






前言
在复杂分布式系统和庞大数据量的场景下,一般需要对大量数据进行唯一标识。
比如:数据库分库分表后需要用一个唯一ID来标识一条数据。
比如:nosql中的数据,需要一个唯一ID与其他数据源的数据进行关联
本文对比和总结了常见的几种方式。在座同学可以进行参考。
我在实际项目中经常使用ksuid算法。它简单可靠,还可按时间排序。
唯一ID生成规则要求
-
全局唯一
-
趋势递增
在MySQL的InnoDB引擎中使用Btree的数据结构来存储索引,在主键上我们应该尽量使用有序的主键保证写入性能。
-
信息安全
如果ID是连续,恶意用户号可以根据id直接知道我们一天的数据量,并且爬虫可以按照id顺序轻易的爬走所有数据
-
最好含时间戳
能够从ID本身知道这个分布式ID是什么时候生成的
唯一ID生成系统的要求
-
高可用
服务器就要保证99.999%的情况下能正常创建唯一ID
-
低延迟
接受一个获取唯一ID的请求,服务器要非常快速的响应
-
高QPS
比如并发10万个创建唯一ID请求,服务器能在短时间内成功创建10万个唯一ID
五种获取唯一ID的解决方案
1.UUID
- V1 : 基于时间戳 + mac地址
- V2 : 基于时间戳 + mac地址 + POSIX的UID或GID。
- V3 : 基于命名空间的MD5
- V4 : 基于随机数
- V5 : SHA1版本的V3
一般选用V4版本,V1有暴露mac地址的风险,V2特定场景才会用到,V3、V5相同的输入参数得到相同的UUID
优缺点
- 优点:简单可靠
- 缺点:不可排序,不利于检索
2.mysql自增id
适用mysql的自增id机制,满足 递增性、单调性、唯一性。
在单机情况下,如果并发量高,mysql的压力会很大。
分布式情况下,一般需要设定每台机器初始ID,来避免ID重复。这种方式有局限性,且水平扩展方案复杂,容易 出问题。
优缺点
- 优点:简单可靠,在单机、并发不高、数据量较小的情况下适用
- 缺点:在分库分表、高并发场景下不适用
3.redis
因为Redis是单线程,天生保证原子性,可以使用原子操作INCR和INCRBY来实现
单机和分布式的优缺点与mysql类似
4.snowflake
snowflake是由Twitter开源的一个分布式唯一ID的算法
算法结构
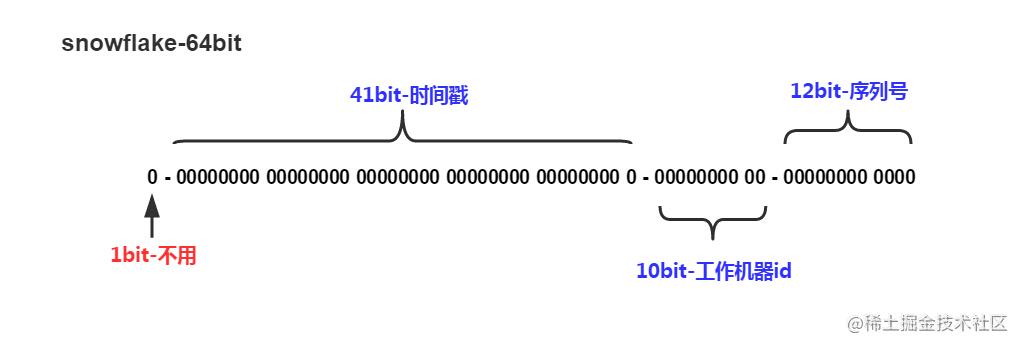
snowflake由4部分组成:
-
第一部分
二进制中最高位是符号位,1表示负数,0表示正数。生成的ID一般都是用整数,所以最高位固定为0。
-
第二部分:
41位时间戳位,毫秒级的时间戳 41位可以表示 2^41 - 1 毫秒 ≈ 69年,也就是说最多可用69年。
-
第三部分:
用10位来记录工作机器ID,最多可以部署在2^10 = 1024个节点,
-
第四部分:
用12位来记录序号,最多可以产生 2^12 = 4096个序号。
我对核心逻辑实现的demo
demo里只实现了最核心的算法内容,可以直观的通过代码了解算法的实现逻辑
const (
epoch = 1640966400000 // 起始时间 2022-01-01 00:00:00,可用69年
timeBits = uint8(41) // 时间位数
workerBits = uint8(10) // 机器id位数
seqBits = uint8(12) // 序列位数
workerIdMax = -1 ^ (-1 << workerBits) //最大机器id
seqMax = -1 ^ (-1 << seqBits) //最大序列值
timeShift = workerBits + seqBits //时间偏移位数
workerShift = seqBits //机器偏移位数
)
type Snowflake struct {
sync.Mutex
epoch time.Time
timestamp int64
workerId int64
seq int64
}
func NewSnowflake(workId int64) (*Snowflake, error) {
if workId < 0 || workId > workerIdMax {
return nil, fmt.Errorf("workId 范围 0 - %d", workerIdMax)
}
s := &Snowflake{workerId: workId}
return s, nil
}
func (s *Snowflake) Generate() int64 {
s.Lock()
defer s.Unlock()
now := time.Now().UnixMilli()
if now == s.timestamp {
// 同一毫秒下,序列增长
s.seq = (s.seq + 1) & seqMax
if s.seq == 0 {
// & seqMax == 0 时,序列已用完,等待下一毫秒
for now <= s.timestamp {
now = time.Now().UnixMilli()
}
}
} else {
s.seq = 0
}
s.timestamp = now
t := s.timestamp - epoch
return t<<timeShift | s.workerId<<workerShift | s.seq
}
优势:
-
单机可在一毫秒内生成4096个唯一ID
-
因为最高位是时间戳,所以snowflake生成的ID都是按时间趋势递增
-
因为有 workerId来做区分,所以整个分布式系统内不会产生重复ID
最大的问题:时钟回拨
snowflake非常依赖系统时间的一致性,如果发生系统时间的回调,改变,就可能会发生id的重复
下面是我总结的几种解决方法:
-
简单粗暴,直接抛出错误,让业务层去解决
-
关闭服务器时间同步
-
保存过去一小时,每个毫秒的序号使用情况。如果时间回退到某一毫秒,可以使用这一毫秒的序号,继续生成ID
-
生成ID的时间,不实时跟随服务器时间,当1毫秒内的序号全部用完,才跳到下一毫秒。如果生成ID的并发量不大,就有很大的余量时间没有使用,就算时钟回退了,也是回退到没有被使用的时间。
优缺点
- 优点:生成的ID趋势递增,生成效率高,可保证不重复
- 缺点:时钟回拨问题处理起来复杂,容易出现问题
5.ksuid
算法结构

ksuid由两部分组成
-
第一部分
32位的秒级时间戳
-
第二部分
128 位随机生成载荷
优势:
-
因为最高位是时间戳,所以snowflake生成的ID都是按时间趋势递增
-
而128位的号码空间,在一秒内出现随机碰撞的概率非常之低,1/2^128 约等于明天陨石撞地球的概率
-
没有序号则可以避免snowflake的时钟回拨问题
优缺点
- 优点:生成的ID趋势递增,生成效率高,没有时钟回拨的问题
- 缺点:有随机部分,理论上存在随机碰撞的可能
结尾
对比了5种解决方案。在我的业务场景下,我选择简单可靠的ksuid算法来生成唯一ID。
因为我用的golang语言开发,所以用的github上的开源实现
https://github.com/segmentio/ksuid

















 4590
4590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









