







欢迎关注“
计算机视觉研究院
”

计算机视觉研究院专栏
作者:Edison_G

扫描二维码 关注我们
Meta 发布的开源系列模型 LLaMA,将在开源社区的共同努力下发挥出极大的价值。
转自《机器之心》
Meta 在上个月末发布了一系列开源大模型 ——LLaMA(Large Language Model Meta AI),参数量从 70 亿到 650 亿不等。由于模型参数量较少,只需单张显卡即可运行,LLaMA 因此被称为 ChatGPT 的平替。发布以来,已有多位开发者尝试在自己的设备上运行 LLaMA 模型,并分享经验。
虽然相比于 ChatGPT 等需要大量算力资源的超大规模的语言模型,单张显卡的要求已经很低了,但还能更低!最近有开发者实现了在 MacBook 上运行 LLaMA,还有开发者成功在 4GB RAM 的树莓派上运行了 LLaMA 7B。
这些都得益于一个名为 llama.cpp 的新项目,该项目在 GitHub 上线三天,狂揽 4.6k star。
项目地址:https://github.com/ggerganov/llama.cpp
Georgi Gerganov 是资深的开源社区开发者,曾为 OpenAI 的 Whisper 自动语音识别模型开发 whisper.cpp。
这次,llama.cpp 项目的目标是在 MacBook 上使用 4-bit 量化成功运行 LLaMA 模型,具体包括:
没有依赖项的普通 C/C++ 实现;
Apple silicon first-class citizen—— 通过 Arm Neon 和 Accelerate 框架;
AVX2 支持 x86 架构;
混合 F16 / F32 精度;
4-bit 量化支持;
在 CPU 上运行。
llama.cpp 让开发者在没有 GPU 的条件下也能运行 LLaMA 模型。项目发布后,很快就有开发者尝试在 MacBook 上运行 LLaMA,并成功在 64GB M2 MacBook Pro 上运行了 LLaMA 7B 和 LLaMA 13B。
在 M2 MacBook 上运行 LLaMA 的方法:https://til.simonwillison.net/llms/llama-7b-m2
如果 M2 芯片 MacBook 这个条件还是有点高,没关系,M1 芯片的 MacBook 也可以。另一位开发者分享了借助 llama.cpp 在 M1 Mac 上运行 LLaMA 模型的方法。

在 M1 Mac 上运行 LLaMA 的方法:https://dev.l1x.be/posts/2023/03/12/using-llama-with-m1-mac/
除了在 MacBook 上运行,还有开发者借助 llama.cpp 在 4GB RAM Raspberry Pi 4 上成功运行了 LLaMA 7B 模型。Meta 首席 AI 科学家、图灵奖得主 Yann LeCun 也点赞转发了。
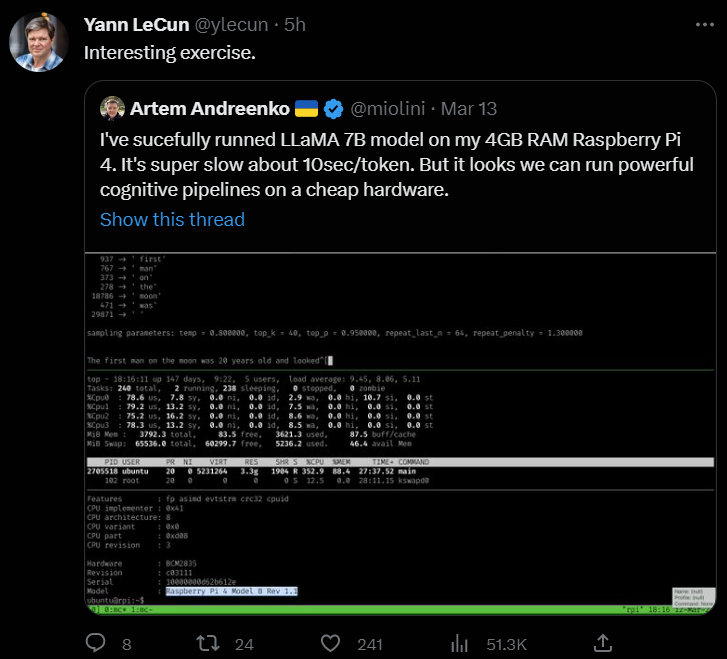
以上是 3 个在普通硬件设备上成功运行 LLaMA 模型的例子,几位开发者都是借助 llama.cpp 实现的,可见 llama.cpp 项目的实用与强大。我们来具体看一下 llama.cpp 的使用方法。
以 7B 模型为例,运行 LLaMA 的大体步骤如下:
# build this repo
git clone https://github.com/ggerganov/llama.cppcd llama.cpp
make
# obtain the original LLaMA model weights and place them in ./models
ls ./models
65B 30B 13B 7B tokenizer_checklist.chk tokenizer.model
# install Python dependencies
python3 -m pip install torch numpy sentencepiece
# convert the 7B model to ggml FP16 format
python3 convert-pth-to-ggml.py models/7B/ 1
# quantize the model to 4-bits
./quantize.sh 7B
# run the inference
./main -m ./models/7B/ggml-model-q4_0.bin -t 8 -n 128运行更大的 LLaMA 模型,需要设备有足够的存储空间来储存中间文件。
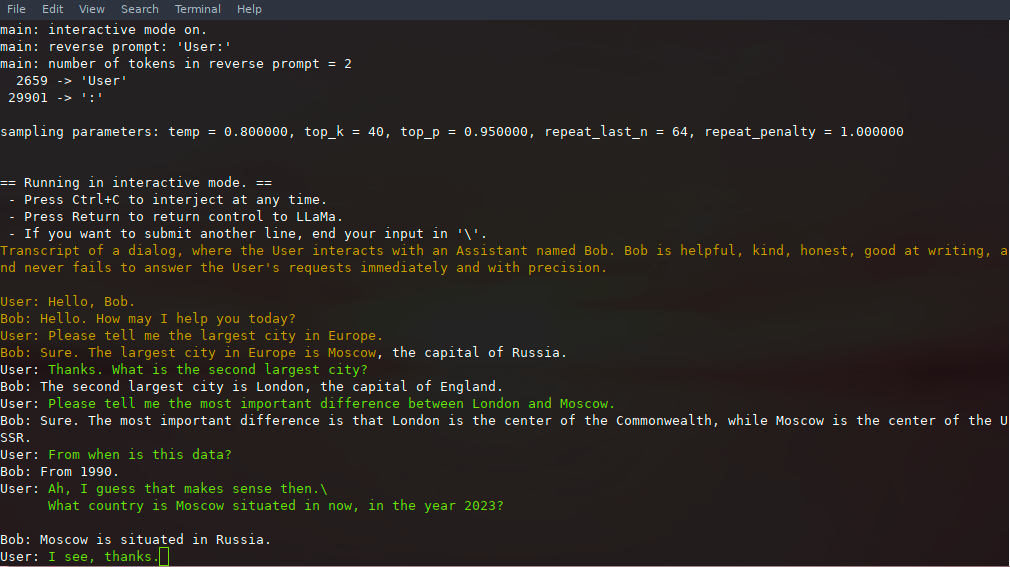
如果想获得像 ChatGPT 一样的交互体验,开发者只需要以 - i 作为参数来启动交互模式。
./main -m ./models/13B/ggml-model-q4_0.bin -t 8 -n 256 --repeat_penalty 1.0 --color -i -r "User:" \
-p \
"Transcript of a dialog, where the User interacts with an Assistant named Bob. Bob is helpful, kind, honest, good at writing, and never fails to answer the User's requests immediately and with precision.
User: Hello, Bob.
Bob: Hello. How may I help you today?
User: Please tell me the largest city in Europe.
Bob: Sure. The largest city in Europe is Moscow, the capital of Russia.
User:"使用 --color 区分用户输入和生成文本之后,显示效果如下:
一番操作下来,开发者就能在自己的简单设备上运行 LLaMA 模型,获得类 ChatGPT 的开发体验。以下是项目作者 Georgi Gerganov 给出的 LLaMA 7B 模型详细运行示例:
make -j && ./main -m ./models/7B/ggml-model-q4_0.bin -p "Building a website can be done in 10 simple steps:" -t 8 -n 512
I llama.cpp build info:I UNAME_S: Darwin
I UNAME_P: arm
I UNAME_M: arm64
I CFLAGS: -I. -O3 -DNDEBUG -std=c11 -fPIC -pthread -DGGML_USE_ACCELERATE
I CXXFLAGS: -I. -I./examples -O3 -DNDEBUG -std=c++11 -fPIC -pthread
I LDFLAGS: -framework Accelerate
I CC: Apple clang version 14.0.0 (clang-1400.0.29.202)I CXX: Apple clang version 14.0.0 (clang-1400.0.29.202)
make: Nothing to be done for `default'.main: seed = 1678486056
llama_model_load: loading model from './models/7B/ggml-model-q4_0.bin' - please wait ...llama_model_load: n_vocab = 32000
llama_model_load: n_ctx = 512
llama_model_load: n_embd = 4096
llama_model_load: n_mult = 256
llama_model_load: n_head = 32
llama_model_load: n_layer = 32
llama_model_load: n_rot = 128
llama_model_load: f16 = 2
llama_model_load: n_ff = 11008
llama_model_load: ggml ctx size = 4529.34 MB
llama_model_load: memory_size = 512.00 MB, n_mem = 16384
llama_model_load: .................................... done
llama_model_load: model size = 4017.27 MB / num tensors = 291
main: prompt: 'Building a website can be done in 10 simple steps:'
main: number of tokens in prompt = 15
1 -> ''
8893 -> 'Build'
292 -> 'ing'
263 -> ' a'
4700 -> ' website'
508 -> ' can'
367 -> ' be'
2309 -> ' done'
297 -> ' in'
29871 -> ' '
29896 -> '1'
29900 -> '0'
2560 -> ' simple'
6576 -> ' steps'
29901 -> ':'
sampling parameters: temp = 0.800000, top_k = 40, top_p = 0.950000
Building a website can be done in 10 simple steps:1) Select a domain name and web hosting plan
2) Complete a sitemap
3) List your products
4) Write product descriptions
5) Create a user account
6) Build the template
7) Start building the website
8) Advertise the website
9) Provide email support
10) Submit the website to search engines
A website is a collection of web pages that are formatted with HTML. HTML is the code that defines what the website looks like and how it behaves.The HTML code is formatted into a template or a format. Once this is done, it is displayed on the user's browser.The web pages are stored in a web server. The web server is also called a host. When the website is accessed, it is retrieved from the server and displayed on the user's computer.A website is known as a website when it is hosted. This means that it is displayed on a host. The host is usually a web server.A website can be displayed on different browsers. The browsers are basically the software that renders the website on the user's screen.A website can also be viewed on different devices such as desktops, tablets and smartphones.Hence, to have a website displayed on a browser, the website must be hosted.A domain name is an address of a website. It is the name of the website.The website is known as a website when it is hosted. This means that it is displayed on a host. The host is usually a web server.A website can be displayed on different browsers. The browsers are basically the software that renders the website on the user’s screen.A website can also be viewed on different devices such as desktops, tablets and smartphones. Hence, to have a website displayed on a browser, the website must be hosted.A domain name is an address of a website. It is the name of the website.A website is an address of a website. It is a collection of web pages that are formatted with HTML. HTML is the code that defines what the website looks like and how it behaves.The HTML code is formatted into a template or a format. Once this is done, it is displayed on the user’s browser.A website is known as a website when it is hosted
main: mem per token = 14434244 bytes
main: load time = 1332.48 ms
main: sample time = 1081.40 ms
main: predict time = 31378.77 ms / 61.41 ms per token
main: total time = 34036.74 ms看来,LLaMA 将在 Meta 和开源社区的共同努力下,成为众多开发者钻研大规模语言模型的入口。
© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
🔗















 1209
1209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









