










 本文探讨了电商秒杀活动中如何设计和优化高并发、大流量的系统架构,涉及前端压力分散、商品服务、数据库压力管理、缓存使用、限流和降级策略,以及全链路日志系统的重要性。
本文探讨了电商秒杀活动中如何设计和优化高并发、大流量的系统架构,涉及前端压力分散、商品服务、数据库压力管理、缓存使用、限流和降级策略,以及全链路日志系统的重要性。
背景
电商系统的开发中,我们经常涉及到高并发、大流量、高可用架构的设计。尤其是在做活动进行秒杀的时候,会有更多的流量瞬时到达服务器,如果我们没有很好的架构支撑,服务器和数据库就会被瞬间的流量直接弄崩溃。
简述
满足秒杀的系统架构设计确实非常复杂,对于一般的单体架构或者普通的服务来说,随着流量瞬间增加到千万级别,是完全无法应对。当然开发单体架构的小公司可能就3-5人就能完成,对于千万乃至亿级的应用,随着系统的复杂程度呈几何级的增加,研发人员也会成倍的增加。一般研发人员没有足够的经验来进行架构设计。
思考
如果我们系统的会员是 1亿人,每日活跃用户数在1千万,当我们准备做商品秒杀活动前,会通过各种渠道去活动预热,在实际秒杀时间可能会有3千万的用户来参加这次秒杀活动,那我们应该怎么来设计我们的系统呢。
3千万用户进入抢购商品页面,如果每人点击页面3次,每次请求服务器接口的数据是 1kb,假设活动在5分钟完成,那么
5分钟内每秒平均的qps = (30000000 * 3)/ (5 * 60) = 30万qps。
接口请求带宽: (300000 * 1 / 1024 ) = 292 MB = 292 * 8 bit = 2343 Mb
假设平均每台商品应用服务器的qps 按照 1000 来算:
商品服务需要服务器数量 : 300000 / 1000 = 300 (台机器)
redis按照每台 5万 qps 计算:
redis集群内节点数量: 300000 / 50000 = 6 (6主 6 从)
es 按照每台 1000 qps 计算:
es集群数量 : 300000 / 1000 = 30 (台)
mysql 最终选择 一主多从 或者 多主多从
分摊到mysql的压力会非常小,它主要完成两个功能
1、缓存没有数据时,帮忙返回数据
2、用户下单后存下单记录,处理订单后生成订单持久化
为了抗住大流量去设计秒杀系统,必须对各项指标非常熟悉,否则无法下手,我们就来分析下应该如何拆解各项指标。流量增加会影响如下几个指标:
1、带宽压力
2、服务器压力
3、数据库压力
4、缓存压力
5、请求限流
6、服务降级
这几个指标最终会导致服务无响应,系统不可用,那我们应该怎么来一步一步分析和解决上述问题呢?先给大家上一张我画的架构图(很丑),然后继续分析
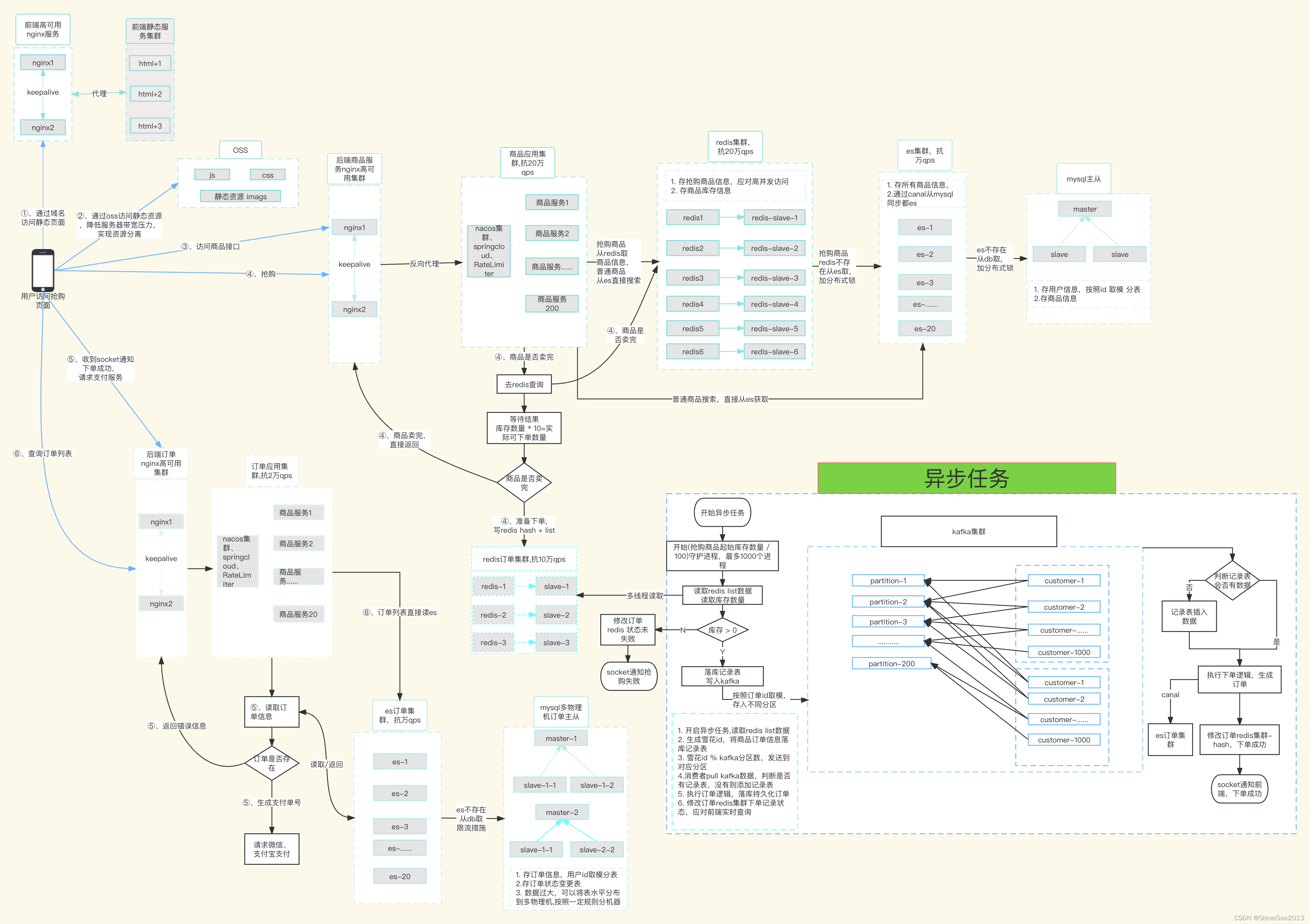
上面这张图,从前端压力拆分、商品服务、商品缓存、订单服务、订单缓存、异步处理几个方面来说明提高系统并发能力的方案。
系统拆分
h5前端-分散带宽压力
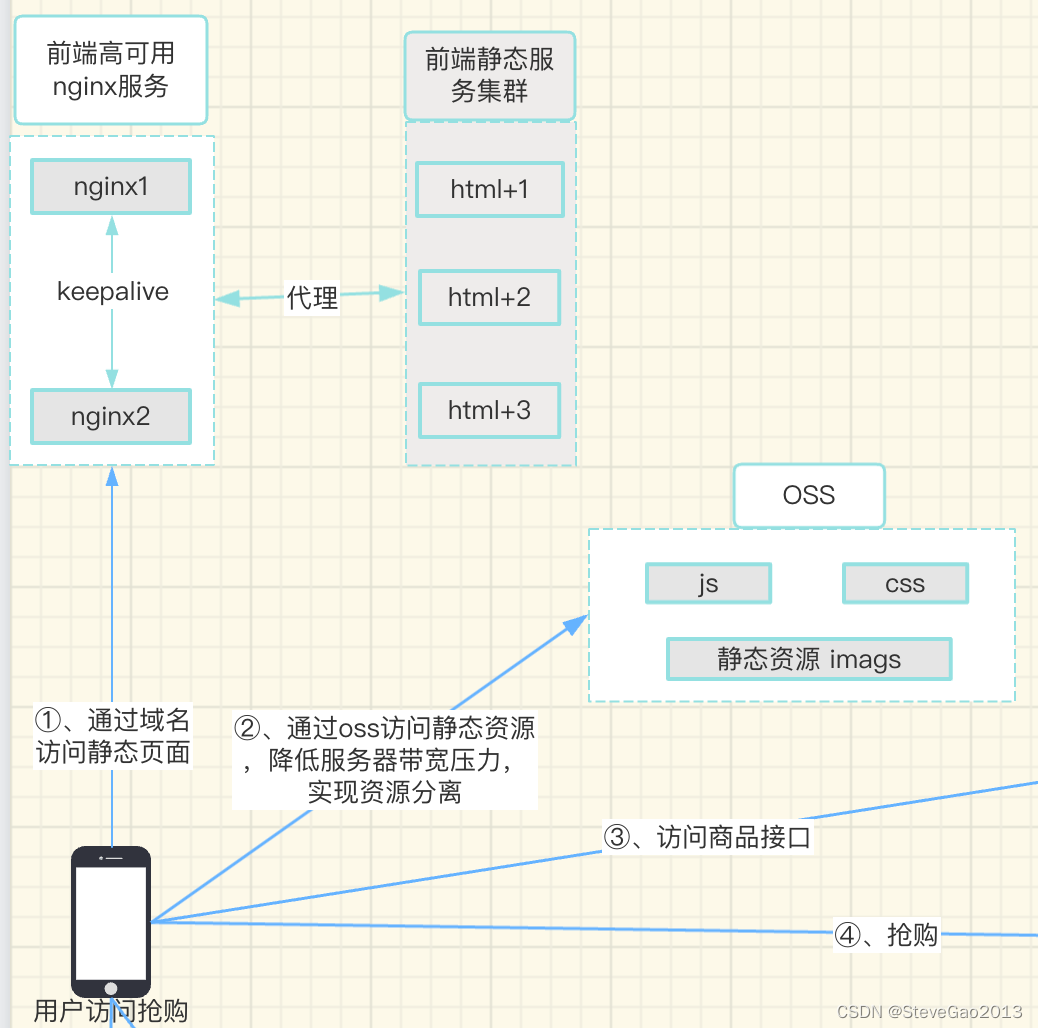
前端的访问效率,决定了用户的容忍度,我们需要对前端做一些针对性的优化,来提高我们的访问效率,主要从下面几个方面入手:
1、js + css + images 单独部署到OSS。
借助OSS 流量计费的规则 来增加我们的响应速度,同时增加cdn 缓存,进一步提高访问效率,我们在每次有数据修改的时候都需要及时刷新cdn 来保证资源的实效性。

技巧: 我们在使用jenkins 发布前端代码的时候,可以用 node.js 写一个程序,直接将资源传到oss上面,vue 和 react 都可以直接使用node.js 来处理。
2、将js+css 压缩到一个文件,减少http请求次数,缩短响应时间。
3、html 文件单独部署到云服务器集群,避免单点故障。
4、nginx服务 配置 keep-alive 来保证访问高可用。
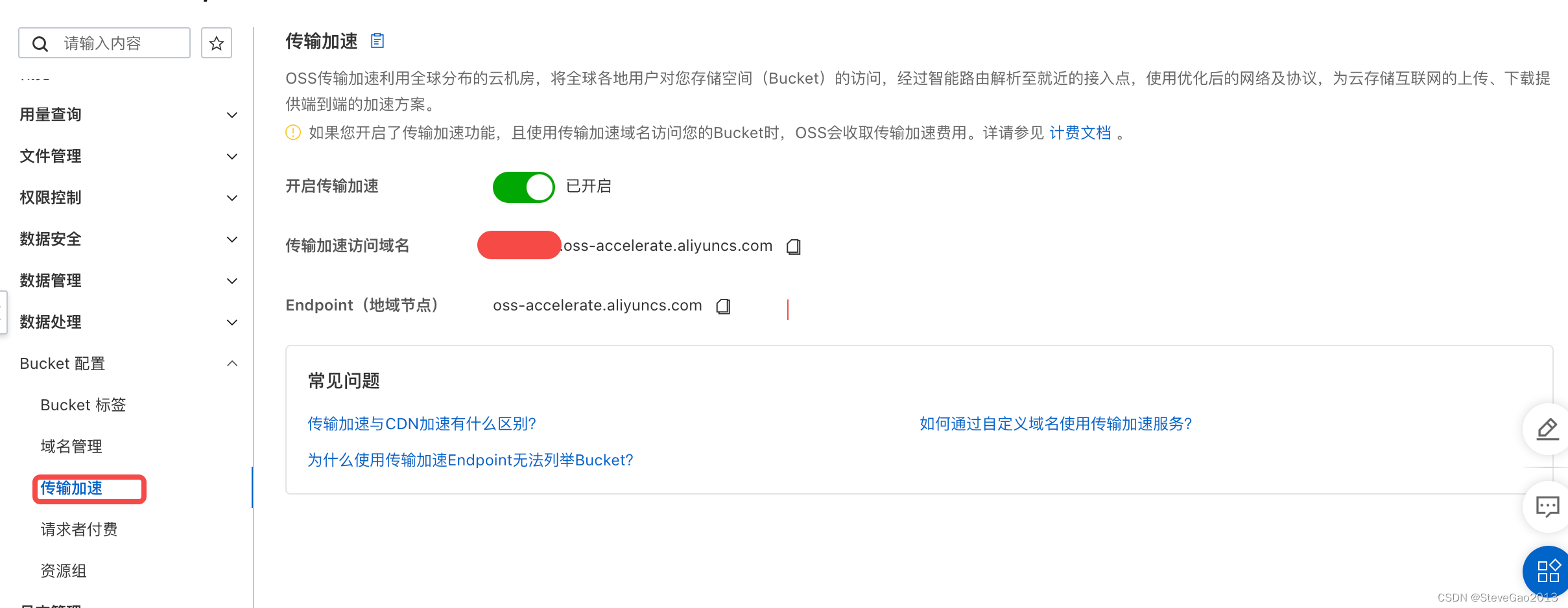
5、可以购买oss的加速域名来进一步提高访问速度,这里以阿里云传输加速举例。
6、商品抢购按钮的优化
用户进入商品抢购页面时,不停的刷新页面行为对抢购没有任何帮助,只会不断的给服务器增加压力。
我们可以禁止用户在商品抢购页刷新,通过倒计时来自动帮助用户点亮抢购按钮。会减少很多无用请求。
商品服务-优化
商品服务的访问:
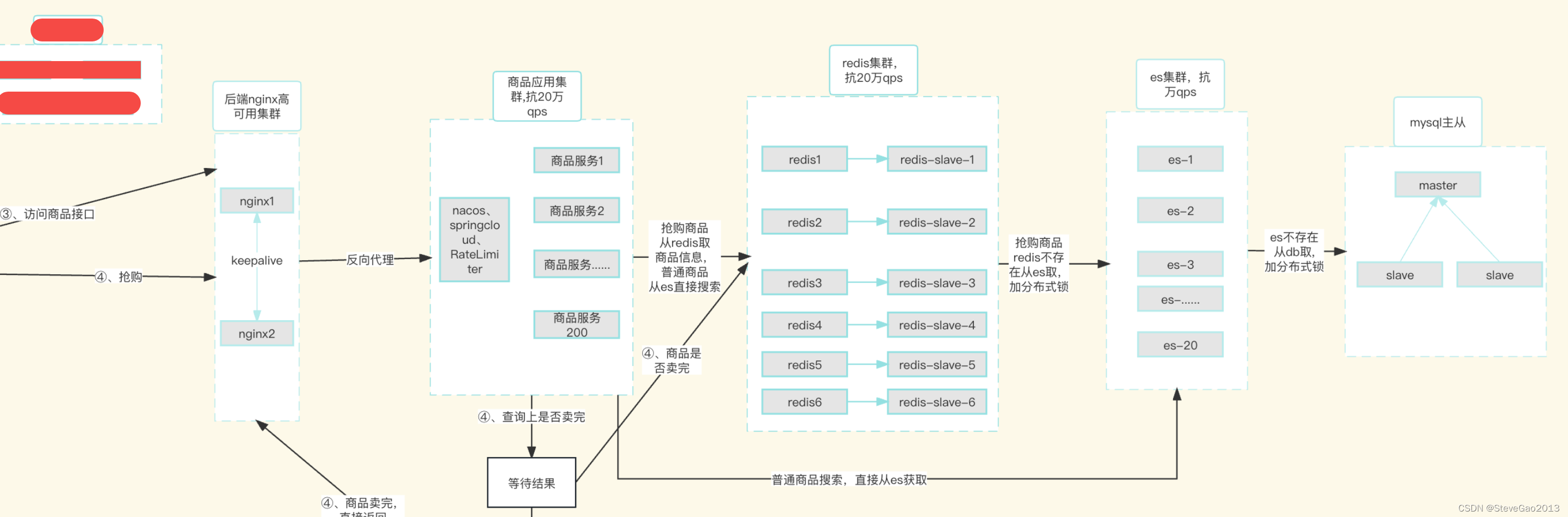
第1步、请求首先到达 F5 或者 其他路由分发。
第2步、nginx 代理服务器
每台nginx 代理服务器(8cpu16g)的 qps 能达到 8-10万左右,我们可以部署3台,然后在nginx上配置后端服务器的地址。多台nginx之间配置 keepalive 来保证nginx的高可用。
第3步、商品应用集群
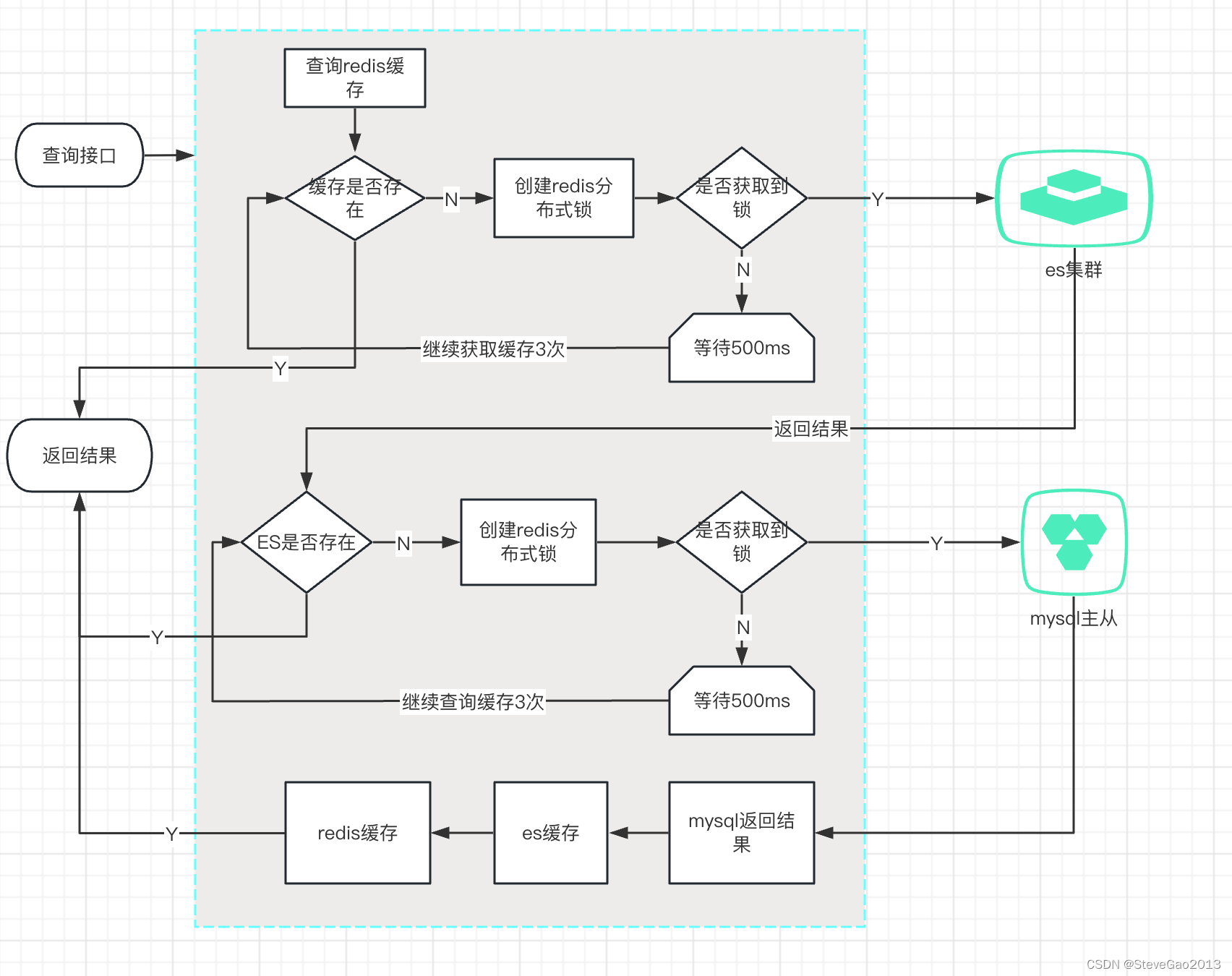
商品接口
商品是否在redis存在,如果redis存在,直接返回
商品在redis 不存在,去查询es ,查询前需要先设置 redis 分布式锁(防止缓存击穿,其他线程或者其他服务器的线程查询时发现已经加锁了,就等待2秒,再去查询),
如果es 存在,直接返回,然后在redis建立缓存,失败分布式锁,并将结果返回。
如果es 不存在,去db查询(防止缓存击穿,其他线程或者其他服务器的线程查询时发现已经加锁了,就等待2秒,再去查询),如果db存在商品数据,返回商品信息,并释放锁,在es建立缓存,返回,并在redis建立锁,最后返回给前端。
流程如下图:
抢购商品
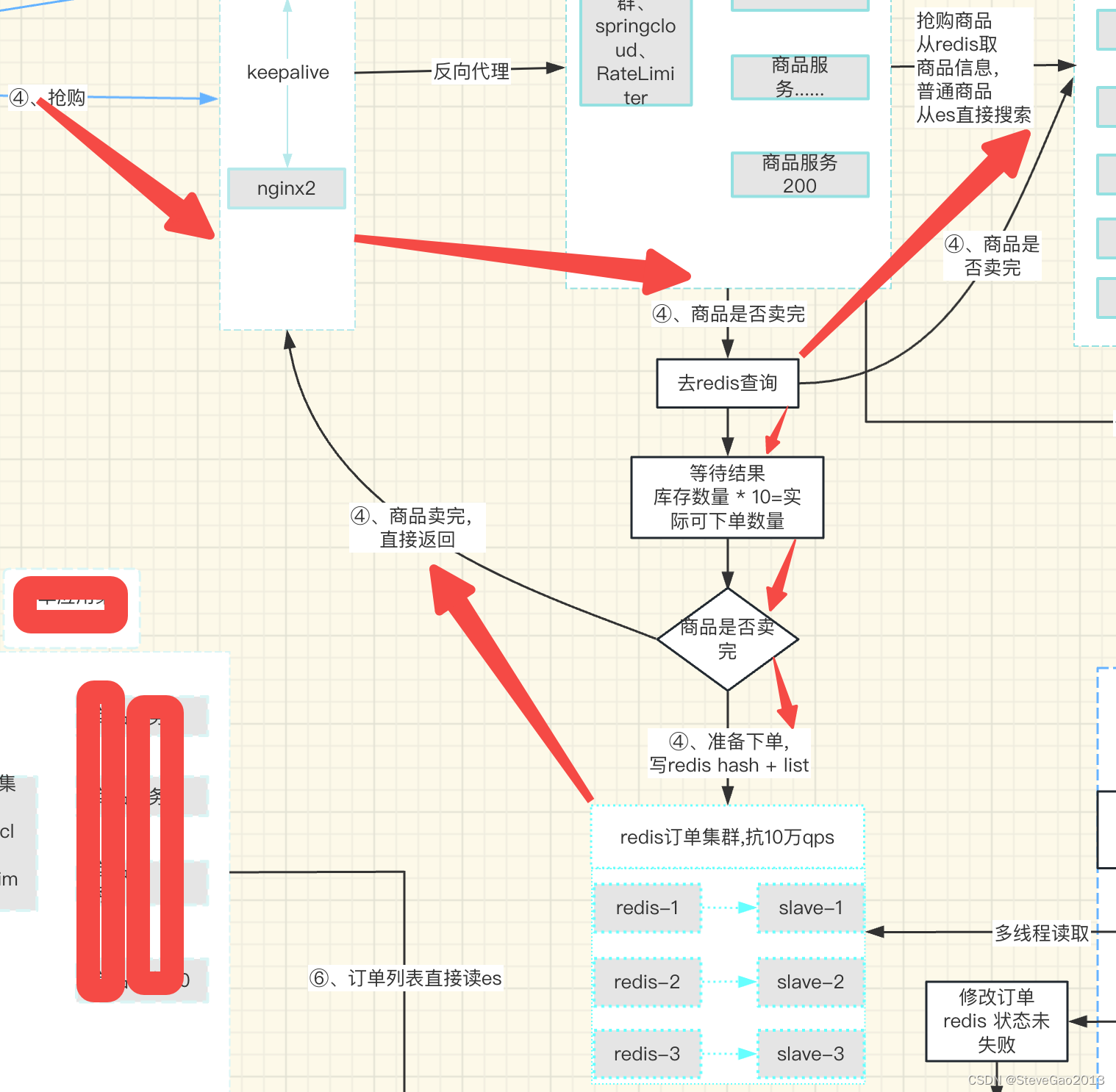
1、访问商品服务接口
2、查询商品库存是否卖完(每次下单成功后,原子更新商品库存,商品可下单库存=商品原始库存*10)
3、如果可以下单,写入订单服务redis hash + (多个list 队列,用户id取模50生成队列),运用redis watch 事务命令。写入完成,返回抢购成功,前端等待异步任务处理完成,收到socket通知后,发起支付。
4、否则直接返回卖完,返回抢购失败。
抢购流程如下:
第4步、服务限流
如果我们每天服务器的极限qps 是1000, 那么如果超过我们极限的流量进来时,我们需要把它直接拒绝掉,以免造成服务不可用。
java 中可以使用 谷歌的 RateLimiter 来进行限流(Google的Guava也实现了基于令牌桶算法那样的平均速率限流)
php-hyperf 中也可以配置 注解来进行简单限流,它的限流是用redis 来实现计数的。
异步任务
瞬间处理大量的订单,如果使用同步处理,会给服务器和数据库造成很大的压力,特别是mysql数据库,所以我们采用异步的方式来处理订单,处理完成后 ,通过socket 推送消息给前端用户,完成支付流程。
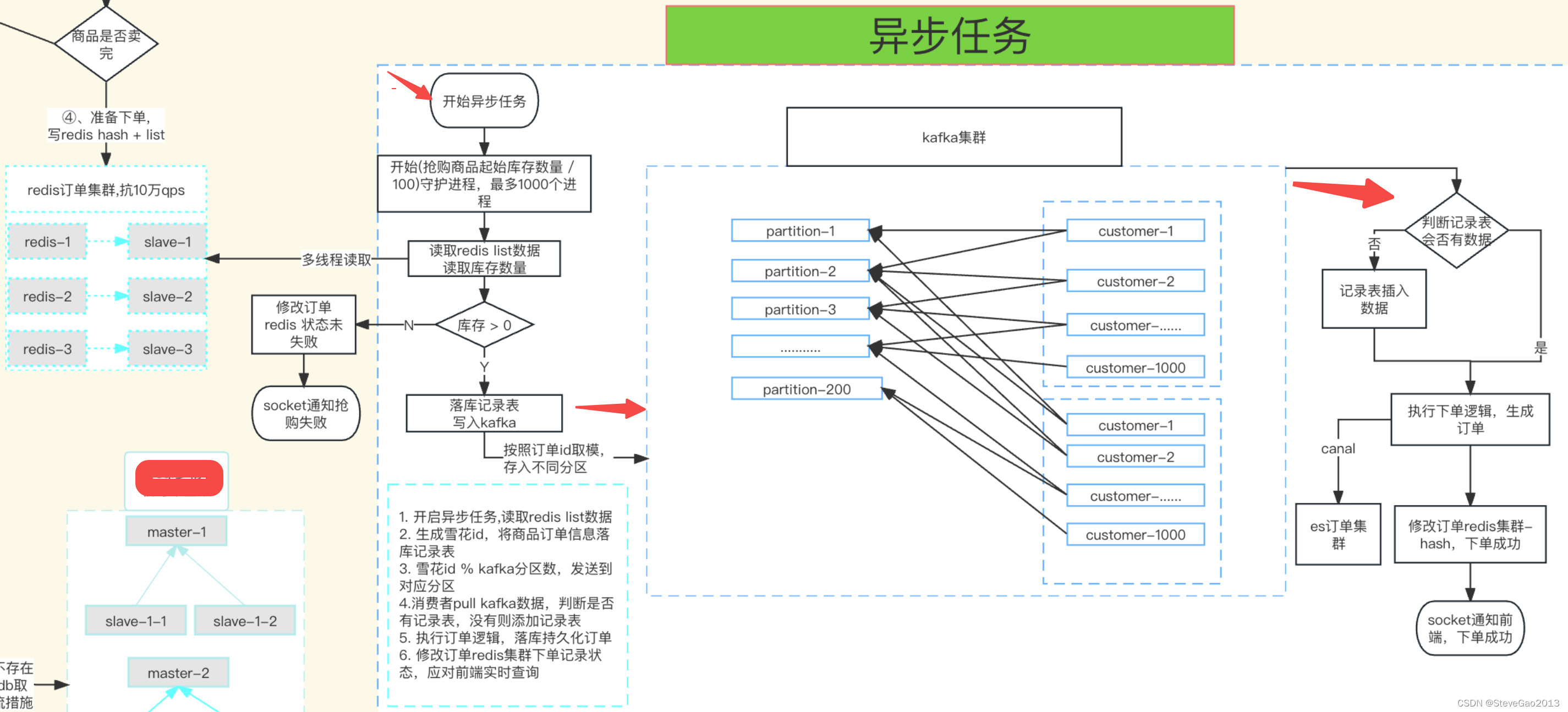
1. 开启异步任务,读取redis list数据,上面是生成50个队列,我们开启异步任务读取这50队列的数据开始消费,因为 redis的list 是原子性的,不存在重复消费的情况。
2. 读取订单redis缓存的商品库存信息,如果库存 > 0, 继续第3步,否则直接结束,socket通知用户抢购失败。
3. 生成雪花id 作为下单记录表(仅仅记录下单的记录,字段很少,不是订单表字段)的主键id,将商品订单信息落库记录表,防止订单在kafka 传输时丢失。
4. 雪花id % kafka分区数,发送到对应分区。(kafka 分区按照实际用量来分配)。
5.消费者pull kafka数据,判断是西单记录表是否有数据,如果有进行第6步,否则添加下单记录表后进行第6步。
6. 执行订单逻辑,落库生成订单,持久化数据, 落库最好使用mysql的乐观锁(在数据表里面加一个version的字段,更新时带上读取时的version去查询)。
7. 修改订单redis集群下单记录状态,应对前端实时查询,同时通过canal (canal 同步mysql binlog 日志到 elasticsearch7_canal日志_SteveGao2013的博客-CSDN博客) 将订单系统同步到es集群。
异步处理流程如下:
订单服务
此处时将商品服务和订单服务分开部署,分开的目的是出于分摊流量和系统稳定性的考量,正常情况下大规模的流量都会交给商品服务,只有下单成功的用户才会进入到订单服务(下单成功的用户非常少)。
前端收到服务端 发送的socket 通知后
1、主动跳转到订单确认页面,拉取订单服务接口,获取订单实时信息
2、点击支付,访问平台支付服务生成支付链接返回给前端
3、跳转到微信、支付宝支付。
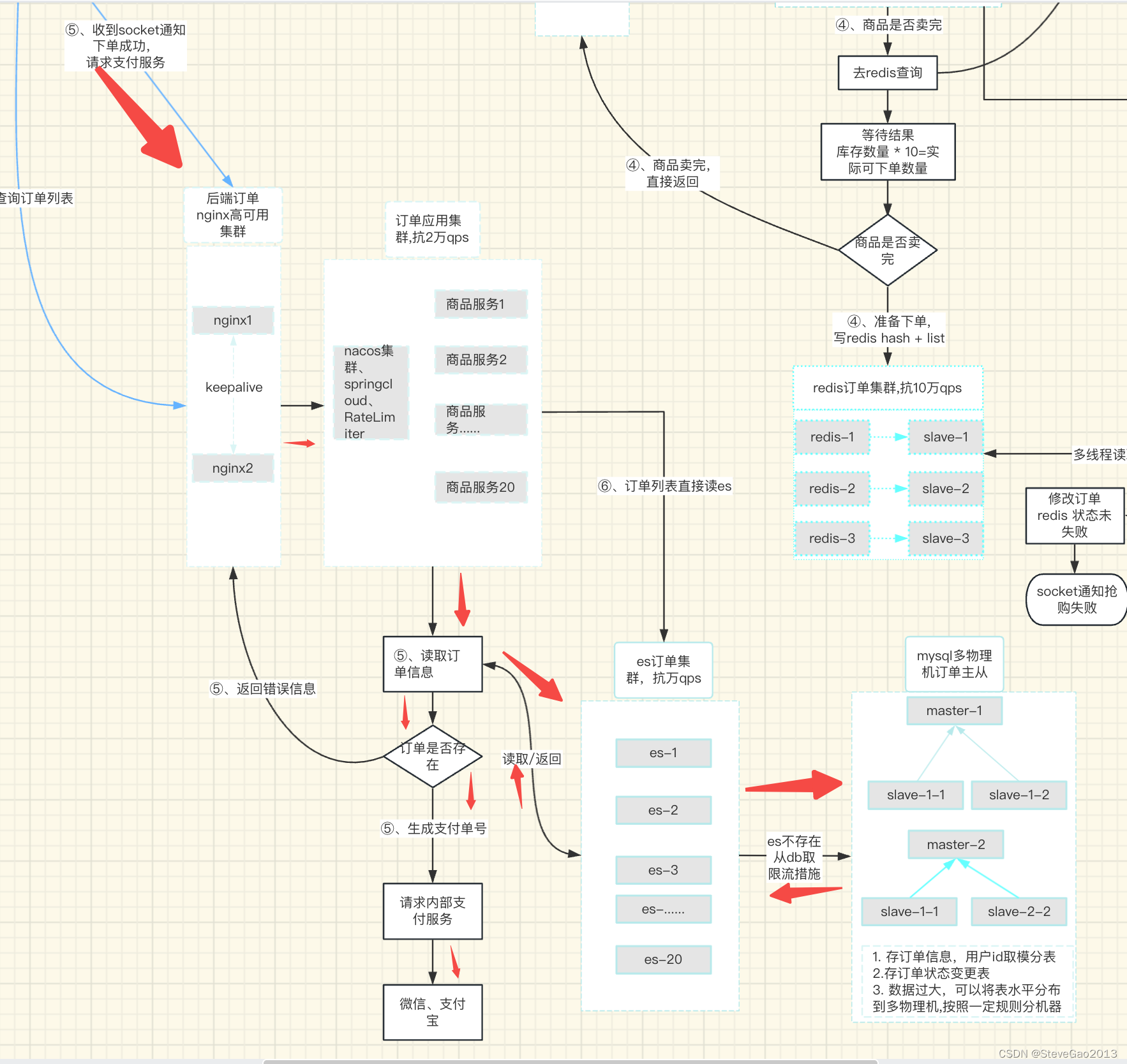
订单列表查询
订单列表我们存在在es中,方便用户查询和搜索。
在hyperf中使用es ,如果自己去拼接json会非常麻烦,不方便而且容易写错,可以参考我这边es的链式操作:php hyperf 使用链式模式 轻松操作elasticsearch 查询_SteveGao2013的博客-CSDN博客
支付异步回调
如果公司有很多服务,我们应该将支付服务 抽离成一个单独的服务,只提供支付能力,不要将支付和其他业务系统集成在一起,这样既影响业务,也影响支付。
当流量很大时,支付回调也会存在并发,我们在处理支付时,也需要采用异步处理的方式来降低内部支付系统的压力。
异步处理的思想和我们订单异步处理的思想是一样的,可以直接使用。
全链路日志
如此庞大的系统,如果在抢购时出现bug,我们需要快速的定位bug并解决问题,没有一个健全的日志系统对我们来说肯定是一个大灾难,下面我就来给大家说下 如何搭建我们的全链路日志系统吧。
日志集成
首先我们要从几个要点去考虑
1、前端发起请求(header 中添加 traceId)
每个独立的页面在请求时,可以不传traceId,后端会自己生成一个traceId,并放在上下文一直传递下去,
访问关联页面时,需要将当前的traceId 放在header的 traceId中发送给后端,这样在出问题时,可以将整个请求链路的日志全部查询出来。
2、服务内部
记录请求日志,请求参数 和 header 信息
记录返回日志,返回的结果也记录下来
程序执行的关键点,需要将日志记录下来方便查询问题
统一处理异常,将异常日志和traceId 记录下来
举例:
php-hyperf 框架,我们可以重写异常类handler,把错误信息和traceId 记录下来
springboot框架,我们可以定义一个切面来将请求和返回日志记录下来,并统一处理异常日志(@RestControllerAdvice)
3、消息队列中间件
我目前的处理方式是在消息体中增加 traceId 字段,消费者在开始消费前把获取到的traceId 写入上下文中。
4、跨服务调用
目前处理是在框架统一调用中心中,将上下文的traceId 写入到请求的 header 中,发送给其他服务,php 使用 guzzle-php 客户端封装, java 请求内部微服务使用 RestTemplate、Feign 写入header,okhttp3 也是封装在header中 调用其他服务。
5、异步任务
异步任务在处理时,也需要生成traceId, 保存在日志中,方便查询问题。
日志收集
目前日志收集我使用的是两种方案。
1、使用阿里云的日志系统
配置简单,开箱即用,维护和扩容很方便。
2、自己搭建elk来采集日志系统。
参考我这篇文章:ELK日志采集系统安装_php elk_SteveGao2013的博客-CSDN博客
预警系统
当生产环境有错误信息时,需要及时的推送到内部bug 处理群,这里推荐使用 飞书的预警机器人 、企业微信的预警群,这样研发人员、测试、运维可以第一时间看到错误信息进行整改,减少排查难度。
服务器预警
服务器cpu、内存、磁盘达到一定的临界值时,我们需要发出预警,让运维或者开发人员可以马上相关提示并进行调整。有很多工具可以实现预警,比如:grafana和prometheus,Falcon,或者自己编写读取指标的脚本。
代码报错
当我们统一处理错误信息后,需要将严重的错误信息发送出来让研发和测试人员马上进行整改。
压力测试
每个服务要达到1000qps 还是需要进行不断优化才能实现,优化中我们需要不断通过压力测试来、验证,压力测试请参考我这边文章:jmeter 并发压力测试_php接口压力测试_SteveGao2013的博客-CSDN博客
redis 集群的搭建
搭建redis集群请参考我这这篇文章:配置redis cluster 并允许外网访问_predis如何配置_SteveGao2013的博客-CSDN博客
如果想要在多台服务器搭建,只需要配置的ip地址 并且完成组集群即可。
如果想要搭建高并发的服务,还需要知道如何优化和拆分 mysql,这里可以参考我下面这篇文章:搭建高并发分布式集群系统思路 实现负载均衡和服务器集群和分布式_SteveGao2013的博客-CSDN博客
分布式事务
当我们服务 越拆越多时,我们需要保证的一致性 就变得尤为重要,我们主要采用最终一致性的方式来保证我们数据准确性。这里我就不赘述了,可以在网上去查询下 阿里 的解决方案。
上面说了很多,有很多小细节 和 技术难点需要在实际开发中不断的学习,不断尝试,不断试错才能完全理解,当然还有很多地方没有考虑到,会出现想象不到的bug,但可以把思路记录下来,碰到问题后,再来继续优化,希望我们能共同进步。

















 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









