







介绍
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene™ 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
基本概念
先说Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{
"name" : "Monkey",
"sex" : "Male",
"age" : 25,
"birthDate": "1990/01/01",
"about" : "about",
"interests": [ "football", "music" ]
}
用Mysql这样的数据库存储就会容易想到建立一张User表,有’name、sex…'等字段,在Elasticsearch里这就是一个文档,当然这个文档会属于一个User的类型,各种各样的类型存在于一个索引当中。这里有一份简易的将Elasticsearch和关系型数据术语对照表:
-
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
-
Elasticsearch ⇒ 索引(Index) ⇒ 类型(type) ⇒ 文档(Docments) ⇒ 字段(Fields)
集群结构
- 代表一个集群,集群中有多个节点(node),其中有一个为主节点,这个主节点是可以通过选举产生的, 主从节点是对于集群内部来说的。
- ES的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看ES 集群,在逻辑上是个整体,你与任何一个节点的通信和与整个ES集群通信是等价的。
- ES集群是一个或多个节点的集合,它们共同存储了整个数据集,并提供了联合索引以及可跨所有节点的搜 索能力。多节点组成的集群拥有冗余能力,它可以在一个或几个节点出现故障时保证服务的整体可用性。
- 集群靠其独有的名称进行标识,默认名称为“elasticsearch”。节点靠其集群名称来决定加入哪个ES集 群,一个节点只能属一个集群。
ES存储
-
创建索引库默认创建:
5个主分片(primary shard)
5个副本分片(replica shard) -
可指定节点数量
PUT /索引名
{
//主分片数量
"number_of_shards": 3,
//副本分片数量
"number_of_replicas": 1
}
ps:单机启动,副本分片没有节点存储,所以显示unassigned

- 查看索引结构:
GET /索引名/_mapping

IK分词器底层数据结构及原理
原理:数据结构 - 把词语进行树化(二叉树)
0:代表开始 1:代表结束

并在内部集成27w个词语,目录:org/wltea/analyzer/dic/main2012.dic
结果:中文、分词、中文好
ES故障转移
集群状态:

场景:NodeB宕机,会发送故障转移
- 1、把P2、R1还有其它的分片进行重新负载均衡分配(P:分片。R:P的副本)
- 2、当NodeB节点恢复后,又会对分片进行重新分配
特点:为了分担服务器压力,ES采用非常巧妙的设计原理,采用分片方式存储数据,然后把分片均衡存储在每一个物理机中,实际相当于负载均衡(请求最终发送给分片,因此请求均衡分布在一个节点中)
- 1、ES集群主分片数量一旦确定就无法更改。如有更改重新创建索引库。
- 2、副本分片理论可以无限扩容,所有分片都由Master维护,导致性能下降,内存、CPU、IO资源限制分片数据。
- 3、一个文档(document)只能存储在一个分片。
- 4、主分片数量确定存储容量,副本分片数据只是主分片数据烤贝。
- 5、主分片理论可以存储无限制大小的数据,如果一个分片太大则读取数据和故障转移性能下降(50G)
极限分片:一台机器一个分片。
总结:
-
副本分片作用:
- 数据备份,防止数据丢失
- 可以提供读的能力,分担服务器压力 分片是否具有独立索引能力:
- 一个分片就是一个完整的索引库,相当于数据进行分块存储,每一个块都是一个完整的数据库,提供数据的读写能力。 主分片挂掉?:
- 副本分片变成主分片
ES分片横向扩容
- 构建ES集群后,并发访问压力越来越大,数据量越来越大,怎么办?
案例:2个节点(2个primary shard,2个replica shard )如图:
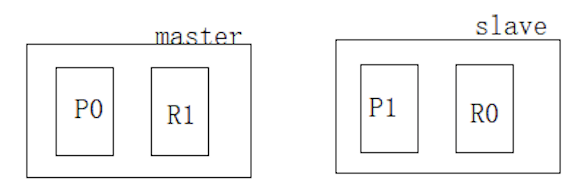
扩容一:权限分片方法,一个分片一台服务器

每一个分片独占CPU、IO资源,性能会有一定提升。
- 并发访问量进一步扩大,如何对上面服务进一步扩容?
解决方案:对副本分片进行扩容,采用极限分片方法(主分片数量一旦确定就无法更改)。

所有业务永远是读多写少!
索引存储结构
分片存储结构(shard -> segment -> 索引)

-
索引一旦写入磁盘(内存)就不可更改。因素:
- 数据无需更改,防止并发修改,不需要加锁,保护索引库数据安全性。
- 防止索引被频繁的修改,写入、浪费性能,占用IO。
- 索引在内存中搜索只需要命中即可,提升搜索效率。
存储流程
当一个写请求发送到 es 后,es 将数据写入memory buffer中,并添加事务日志(translog)。如 果每次一条数据写入内存后立即写到硬盘文件上,由于写入的数据肯定是离散的,因此写入硬盘的操作 也就是随机写入了。硬盘随机写入的效率相当低,会严重降低es的性能。
因此 es 在设计时在memory buffer和硬盘间加入了 Linux 的页面高速缓存(File system cache) 来提高 es 的写效率。
当写请求发送到 es 后,es 将数据暂时写入memory buffer中,此时写入的数据还不能被查询到。默认设置下,es 每1秒钟将memory buffer中的数据refresh到 Linux 的File system cache,并清空memory buffer,此时写入的数据就可以被查询到了。

但File system cache依然是内存数据,一旦断电,则File system cache中的数据全部丢失。默认设置下,es 每30分钟调用fsync将File system cache中的数据flush到硬盘。因此需要通过translog来保证即使因为断电File system cache数据丢失,es 重启后也能通过日志回放找回丢失 的数据。
translog默认设置下,每一个index、delete、update或bulk请求都会直接fsync写入硬盘。 为了保证translog不丢失数据,在每一次请求之后执行fsync确实会带来一些性能问题。对于一些 允许丢失几秒钟数据的场景下,可以通过设置index.translog.durability和index.translog.sync_interval参数让translog每隔一段时间才调用fsync将事务日志数据写入硬盘。
集群选举
配置文件:
//是否有资格成为master节点
node.master = true
//默认3s,最好增加这个参数值,避免网络慢或者拥塞,确保集群稳定性
discovery.zen.ping_timeout: 3s
//控制选举行为发生的集群最小master节点数量,防止脑裂
discovery.zen.minimum_master_nodes: 2
//新节点加入集群等待时间
discovery.zen.joint_timeout: 10s
新节点加入默认重试20次
脑裂现象:

左边:master无法发现其它节点
右边:node节点也无法发现master节点
此时发生重新选举现象,右边会发生重新选举现象,选出一个新master那么此时会发生脑裂。
解决方案:当前集群网络中节点数量是否大于等于集群候选master数量/2+1,满足条件可以选举,否则无法选举且取消master身份。(图左边取消master身份,图右边选举新master提供服务)
3/2+1=2(防止脑裂数字)
文档路由原理
计算公式:
shard = hash(routing) % number_of_primary_shards
routing:默认文档id。自定义:/usr/doc/11?routing = 21
number_of_primary_shards:主分片数量
例:
用户随机向某个节点发起请求,此节点身份将会立马切换为协调节点,协调节点将会进行计算,计算出应该操作的那个节点。设hash(1)=21,主分片数量为:3,21%3=0,那么访问p0分片。
//倒排索引
索引
张三 id:1->id:2->id:5
李四 id:3->id:4->id:4
王五 id:2->id:7
基本操作
// 测试分词器效果
POST _analyze
{
"analyzer": "ik_smart", //分词器名称
"text":"我爱中国" //内容
}
GET _analyze
{
"analyzer": "ik_max_word",
"text":"我爱中国"
}
//=================== 添加 ===================
//添加es,没有定id,自动生成
POST /database/user
{
"id":10011,
"name":"张三",
"age":22,
"sex":"女",
"tag":[1,2,4,5]
}
//添加es,指定id
POST /database/user/123
{
"id":10011,
"name":"张三",
"age":22,
"sex":"女",
"tag":[1,2,4,5]
}
//=================== 删除 ===================
//删除需要指定_id的值
DELETE /database/user/_id
//=================== 修改 ===================
//修改部分字段
POST /database/user/123/_update
{
"doc": {
"id":"10012"
}
}
//全部修改同:添加es,指定id
//=================== 查询 ===================
// 7.*是过渡版本,允许一个索引有多个类型,8.*以后一个索引只能有一个类型
// 查询指定索引下所有文档
GET /database/_search
// 查询指定索引下类型所有文档
GET /database/user/_search
GET /database/user/_search
{
"query":{
"match_all": {}
}
}
// term查询不分词
GET /database/user/_search
{
"query":{
"term": {
"title": "java"
}
}
}
// query_string、match查询分词
GET /database/user/_search
{
"query":{
"query_string": {
"default_field": "title",
"query": "我学习java"
}
}
}
GET /database/user/_search
{
"query":{
"match":{
"title":"我学习java"
}
}
}
// 多字段查询
GET /database/user/_search
{
"query": {
"multi_match": {
"query": "张三",
"fields": ["name","address"]
}
}
}
// 多条件查询
// sex = 女 and age = 2
GET /database/user/_search
{
"query": {
"bool": {
"filter": [
{"term": {
"sex": "女"
}},
{"term": {
"age": 2
}}
]
}
}
}
//sex = 女 or name = 张
GET /database/user/_search
{
"query": {
"bool": {
"filter": [
{"term": {
"sex": "女"
}}
],
"should": [
{"match": {
"name": "张"
}}
]
}
}
}
// ———————复杂查询———————
//term结合bool使用时:should是或,must是与,must_not是非(还有一种filter,不说了这个)
// where sex = 女 or sex = 男 and age != 22 and tag in [2,5] and id <= 2000 and id >= 1000
GET /database/user/_search
{
"query": {
"bool": {
"should": [
{"term":{"sex":"女"}},{"term":{"sex":"男"}}
],
"must_not": [
{"term":{"age":22}}
],
"must": [
{"terms": {
"tag": [
2,
5
]
}}
],
"filter": [
{"range":{"id": {
"gte": 1000,
"lte": 2000
}}}
]
}
}
}
//查询再分组
GET /database/user/_search
{
"query": {
"bool": {
"filter": [
{"term": {
"sex": "女"
}}
]
}
}
,"aggs": {
"models": {
"terms": {
"field": "age",
"size": 1000
}
}
}
}















 7495
7495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









