







时间复杂度
介绍
时间复杂度由多项式T(n)中最高阶的项决定

常见类型
由低到高:

最差、最佳时间复杂度
在实际应用中很少使用“最佳时间复杂度”,因为往往只有很小高概率才能达到,会带来一定的误导性。反之,“最差时间复杂度”最为实用,因为它给出了一个“效率安全值”,让我们可以放心地使用算法。
空间复杂度
简介
内存空间:
- 输入空间:存储算法的输入数据。
- 暂存空间:存储算法运行中的变量、对象、函数上下文等数据。
- 暂存数据:保存算法运行中的各种常量、变量、对象等。
- 栈帧空间:保存调用函数的上下文数据;系统每次调用函数都会在栈的顶部创建一个栈帧,函数返回时,栈帧空间会被释放。
- 指令空间:保存编译后的程序指令,实际统计中一般忽略不计。
- 输出空间:存储算法的输出数据。
通常,空间复杂度统计范围是 暂存空间 + 输出空间
常见类型

甜点1
尾递归
介绍
函数在尾位置调用自身,或一个尾调用本身的其他函数等,称为尾递归。
特征
- 在尾部调用的是函数自身;
- 可通过优化,使得计算仅占用常量栈空间。
数据结构
介绍
- 计算机中组织与存储数据的方式。
- 基本数据结构提供了数据的==“内容类型”,数据结构提供数据的“组织方式”==。
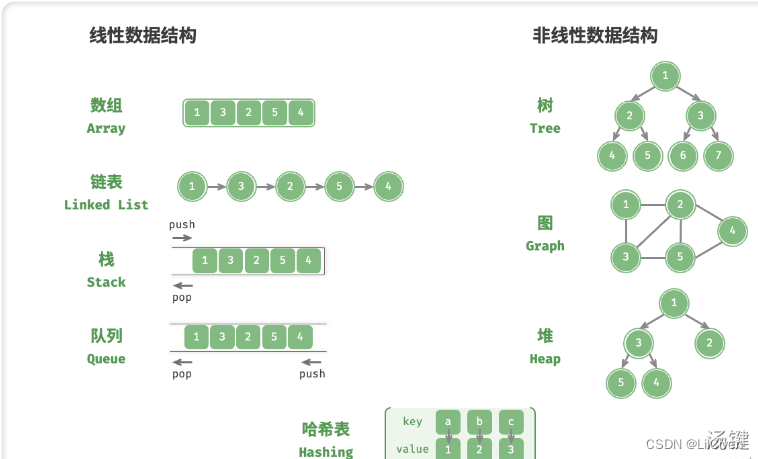
分类
-
逻辑结构
-
线性:数组、链表、栈、队列、哈希表等。
-
非线性:树、图、堆、哈希表。
-
-
物理结构
反应了数据在计算机内存中的存储方式。
拓展
- 所有数据结构都是基于数组、或链表、或两者组合实现的。
- 基于数组(静态数据结构):栈、队列、哈希表、树、堆、矩阵、张量等
- 基于链表(动态数据结构):栈、队列、哈希表、树、堆、图等
数组
介绍
- 将相同类型元素存储在连续内存空间的数据结构。
- 将元素在数组中的位置称为元素的索引 Index
特点
优点
-
访问高效。

-
为什么索引从0开始?
- 根据地址计算公式,索引本质上表示的是内存地址偏移量,首个元素的地址偏移量是0,所以索引是0很自然。
缺点
长度不可变。
操作
扩展数组
int[] extend(int[] nums, int enlarge) (
// 初始化一个扩展长度后的数组
int[] res = new int[nums.length + enlarge];
// 将原数组中的所有元素复制到新数组
for (int i = @; i < nums.length; i++){
res[i] = nums[i];
}
// 返回扩展后的新数组
return res;
}
插入元素
void insert(int[] nums, int num, int index) (
// 把索引 index 以及之后的所有元向后移动一位
for (int i = nums.length - 1; i > index; i--) {
nums[i] = nums[i - 1];
}
// 将 num 赋给 index 处元素
nums[index] = num;
}
删除元素
void remove(int[] nums, int index) {
// 把索引 index 之后的所有元素向前移动一位
for (int i = index; i < nums.length - 1; i++){
nums[i] = nums[i + 1];
}
}
遍历
void traverse(int[] nums) {
int count = 0;
// 通过索引遍历数组
for (int i = 0; i < nums.length; i++) {
count++;
}
//直接遍历数组
for (int num : nums) {
count++;
}
}
查找元素
int find(int[] nums, int target) {
for (int i = 0; i < nums.length; i++) {
if (nums[i] == target)
return i;
}
return -1;
}
甜点2
-
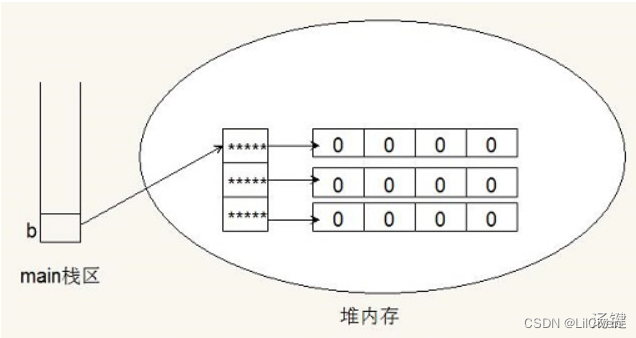
栈内存分配由编译器自动完成,堆内存由程序员在代码中分配。
- 栈不灵活,分配的内存大小不可更改;堆相对灵活,可以动态分配内存。
- 栈是一块比较小的内存,易出现内存不足;堆内存很大,但是由于是动态分配,易碎片化,故管理堆内存的难度更大、成本更高。
- 访问栈比访问堆更快,因为栈内存较小、对缓存友好,堆帧分散在很大的空间内,会出现更多的缓存未命中。
-
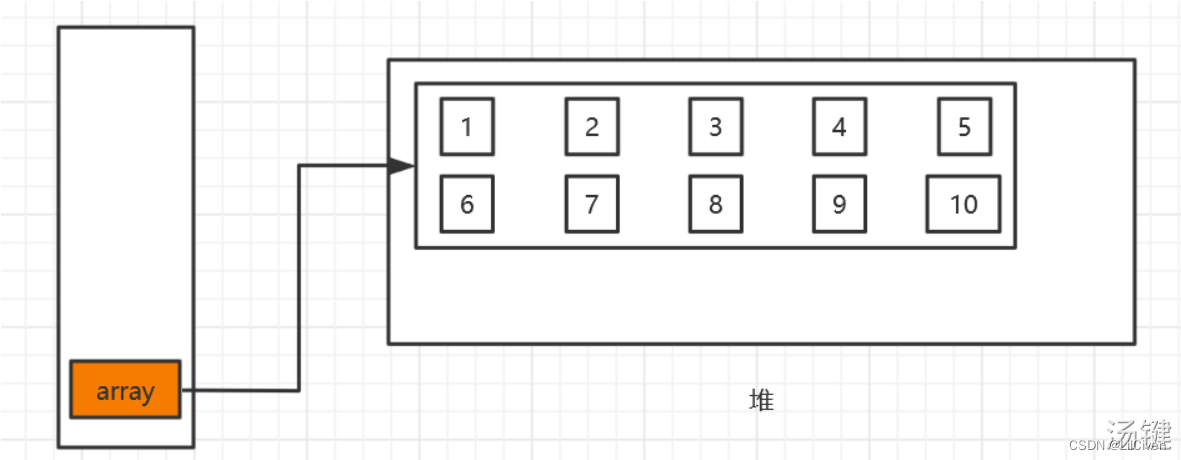
Java数组内存图
-
引用
-
什么是引用?
- 引用 = 起个别名;
- 并不另外开辟内存单元;
- 占用内存的同一位置。
-
什么是引用类型?
- 值类型直接存储其值,而引用类型存储对其值的引用;
- 这个引用指向真事的数组内存,如果数组元素也是引用类型,也就是多维数组。
-
链表
介绍
- 【链表Linked List】是一种线性数据结构,其中每个元素都是单独的对象,各个元素之间通过指针连接。
- 链表的【结点 Node】包含两项数据:
- 结点【值 Value】
- 指向下一节点的 【指针 Pointer】,为节点指向【空 null】
特点
优点
插入与删除结点的操作更高效。
缺点
链表访问结点效率低。
操作
初始化
-
初始化各个节点对象
-
构建引用指向关系
// 初始化各个节点 ListNode ne = new ListNode(1); ListNode n1 = new ListNode(3); ListNode n2 = new ListNode(2); ListNode n3 = new ListNode(5); ListNode n4 = new ListNode(4); // 构建引用指向 ne.next = n1; n1.next = n2; n2.next = n3; n3 .next = n4;
遍历链表查找
int find(ListNode head, int target) {
int index = 0;
while (head != null) {
if (head.val == target)
return index;
head = head.next;
index++;
}
return -1;
}
常见链表类型
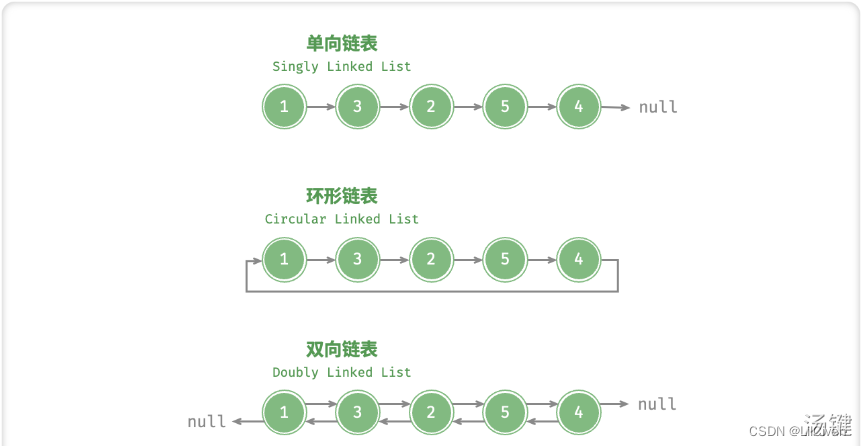
- 单向链表:即上述介绍的普通链表。
- 环形链表:
- 令单向链表的尾结点指向头结点(即首尾相接),则得到一个环形链表。
- 可以将任意节点看作是头节点。
- 双向链表:同时有指向下一节点和上一结点的指针。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









