







Brain tumor segmentation using deep learning
摘要
Brain tumor is one of the deadliest forms of cancer and as all cancer types, early detection is very important and can save lives. By the time symptoms appear cancer may have begun to spread and be harder to treat. The screening process (the process of performing MRI or CT scans to detect tumors) can be devided to two main tasks.The first task is the classification task, doctors need to identify the type of the brain tumor. There are three types of brain tumors menigioma, pituitray and glioma. the type of the tumor can be an indication of the tumor‘s aggressiveness, however to estimate the tumor’s stage (the size of the cancer and how far it’s spread) an expert needs to segment the tumor first in order to measure it in an accurate way.This lead to the second and more time consuming task of segment the brain tumors which doctors need to seprate the infected tissues from the healty ones by label each pixel in the scan. This paper will investigate how can we utilize deep learning to help doctors in the segmention process. The paper will be devided into four main sections. in the first section we will explore the problem domain and the existing approachs of solving it. the second section will dicuss about the UNet architecture and it‘s variations as this model gives state of the art result on various medical image(MRI/CT) datasets for the semantic segmentation task. In the third section we will describe how we chose to adapt the Deep ResUnet architecture [7] and the experiments setup that we did to evaluate our model. In addition we will introduce the ONet architecture and show how we can boost the model performance by using bounding box labels.
脑瘤是最致命的癌症之一,作为所有癌症类型,早期发现可以挽救生命。当症状出现时,癌症可能已经开始扩散,并且更难治疗。筛查过程(进行MRI或CT扫描以检测肿瘤的过程)可分为两个主要任务。第一个任务是分类任务,医生需要确定脑瘤的类型。脑肿瘤有脑膜瘤、垂体瘤和胶质瘤三种类型。肿瘤的类型可以作为肿瘤侵袭性的一个指标,但是要估计肿瘤的规模(肿瘤的大小和扩散的程度),专家需要首先对肿瘤进行分割,以便以准确的方式进行测量。这导致了第二个也是更耗时的任务,即分割脑肿瘤,医生需要通过在扫描中标记每个像素,将感染组织从健康组织中剥离出来。本文将探讨如何利用深度学习来帮助医生进行细分。本文将分为四个主要部分。在第一节中,我们将探讨问题域和现有的解决方法。第二部分将讨论UNet体系结构及其变化,因为该模型给出了用于语义分割任务的各种医学图像(MRI/CT)数据集的最新结果。在第三部分中,我们将描述我们如何选择适应深层ResUnet体系结构[7]以及我们为评估我们的模型所做的实验设置。此外,我们将介绍ONet架构,并展示如何使用边界框标签来提高模型性能。
1、介绍
Cancer is one of the leading causes of death globally and it is responsible for 9.6 million deaths a year. One of the most deadliest type of cancer is brain cancer, the 5-years survival rate is 34% for men and 36% for women. An prevalent treatment for brain tumors is radiation threapy where high-energy radiation source like gamma rays or x-rays shoots in a very precise way at the tumor and therefore kill the tumor‘s cells while sparing surrounding tissues. However in order to perfom the radiation treatment doctors need to segment the infected tissues by separate the infected cells from the healthy ones. Creating this segmentation map in an accurate way is very tedious, expensive, time-consuming and error-prone task therefore we can gain a lot from automate this process.
癌症是全球主要的死亡原因之一,每年造成960万人死亡。最致命的癌症之一是脑癌,男性5年生存率为34%,女性为36%。脑肿瘤的一种普遍治疗方法是放射疗法,即伽玛射线或x射线等高能放射源以非常精确的方式射向肿瘤,从而杀死肿瘤细胞,同时保留周围组织。然而,为了实施放射治疗,医生需要通过分离受感染细胞和健康细胞来分割受感染的组织。以一种精确的方式创建这个分割图是非常繁琐、昂贵、耗时且容易出错的任务,因此我们可以从自动化这个过程中获得很多好处。
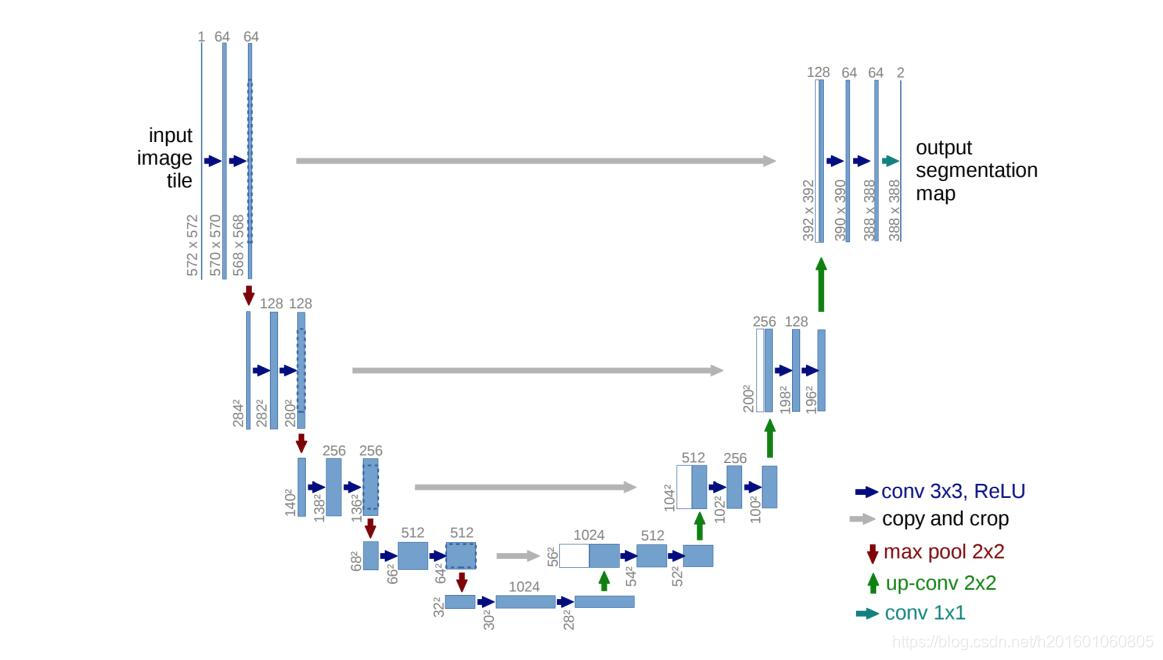
Semantic segmentation is an active research area in the deep learning space. One of the most dominent proposed model for medical images segmention is the UNet [5] model that uses encoder decoder structure combined with skip connections between the encoder’s layers the decoder‘s layers. the UNet architecture is composed of two main paths, the down path e.g the encoder and the up path
e.g the decoder. each encoder layer is composed of two convolution layers with relu activation functions followed by maxpooling operation. the output of the two convolution layers goes directly to the decoder layer in the corresponding level. each decoder layer is composed of two convolution layers with relu activation followed by upsampling layer. the decoder layer takes as an input the output from the corresponding layer of the encoder and concatenate it with the upsample output of the previous decoder layer. the output of the network has the same width and height as the original image with a deapth that indicate the activation for each label.
语义分割是深度学习领域中一个活跃的研究领域。提出的医学图像分割的一个最主要的模型是UNet[5]模型,该模型使用编码器-解码器结构,结合编码器层与解码器层之间的跳跃连接。UNet架构由两条主要路径组成,下行路径(如编码器)和上行路径(如解码器)。每个编码器层由两个具有relu激活函数的卷积层和maxpooling操作组成。两个卷积层的输出直接进入对应层的解码器层。每个译码器层由两个卷积层组成,两个卷积层分别激活relu和上采样层。解码器层将来自编码器的对应层的输出作为输入,并将其与前一解码器层的上采样输出连接起来。网络的输出与原始图像具有相同的宽度和高度,并带有一个deapth,指示每个标签的激活。
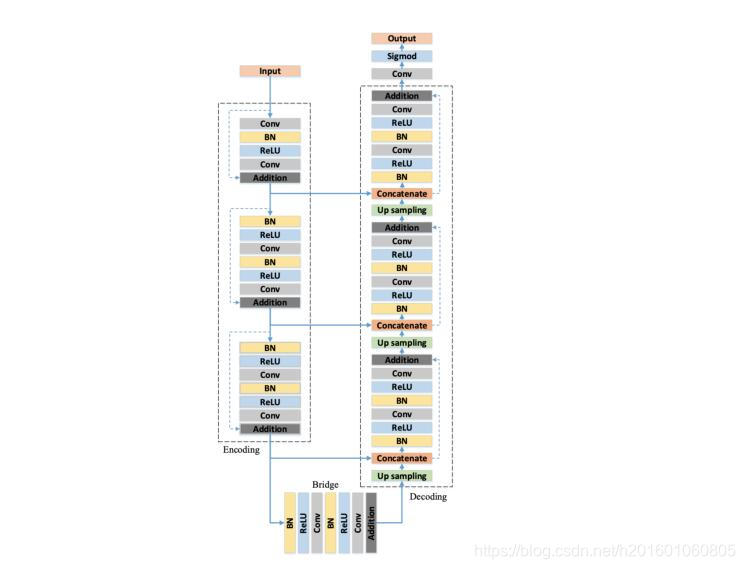
Other variations of UNet have been proposed like Deep ResUnet[7] that uses preactivation residual blocks instead of regular dobule conv blocks and element wise sumesion to restore the identity function. Deep ResUnet uses the improved version of ResNet blocks suggested in [3]. In this paper we want to revisit this idea to get better model for our dataset with different network that uses resnet blocks. Another variation of UNet that can deal with three dimension input is 3D-UNet [6] that uses Conv3D layers instead of the original Conv2D layers. Attention UNet[4] suggests an attention gate that can improve model sensitivity to foreground pixels without requiring complicated heuristics. Lastly an adaptation of UNet that use recurrent residual blocks has been proposed and used in [1].
Encoder-Decoder architects has been used to solve the semantic segmentation problem before UNet, however the depth of those model usually cause the ”vanish gradient” problem thus the main contribution of the UNet paper is the introduction of skip connection between the encoder outputs to
the decoder inputs. the Deep ResUNet model takes this idea a step further by changing the CNN layers to pre-activation Res Blocks and by doing this the network can restore the identity function more easily and in addition it increase the gradient flow by connecting the input more closely to the output.
UNet的其他变体也被提出,如Deep ResUnet[7],它使用预激活剩余块代替常规的dobule conv块和元素级sumesion来恢复身份函数。Deep ResUnet使用了[3]中建议的ResNet块的改进版本。在本文中,我们希望重新讨论这个想法,以便为使用resnet块的不同网络的数据集获得更好的模型。可以处理三维输入的UNet的另一个变体是3D UNet[6],它使用Conv3D层而不是原始的Conv2D层。Attention UNet[4]提出了一种注意门,它可以提高模型对前景像素的敏感度,而不需要复杂的启发式算法。最后提出了一种使用递归残差块的UNet自适应方法并且在[1]中被使用。
在UNet之前,编码器-解码器架构师已经被用来解决语义分割问题,但是这些模型的深度通常会导致“消失梯度”问题,因此UNet论文的主要贡献是在编码器输出和解码器输入之间引入跳跃连接。Deep ResUNet模型进一步将CNN层转换为预激活Res块,这样网络可以更容易地恢复身份函数,并且通过将输入与输出更紧密地连接来增加梯度流。
2、方法
The ResNet blocks help improve the performance of the network comparing to the UNet model, but in our expirements we found that switching all the double convolution blocks to resnet blocks makes the network too complicated and tend to overfit the training data. Our suggestion is to use the ResBlocks in the dowpath but keep the double CNN layers in the up path that way we still increase the gradient flow for the down path that are far from the output of the network while keeping the model relatively simple. Thus our suggestion for an architecture is to use the resnet blocks to the down path and normal double convolution block to the up path we will call this model the hybrid ResUnet. we will show that this model generalize better and get higher performance on the dice matric for our dataset. we use the ”brain tumor dataset” [2], this dataset consist of 3064 MRI scans represented as 512 x 512 matrics, and 512 x 512 boolean masks that indicate the pixels of the infected tissues in the image. Our performace metric will be the dice coefficient as this is a common metric for the segmentation problem, when there is imbalance between the true labels(the tumor‘s pixels) and the false labels(the non tumor‘s pixels). the dice formula for the binary case can be stated as follows:
与UNet模型相比,ResNet块有助于提高网络的性能,但是在我们的实验中,我们发现将所有的双卷积块切换到ResNet块会使网络变得过于复杂,并且容易过度拟合训练数据。我们的建议是在dowpath中使用ResBlocks,但将双CNN层保持在向上路径,这样我们仍然会增加远离网络输出的向下路径的梯度流,同时保持模型相对简单。因此,我们对于架构的建议是使用resnet块到下行路径,使用普通的双卷积块到上行路径,我们将此模型称为混合resnet。我们将证明该模型对我们的数据集有更好的泛化和更高的dice矩阵性能。我们使用“脑肿瘤数据集”[2],该数据集由3064个表示为512 x 512矩阵的MRI扫描和512 x 512布尔掩模组成,它们指示图像中受感染组织的像素。当真标记(肿瘤像素)和假标记(非肿瘤像素)之间存在不平衡时,我们的性能指标将是dice系数,因为这是分割问题的常见指标。边界情况下的dice公式如下:
2 T P 2 T P + F P + F N \frac{{2TP}}{{2TP + FP + FN}} 2TP+FP+FN2TP
And more concrete in our case the network will output 512 x 512 score map then after softmax and thresholding we will convert it to 0-1 map. we will check the set similarity of this map with the corresponding labeled mask using the dice formula as such:
Let X := output map
Let Y := labeled mask
更具体地说,在我们的例子中,网络将输出512×512的分数图,然后在softmax和阈值化之后,我们将其转换为0-1图。我们将使用骰子公式检查此映射与相应的标记掩码的集合相似性,如下所示:
2 ∣ X ∩ Y ∣ ∣ X ∣ + ∣ Y ∣ \frac{{2|X \cap Y|}}{{|X| + |Y|}} ∣X∣+∣Y∣2∣X∩Y∣
For the loss function we will use the dice loss, the dice loss is a soft version of the dice formula and gives a value between 0 to 1, where 0 means perfect match between the sets.
对于损失函数,我们将使用dice损失,dice损失是dice公式的一个软版本,给出一个介于0到1之间的值,其中0表示集合之间的完美匹配。
We can think of a way to provide additional knowledge to perform the semantic task better by adding ”regions of interest (ROI)” to the network input and ”inject” it to the network in the right places. Classic computer vision algorithms can be use to estimate the ROI or we can ask experts to provide rough estimation of the tumor region by drawing a bounding box around it(or give us 4 dimensional vector [x_min, x_max, y_min, y_max]). The suggested network use skip connection with concatination that makes the UNet architecht looks like ONet so we will use this name as an alias to the proposed model.
我们可以考虑一种方法,通过在网络输入中添加“感兴趣区域(ROI)”,并在正确的位置将其“注入”到网络中,来提供额外的语义,从而更好地执行语义任务。经典的计算机视觉算法可以用来估计ROI,或者我们可以要求专家通过在肿瘤区域周围画一个边界框(或者给我们4维向量[x_min,x_max,y_min,y_max])来粗略估计肿瘤区域。建议的网络使用带有concation的skip连接,使UNet architect看起来像ONet,因此我们将使用此名称作为建议模型的别名。
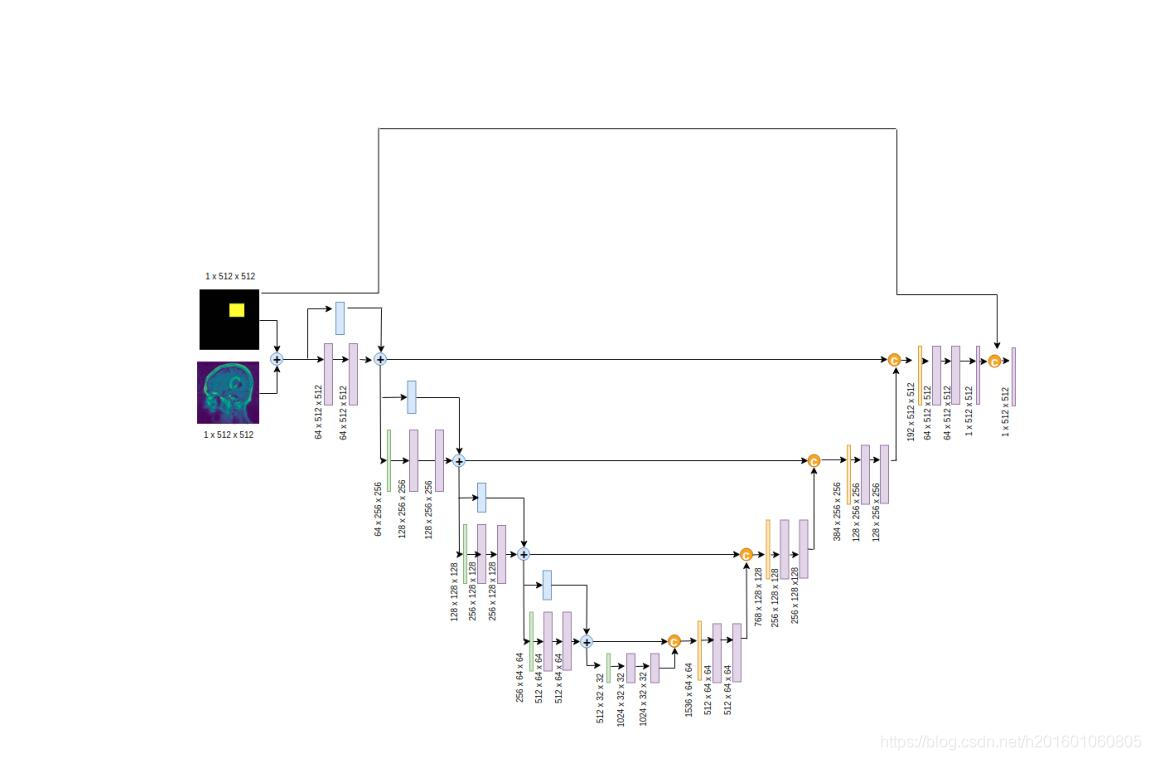
The ONet model sum the input and the activation map which contains the activated ROI pixels that makes the network focus on the region that contains the tumor. In addition we concatinate the ROI map to the output and add convolution layer with 1x1 kernel to learn the relationship between the ROI pixels to the output feature map pixels that would decrese the dice loss. We will add 2 hyperparameters to the network which indicate the activation coefficient of the ROI map before sum it to the original input. the activation coefficient of the ROI map that been concatinated with the network output.
ONet模型将输入和包含激活ROI像素的激活图相加,使网络聚焦于包含肿瘤的区域。此外,我们将ROI映射浓缩到输出,并使用1x1内核添加卷积层,以了解ROI像素与输出特征映射像素之间的关系,从而减少dice系数丢失。我们将在网络中添加2个超参数,在将其与原始输入相加之前指示ROI图的激活系数。与网络输出一致的ROI图的激活系数。
3、实验
We have implemented the UNet architect and the Deep ResUnet architect to benchmark their performance against our models, the Hybrid ResUnet and the ONet. To estimate our models we will use the same configutation for all the experiments and the only thing that will be change is the model choice. we will split our dataset into train and test datasets. Adam optimizer will be used with learning rate of 0.001 for all of the experiments and the loss function will be a soft version of the dice metric as known as dice loss. The input will be 512 x 512 grayscale images (one channel) and the batch size will be 2 images. we want to retain the high resolution of the images because this is essential for the segmentation task. we normalized the images by subtracting the mean of the images. The first experiment will compare the dice performance of the UNet, Deep ResUnet and the Hybrid solution where the down path contains Res blocks and the up path double conv blocks. The second experiment will compare the ONet to the other networks.
我们已经实现了UNet架构师和Deep ResUnet架构师,将他们的性能与我们的模型、混合ResUnet和ONet进行基准测试。为了估计我们的模型,我们将对所有的实验使用相同的配置,唯一会改变的是模型的选择。我们将把数据集分成训练和测试数据集。Adam优化器将使用5,所有实验的学习率为0.001,损失函数将是被称为dice损失的dice度量的软版本。输入为512 x 512灰度图像(一个通道),批量大小为2个图像。我们希望保持图像的高分辨率,因为这对于分割任务至关重要。我们通过减去图像的平均值使图像标准化。第一个实验将比较UNet、Deep ResUnet和混合解决方案的dice性能,其中下行路径包含Res块,上行路径包含双conv块。第二个实验将把ONet与其他网络进行比较。
4、结果
First we will analyze the Hybrid ResUnet model generalization capability by comparing it with the UNet architecture and the ResUnet architecture with the same experiment setup as described above.
首先,我们将通过与UNet体系结构和具有上述相同实验设置的resnet体系结构的比较来分析混合resnet模型的泛化能力。
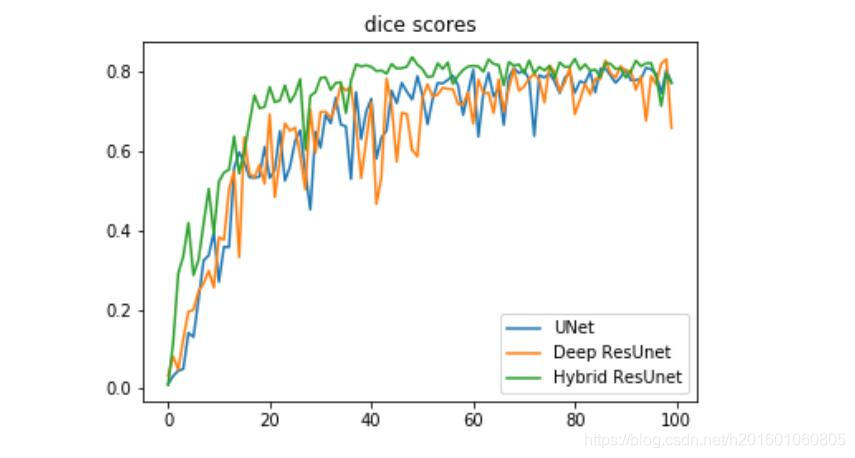
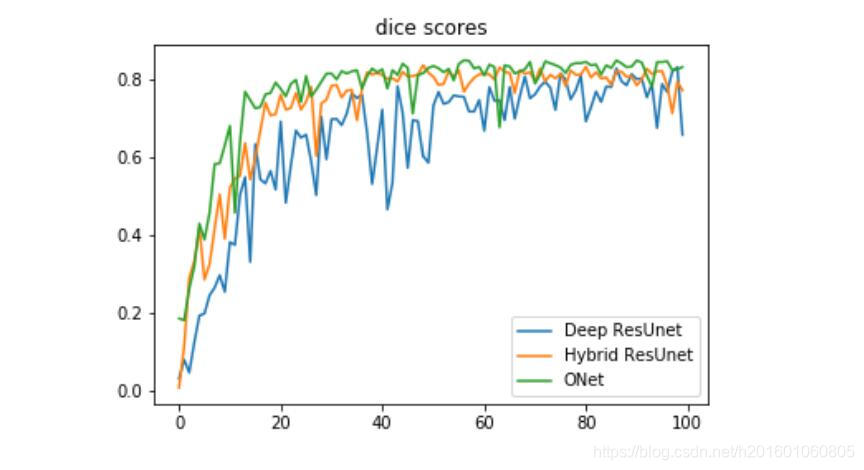
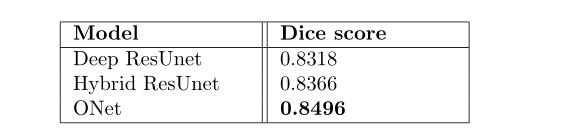
we can notice that the hybrid solution between resnet blocks and double conv blocks genralization better than the basic Unet and the Deep ResUnet for our dataset and in addition it convert faster and has less noisy curve. In our second experiment we compare the Deep ResUnet, Hybrid ResUnet and the proposed network the ONet on the dice metric for the test dataset.
我们可以注意到,对于我们的数据集,resnet块和double conv块之间的混合解决方案比基本的Unet和Deep ResUnet生成效果更好,而且转换速度更快,噪声曲线更少。在我们的第二个实验中,我们比较了深度恢复网、混合恢复网和提出的网络测试数据集的一对一度量。
5、结论
The ONet architecture gets very good performance on the brain tumor dataset, however it depences on a good estimation of the tumor region. fortunately ROI estimation is a much esaier task and can be done pretty accurately by another model or by human. we also noticed from our experiment that get the more complex model does not always imrpove the performance of the network and sometimes even makes it worse as we observed from the Deep ResUnet and the Hybrid ResUnet compression.
ONet结构在脑肿瘤数据集上有很好的性能,但它依赖于对肿瘤区域的良好估计。幸运的是,ROI估计是一个更容易完成的任务,并且可以通过另一个模型或由人来非常精确地完成。从我们的实验中我们还注意到,得到更复杂的模型并不总是会影响网络的性能,有时甚至会使网络性能变得更差,正如我们从深度恢复网和混合恢复网压缩中观察到的那样。
参考文献 用谷歌浏览器打开
[2] brain tumor dataset. [Online; accessed 27. Sep. 2019]. Apr. 2017.
[3] Kaiming He et al. “Identity Mappings in Deep Residual Networks”. In: arXiv (Mar. 2016). eprint: 1603.05027.
[4] Ozan Oktay et al. “Attention U-Net: Learning Where to Look for the Pancreas”. In: arXiv (Apr. 2018). eprint: 1804 . 03999.















 1329
1329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









