011
3 b2012
4 b2013
8 b2014
1)左外联结
sql语句:selectfrom A left join B on A.aID = B.bID,这里我们把表A成为左表,表B为右表,
左外联结是以左表为基础的,即left join是以左表为基础的,在这个例子中,左表(表A)的记录全部会显示出来,而表B只显示符合过滤条件的那部分行
2)右外联结
sql语句:selectfrom A right join B on A.aID = B.bID,这里我们把表A成为左表,表B为右表,
右外联结是以右表为基础的,即right join是以右表为基础的,在这个例子中,右表(表B)的记录全部会显示出来,而表A只显示符合过滤条件的那部分行
三 .内联结
内联结最简单,两个表进行内联结,匹配符合过滤条件的行就可以了
例如:select * from A inner join B where A.a = B.a
把表A和表B中的列A相等的所有行都显示出来
1 先新建表tbl_dept
id列为int主键
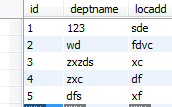
2 建立表newtable
id为int 主键
depid为外键引用自表tbl_dept的id
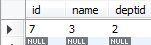
3 内连接查询
select * from tbl_dept a inner join new_table b on a.id=b.deptId;

4左外连接查询
select * from tbl_dept a left join new_table b on a.id=b.deptId;
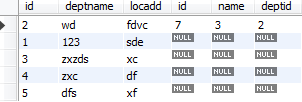
select * from tbl_dept a left join new_table b on a.id=b.deptId where b.deptId is null;
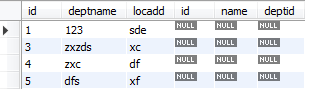
6 右外连接查询
select * from tbl_dept a right join new_table b on a.id=b.deptId;

7、全连接
select * from tbl_dept a left join new_table b on a.id=b.deptId union
select * from tbl_dept a right join new_table b on a.id=b.deptId;
十八、全文本检索
1使用CREATE TABLE语句创建新表时,可以为列定义FULLTEXT索引,如下所示:
CREATE TABLE table_name(
column1 data_type,
column2 data_type,
column3 data_type,
…
PRIMARY_KEY(key_column),
FULLTEXT (column1,column2,…)
);
创建举例表
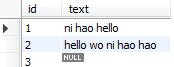
select text from texttable where match (text) against (‘hello’);
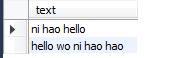
select text , match (text) against (‘hello’) from texttable ;
全文搜索布尔运算符号
下表说明了全文搜索布尔运算符及其含义:
操作符
描述
| 符号 | 描述 |
|---|---|
| + | 包括,这个词必须存在。 |
| - | 排除,这个词不能存在。 |
| > | 包括并增加排名值。 |
| < | 包括并降低排名值。 |
| () | 将单词分组成子表达式(允许将其包括,排除,排序等作为一个组)。 |
| ~ | 否定一个词的排名值。 |
| * | 通配符,在结尾的单词 |
| “” | 定义一个短语(与单个单词列表相反,整个短语匹配包含或排除)。 |
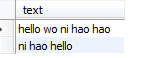
select text from texttable where match (text) against (’+hao ’ in boolean mode);















 8245
8245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









