







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
密码学系列——NTHASH以及MD4算法
前言
主要是为了快速回忆之前工作的一些记录,不至于完全忘记。
Windows下NTLM-Hash生成原理
IBM设计的LM Hash算法存在几个弱点,微软在保持向后兼容性的同时提出了自己的挑战响应机制,NTLM Hash便应运而生。
这里同样以上节的明文密码“123994”作为研究对象。首先在UltraEdit中输入123994,然后点击>>编辑>>十六进制函数>>十六进制编辑,
再点击>>文件>>转换>>ASCII转Unicode,如下图所示获得Unicode字符串为310032003300390039003400,
对所获取的Unicode字符串进行标准MD4单向哈希加密,无论数据源有多少字节,MD4固定产生128-bit的哈希值,产生的哈希值就是最后的NTLM Hash。
从网上下载HashCalc工具,打开后将310032003300390039003400输入数值框中,选择左侧数据格式为十六进制串,去掉HMAC前的对号。选中MD4加密,再点击计算,如下图所示。
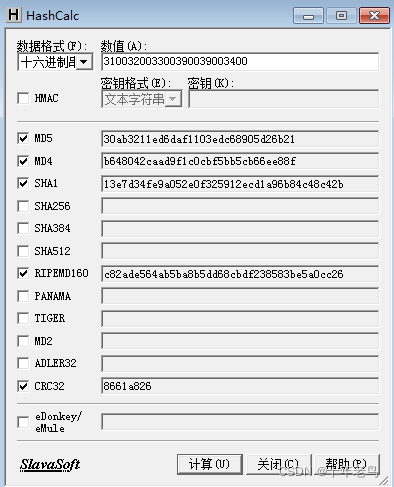
标准MD4 算法
MD4算法的一般步骤如下:
1、数据填充。将输入数据填充到数据长度是512位的倍数。具体的填充规则在下文进一步说明。
2、分组处理。将填充后的数据每512位(即64字节)划分为一组,再对每组数据进行处理。
3、处理完成后得到的128位结果即为MD4码。
MD4数据填充规则
在计算MD4码前,先要对数据进行填充。具体的填充规则如下:
1、补位:数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数。
2、附加信息长度:追加64位的整数,其内容是数据的比特数。
举个栗子。对于字符串“abc”而言,它的比特数为24,补上比特1后还需要再补上448-1-24=423个0比特,最后附加上信息长度24。
填充完成后的数据内容由四部分组成:
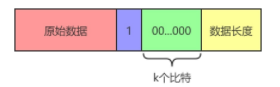
MD4变换函数
对每个数据分组进一步划分为16个子分块。每个子分块依次进入如下图所示的循环变换,总共三轮。
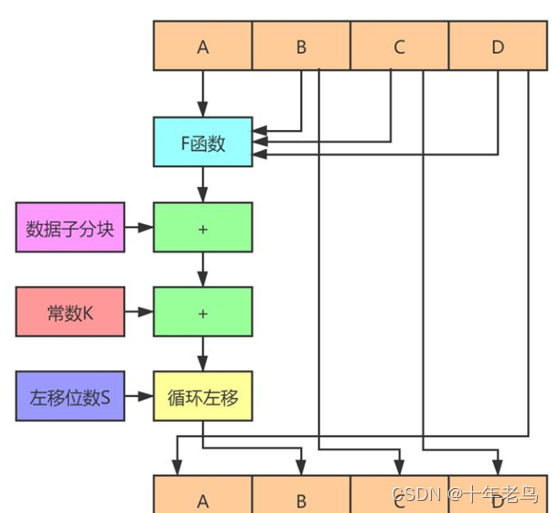
上图是一轮循环变换中对数据的一个子分块进行处理的过程。其中A的初值 = 0x67452301,B的初值 = 0xefcdab89,C的初值 = 0x98badcf,D的初值 = 0x10325476。每一轮变换的F函数、常数K都不同,每个子分块的左移位数S呈周期变化。
将经过三轮循环变换后得到的新的A、B、C、D和原来的A、B、C、D分别累加,即为MD4变换函数的输出。当处理完所有数据分组后,此时的变换函数输出即为MD4码。
代码片段
不多说了,直接给出代码关键部分解释
部分C模型代码,方便快速回忆
此处就是为了转换成unicode编码,并且得到unicode编码长度,然后送入MD4模块进行计算
int tmpPwdLen = 0;
for (int i = 0; pwd[i] != 0; ++i)
{
*tmpPwdPtr++ = pwd[i];
*tmpPwdPtr++ = 0;
tmpPwdLen += 2;
}
Md4Process(tmpPwd,tmpPwdLen,ntlmhash);
MD4算法依次经过了
由16次FF函数,16次GG函数,16次HH函数构成的三轮运算
FF函数、GG函数、HH函数定义如下:
#define F(x, y, z) ((z) ^ ((x) & ((y) ^ (z))))
#define G(x, y, z) (((x) & (y)) | ((x) & (z)) | ((y) & (z)))
#define H(x, y, z) ((x) ^ (y) ^ (z))
#define rol(value, bits) (((value) << (bits)) | ((value) >> (32 - (bits))))
#define FF(a,b,c,d,k,s) a=rol(a+F(b,c,d)+block[k],s)
#define GG(a,b,c,d,k,s) a=rol(a+G(b,c,d)+block[k]+0x5a827999,s)
#define HH(a,b,c,d,k,s) a=rol(a+H(b,c,d)+block[k]+0x6ed9eba1,s)
初值:
a = state[0];
b = state[1];
c = state[2];
d = state[3];
终值:
state[0] += a;
state[1] += b;
state[2] += c;
state[3] += d;
算法验证结果如下:

和最开始软件生成的结果完全一致
FPGA实现
同时为了方便FPGA实现,将C模型改造成:
FF(a,b,c,d, 0, 3);
FF(d,a,b,c, 1, 7);
FF(c,d,a,b, 2,11);
FF(b,c,d,a, 3,19);
如下形式,这样:
a = state[0];
b = state[1];
c = state[2];
d = state[3];
A_in = state[0];
B_in = state[1];
C_in = state[2];
D_in = state[3];
A_out = A_in;
B_out = B_in;
C_out = C_in;
D_out = D_in;
X_out = ( (B_in & (C_in ^ D_in)) ^ D_in);
Y_out = A_in + block[0];
//
X_in = X_out;
Y_in = Y_out;
A_in = A_out;
B_in = B_out;
C_in = C_out;
D_in = D_out;
A_out = D_in;
B_out = rol((X_in+Y_in),3);
D_out = C_in;
C_out = B_in;
X_out = ( (rol((X_in+Y_in),3) & (B_in ^ C_in)) ^ C_in);
Y_out = block[1] + D_in ;
//
A_in = A_out;
B_in = B_out;
C_in = C_out;
D_in = D_out;
X_in = X_out;
Y_in = Y_out;
A_out = D_in;
B_out = rol((X_in+Y_in),7);
D_out = C_in;
C_out = B_in;
X_out = ( (rol((X_in+Y_in),7) & (B_in ^ C_in)) ^ C_in);
Y_out = block[2] + D_in ;
//
A_in = A_out;
B_in = B_out;
C_in = C_out;
D_in = D_out;
X_in = X_out;
Y_in = Y_out;
A_out = D_in;
B_out = rol((X_in+Y_in),11);
D_out = C_in;
C_out = B_in;
X_out = ( (rol((X_in+Y_in),11) & (B_in ^ C_in)) ^ C_in);
Y_out = block[3] + D_in ;
//
A_in = A_out;
B_in = B_out;
C_in = C_out;
D_in = D_out;
X_in = X_out;
Y_in = Y_out;
A_out = D_in;
B_out = rol((X_in+Y_in),19);
D_out = C_in;
C_out = B_in;
X_out = ( (rol((X_in+Y_in),19) & (B_in ^ C_in)) ^ C_in);
Y_out = block[4] + D_in ;
a = A_out;
b = B_out;
c = C_out;
d = D_out;
注意几点,
1、 因为FF和GG和HH是比较大的组合逻辑,因此将这三个函数均拆成X_in+Y_in
2、 该算法并行化耗费大量的触发器资源,打拍要省着点;但不打拍组合逻辑又比较大可能会影响系统频率,因此需要做权衡和试验,确定最优方法



















 1416
1416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











