







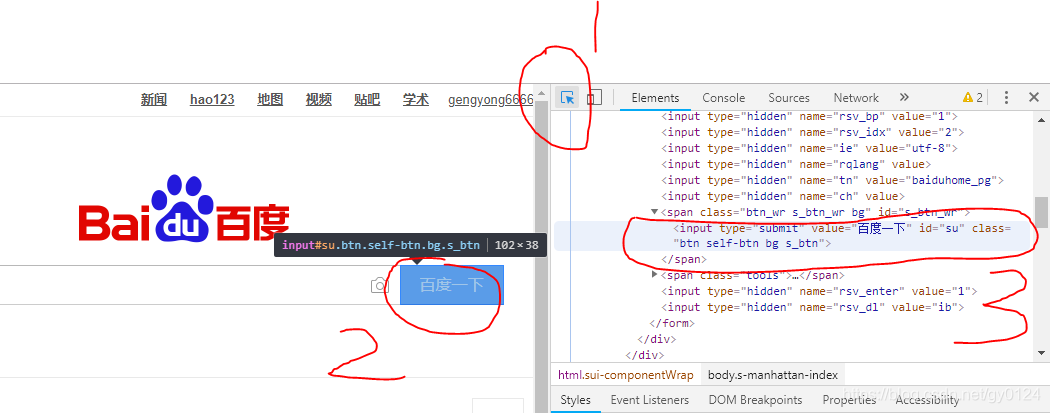
举例:
1,使用谷歌浏览器打开百度网页
2,按F12以开发模式打开
3,如下图鼠标点击1处
4,鼠标移动到需要查看的按钮2处
5,右边框中显示按钮的详细信息(type ,name,id)

















05-20
 2000
2000
2000
06-28
426
426
09-24
举例:
1,使用谷歌浏览器打开百度网页
2,按F12以开发模式打开
3,如下图鼠标点击1处
4,鼠标移动到需要查看的按钮2处
5,右边框中显示按钮的详细信息(type ,name,id)
2000
426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









