







一、java多线程与并发
1、为什么需要多线程
程序: 是指令和数据的有序集合,其本身没有任何运行的含义,是一个静态概念。
进程: 是应用程序的一次执行实例,是一个动态概念。进程是系统资源分配的单位。
线程: 是进程内部的一个独立执行单元,一个进程中的所有线程都在该进程的虚拟地址空间中,使用该进程的全局变量和系统资源。线程是CPU执行和调度的单位。
多线程解决的问题:平衡CPU、内存、I/O设备之间速度差异。
相比于多进程,多线程有如下优点:
1.与多进程相比,多线程花销小,切换快。
2.线程之间通信机制更加方便。由于各线程共享数据空间,所以一个线程的数据可以直接被其他线程使用。
2、并发三要素
可见性(CPU缓存引起): 一个线程对共享变量的修改,另一个线程能够立刻看到。
原子性(分时复用引起):一个操作或者多个操作不可再分,其执行过程不会被打断,要么执行,要么不执行。
有序性(指令重排序引起):代码执行的顺序按照既定流程执行。
3、java创建线程
第一种方式:(不推荐)
1.创建一个Thread的子类,重写其中的run( )方法,设置线程的任务
2.创建Thread的子类对象,调用子类对象的.start( )方法来执行该线程的run方法
注意: 多次启动同一个线程是非法的,特别是线程执行结束后,不能再重新启动
//创建一个继承类,重写run方法
public class MythreadTest extends Thread{
@Override
public void run() {
for (int i = 0; i < 20; i++) {
System.out.println(Thread.currentThread().getName()+"——>"+i);
}
}
}
//创建一个继承类对象,start启用线程
public static void main(String[] args) throws InterruptedException {
Thread myThread = new MythreadTest();
myThread.start();
}
第二种方式:(推荐)
1.创建一个Runable接口的实现类,并实现run方法
2.创建实现类对象,调用实现类对象的.start( )方法来执行该线程的run方法
优点:
1、 避免了单继承的局限性
一个类只能继承一个父类,继承了Thread就不能继承其他类了。
实现Runnable接口,还可以继承其他类,实现其他接口
2、 降低了程序的耦合性
实现Runnable接口的方式,把设置线程任务和开启线程进行了分离。(静态代理)
//创建一个Runable接口的实现类,并实现run方法
public class MythreadImp implements Runnable{
@Override
public void run() {
for (int i = 0; i < 20; i++) {
System.out.println(Thread.currentThread().getName()+"->"+i);
}
}
}
//创建一个实现类对象,start启用线程
public static void main(String[] args) {
MythreadImp mythreadImp = new MythreadImp();
Thread myThread1 = new Thread(mythreadImp,"线程1");
myThread1.start();
}
第三种方式:(了解)
1.创建一个Callable接口的实现类,并实现call方法
2.将Callable实现类接口对象作为参数创建FutureTask对象
3.将FutureTask对象作为参数创建Tread类,启动线程
优点:
1、call方法有返回值
2、call方法声明抛出了异常
//1.创建一个Callable接口的实现类,并实现call方法
public class CallableImp implements Callable<Boolean>{
@Override
public Boolean call() throws Exception {
for (int i = 0; i < 20; i++) {
Thread.sleep(20);
System.out.println(Thread.currentThread().getName()+"->"+i);
}
return true;
}
}
//2.将Callable实现类接口对象作为参数创建FutureTask对象
//3.将FutureTask对象作为参数创建Tread类,启动线程
public static void main(String[] args) {
CallableImp callableImp = new CallableImp();
FutureTask<Boolean> futureTask = new FutureTask<Boolean>(callableImp);
Thread thread = new Thread(futureTask);
thread.start();
}
使用线程池对线程进行复用:
1.Executors.newFixedThreadPool(n)创建线程池
2.创建Callable或者Runable实现类
3.<T> Future<T> executorService.submit(callable/runable)将实现类传入,或者void executorService.excute(runable)传入
4.关闭线程池(可选)
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(2);
CallableImp callImp01 = new CallableImp();
CallableImp callImp02 = new CallableImp();
Future<Boolean> f1 = executorService.submit(callImp01);
Future<Boolean> f2 = executorService.submit(callImp02);
//获取call方法的返回值
Boolean re1 = f1.get();
Boolean re2 = f1.get();
System.out.println(re1);
System.out.println(re2);
//关闭线程池
executorService.shutdown();
}
一个龟兔赛跑的案例
//多线程:龟兔赛跑
public class MythreadTest03 implements Runnable{
private static String winner;
@Override
public void run() {
for (int i = 0; i <= 100; i++) {
if(Thread.currentThread().getName().equals("兔子")&&i%40==0){
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
boolean flag = gameOver(i);
if(flag) {
break;
}
System.out.println(Thread.currentThread().getName()+"跑了"+i);
}
}
private boolean gameOver(int step){
if(winner != null){
return true;
}else{
if(step >= 100){
winner = Thread.currentThread().getName();
System.out.println(winner+"是冠军!");
return true;
}
}
return false;
}
public static void main(String[] args) {
Thread thread1 = new Thread(new MythreadTest03(),"兔子");
Thread thread2 = new Thread(new MythreadTest03(),"乌龟");
thread1.start();
thread2.start();
}
}
4、线程状态
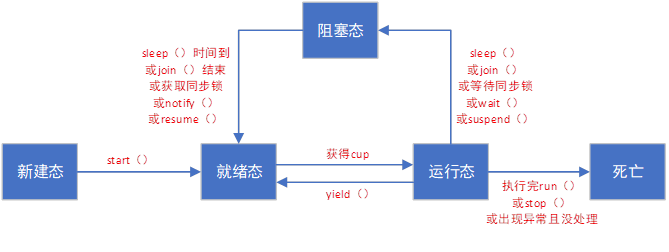
4.1 线程停止
官方一般不推荐使用stop()和destroy()方法使线程停止,一般是使用一个标志位,利用标志位的状态控制线程是否继续或者停止。
例如:
boolean flag = true; //一般通过设置标志位来让线程停止,尽量不使用stop或者destroy函数
@Override
public void run() {
while (flag) {
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
buy();
}
}
4.2 线程休眠:sleep()
Thread.sleep()函数用来指定当前线程阻塞的毫秒数- sleep存在InterruptedException异常
- sleep时间达到后进入就绪状态
- 每一个对象都有一个锁,sleep不会释放锁
4.3 线程礼让:yield()
- 让当前正在执行的线程停止(使其进入就绪态),但不阻塞
- 让CPU重新调度,礼让不一定成功!看CPU心情
4.4 线程强制执行:join()
- join合并线程,待此线程执行完成后再执行其他线程。
- 其他线程进入阻塞状态
- 插队!
4.5 观测线程状态
Thread.state存储当前线程状态,可以是以下状态之一:
NEW尚未启动的线程处于该状态RUNNABLE正在执行的线程处于该状态BLOCKED被阻塞的线程处于该状态WAITTING正在等待另一个线程执行特定动作的线程处于此状态TIMED_WAITTING正在等在另一个状态达到指定等待时间的线程处于此状态TERMINATED已退出的线程状态
4.6 线程优先级
- java提供一个线程调度器来监控程序中启动后进入就绪状态的所有线程,线程调度器按照优先级选择应该调度哪个线程。
- 优先级范围:1~10
getPriority()/setPriority()- 优先级的设定建议在
start()调度前 - 优先级低只是意味着获得调度的概率低,具体看CPU调度
4.7 守护(deamon)线程
- 线程分为用户线程和守护线程
- 虚拟机必须确保用户线程执行完毕
- 虚拟机不用等待守护线程执行完毕
- 如gc线程就是守护线程,它会随着最后一个用户线程终止而终止。
public class DeamonTest extends Thread{
@Override
public void run() {
while (true){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("上帝保佑你");
}
}
public static void main(String[] args) {
DeamonTest deamonTest = new DeamonTest();
deamonTest.setDaemon(true);
deamonTest.start();
for (int i = 0; i < 20; i++) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("如今:"+i+"岁");
}
}
}
5、java多线程不安全的实例
5.1 不安全购票实例
public class UnsafeBuyTicket {
public static void main(String[] args) {
BuyTicket station = new BuyTicket();
new Thread(station,"小明").start();
new Thread(station,"红").start();
new Thread(station,"黄牛党").start();
}
}
class BuyTicket implements Runnable {
private int ticket = 10;
boolean flag = true; //一般通过设置标志位来让线程停止,尽量不使用stop或者destroy函数
@Override
public void run() {
while (flag) {
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
buy();
}
}
private void buy() {
if (ticket > 0) {
System.out.println(Thread.currentThread().getName() + "拿到" + ticket--);
} else {
flag = false;
}
}
}
结果:
小明拿到10
红拿到9
黄牛党拿到8
黄牛党拿到7
小明拿到5
红拿到6
小明拿到3
黄牛党拿到4
红拿到3
黄牛党拿到2
红拿到1
结果分析: 由于并发,小明和红同时拿到了第3张票
5.2 不安全银行取钱实例
package day02;
public class UnsafeAccount{
public static void main(String[] args) {
Bank bank = new Bank("00010",80);
new Thread(bank,"小红").start();
new Thread(bank,"小明").start();
}
}
class Bank implements Runnable{
private Account account;
public Bank(String id,int money){
account = new Account(id,money);
}
public void takeMoney(String name,int takeMoney){
if(account.money < takeMoney){
System.out.println("余额不足,无法取钱!");
return;
}
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
account.money -= takeMoney;
System.out.println(name+"取了"+takeMoney+",剩余"+account.money);
}
@Override
public void run() {
takeMoney(Thread.currentThread().getName(),50);
}
}
class Account{
String id;
int money;
public Account(String id,int money){
this.id = id;
this.money = money;
}
}
结果:
小红取了50,剩余30
小明取了50,剩余-20
结果分析: 由于并发,小红和小明同时看到有80元,同时进行了取钱操作,于是银行余额产生了负值。
5.3 不安全的数组实例
import java.util.ArrayList;
public class UnsafeList {
public static void main(String[] args) {
ArrayList mylist = new ArrayList();
for (int i = 0; i < 10000; i++) {
new Thread(()->{
mylist.add(Thread.currentThread().getName());
}).start();
}
try {
Thread.sleep(2000); //延时,保证添加元素的线程都执行完了
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(mylist.size());
}
}
结果:
9997
结果分析: 由于arraylist线程不安全,在线程存取任务中可能存在多个数据存在了同一位置的情况,导致了最终的数组长度与预想不一致情况。
6、线程同步机制
由于多个线程共享同一块存储区,线程并发时会带来访问冲突的问题,为了保证数据访问的正确性,在访问时引入锁机制。当一个线程获得了对象的排它锁,独占资源,其他线程必须等待,该线程使用结束后再释放锁。存在以下问题:
- 一个线程持有锁会导致其他需要此锁的线程挂起;
- 多线程竞争下,加锁、释放锁会导致比较多的上下文切换和调度延时,引起性能问题;
6.1 syschronized关键字
- 同步代码块,将可能产生访问冲突的对象作为锁对象,对访问的代码块使用synchronized括起来
synchronized(锁对象){可能存在访问冲突的代码块}优点:灵活,可以尽量少的影响效率。 - 同步方法,使用synchronized修饰方法,则该方法在执行时会被上锁,锁对象为调用该方法的类对象。缺点:将一个大的方法进行声明会影响效率。
6.2 死锁
概念: 多个线程相互等待各自释放资源,导致都停止执行的状态。某一同步代码块同时拥有两个以上对象的锁时,可能会发生死锁问题。
产生死锁的四个必要条件:
- 互斥条件:一个资源每次只能被一个进程使用
- 保持和请求条件:一个进程因请求资源被阻塞是,对已获得的资源保持不释放。
- 不剥夺条件:进程缺少资源时,不能剥夺其他进程的资源
- 循环等待条件:若干进程间形成一种头尾相接相互等待的关系。
实例:
public class DeadLock {
public static void main(String[] args) {
new MakeUp("白雪公主",0).start();
new MakeUp("灰姑娘",1).start();
}
}
class Mirror{ //镜子类
}
class Lipstick{ //口红类
}
class MakeUp extends Thread{ //化妆
static Mirror mirror = new Mirror();
static Lipstick lipstick = new Lipstick();
String name; //名字
int choice; //化妆的选择
public MakeUp(String name,int choice){
this.name = name;
this.choice = choice;
}
public void make() throws InterruptedException {
if(choice == 0){//第一种化妆方式
synchronized (mirror){
Thread.sleep(1000);
System.out.println(name+"拿起了镜子");
synchronized (lipstick){
Thread.sleep(2000);
System.out.println(name+"拿起了口红");
}
}
}
if(choice == 1){//第二种化妆方式
synchronized (lipstick){
Thread.sleep(2000);
System.out.println(name+"拿起了口红");
synchronized (mirror){
Thread.sleep(1000);
System.out.println(name+"拿起了镜子");
}
}
}
}
@Override
public void run() {
try {
make();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
6.3 Lock锁
JDK1.5以后提供了更强大的线程同步机制——通过显示定义的同步锁对象来实现同步。同步锁使用Lock对象充当。ReentrantLock类实现了Lock,拥有与synchronized相同的并发性和内存语义,较为常用。
Lock锁的一般使用方法:
class A{
private final ReentrantLock lock = new ReentrantLock();
public void fun(){
lock.lock();
try{
//可能有冲突的代码块
}finally{
lock.unlock();
}
}
}
实例:
import java.util.concurrent.locks.ReentrantLock;
public class LockTest {
public static void main(String[] args) {
BuyTicketLock buyTicketLock = new BuyTicketLock();
new Thread(buyTicketLock).start();
new Thread(buyTicketLock).start();
new Thread(buyTicketLock).start();
}
}
class BuyTicketLock implements Runnable{
private int ticket = 10;
//Lock在使用时,必须保证多个线程使用的是同一把锁
private final ReentrantLock lock = new ReentrantLock();
@Override
public void run() {
while (true){
lock.lock();
try {
if(ticket <=0){
break;
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(ticket--);
}finally {
lock.unlock();
}
}
}
}
synchronized与Lock对比:
- Lock是显式锁(手动开关,别忘记关锁),synchronized是隐式锁,出了作用域自动释放
- Lock只有代码锁没有方法锁
- 使用Lock锁性能更好,且具有更好的扩展性
- synchronized通过JVM实现,Lock通过JDK实现
- 优先使用顺序:Lock > 同步代码块 > 同步方法
7、线程同步协作
7.1 生产者消费者问题
描述: 线程分为两类,一类为生产者,负责生产产品;一类为消费者,负责消费产品。生产者要先生产,消费者才能消费;消费者消费后,生产者才能重新生产。
存在的问题: 在生产者消费者问题中,仅有syschronized是不够的,它只能阻止并发更新同一个共享资源,而不能实现线程之间的消息传递(通信)。
实现通信的方法:
- wait() notify() notifyAll()
(注:都是Object类中的方法,都只能在同步方法或者同步代码块中使用,否则会抛出IllegalMonitorStateException异常)

- await() signal() signalAll()
相比于 wait() 这种等待方式,await() 可以指定等待的条件,因此更加灵活。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class TestPC03 {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(2);
AwaitSignalExample awaitSignalExample = new AwaitSignalExample();
executorService.execute(()->{
awaitSignalExample.after();});
executorService.execute(()->{
awaitSignalExample.before();});
executorService.shutdown();
}
}
class AwaitSignalExample{
private Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
public void before(){
lock.lock();
try {
System.out.println("before");
condition.signalAll();
}finally {
lock.unlock();
}
}
public void after(){
lock.lock();
try {
condition.await();
System.out.println("after");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
7.2 管程法
在生产者和消费者之间设置一个缓冲区,生产者将生产好的数据放入缓冲区,消费者从缓冲区中取数据。
//生产者消费者问题——>管程法
public class TestPC01 {
public static void main(String[] args) {
SysContainer sysContainer = new SysContainer();
new Producer(sysContainer).start();
new Consumer(sysContainer).start();
}
}
//生产者
class Producer extends Thread{
SysContainer sysContainer;
public Producer(SysContainer sysContainer){
this.sysContainer = sysContainer;
}
@Override
public void run() {
for (int i = 0; i < 100; i++) { //一共生产100个产品
try {
sysContainer.push(new Food(i));
System.out.println("生产者生产:"+i);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
//消费者
class Consumer extends Thread{
SysContainer sysContainer;
public Consumer(SysContainer sysContainer){
this.sysContainer = sysContainer;
}
@Override
public void run() {
for (int i = 0; i < 100; i++) { //消费者消费100个产品
try {
System.out.println("消费者消费:"+i);
sysContainer.pop();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
//产品
class Food{
int id; //产品编号
public Food(int id){
this.id = id;
}
}
//缓冲区
class SysContainer{
Food[] foods = new Food[10];
int count = 0;//记录产品的数量
//消费产品
public synchronized Food pop() throws InterruptedException {
//进行消费
if(count==0){
this.wait();
}
count--;
Food food = foods[count];
this.notifyAll();
return food;
}
//生产产品
public synchronized void push(Food food) throws InterruptedException {
//进行生产
if(count==foods.length){
this.wait();
}
foods[count]=food;
count++;
this.notifyAll();
}
}
7.3 标志位解决
通过设置一个标志位,来控制生产者和消费者的顺序关系。
//生产者消费者问题——>标志位法
public class TestPC02 {
public static void main(String[] args) {
TV tv = new TV();
new Player(tv).start();
new Watcher(tv).start();
}
}
class Player extends Thread{ //演员
TV tv;
public Player(TV tv){
this.tv=tv;
}
@Override
public void run() {
for (int i = 0; i < 20; i++) {
try {
tv.play();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class Watcher extends Thread{ //观众
TV tv;
public Watcher(TV tv){
this.tv=tv;
}
@Override
public void run() {
for (int i = 0; i < 20; i++) {
try {
tv.watch();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class TV{
boolean show=false;
//演员表演
public synchronized void play() throws InterruptedException {
if(show){
this.wait();
}
show = !show;
System.out.println("演员进行了表演!");
this.notifyAll();
}
//观众看表演
public synchronized void watch() throws InterruptedException {
if(!show){
this.wait();
}
show = !show;
System.out.println("观众观看了!");
this.notifyAll();
}
}
8、java中的所有锁
Java提供了种类丰富的锁,每种锁因其特性的不同,在适当的场景下能够展现出非常高的效率。
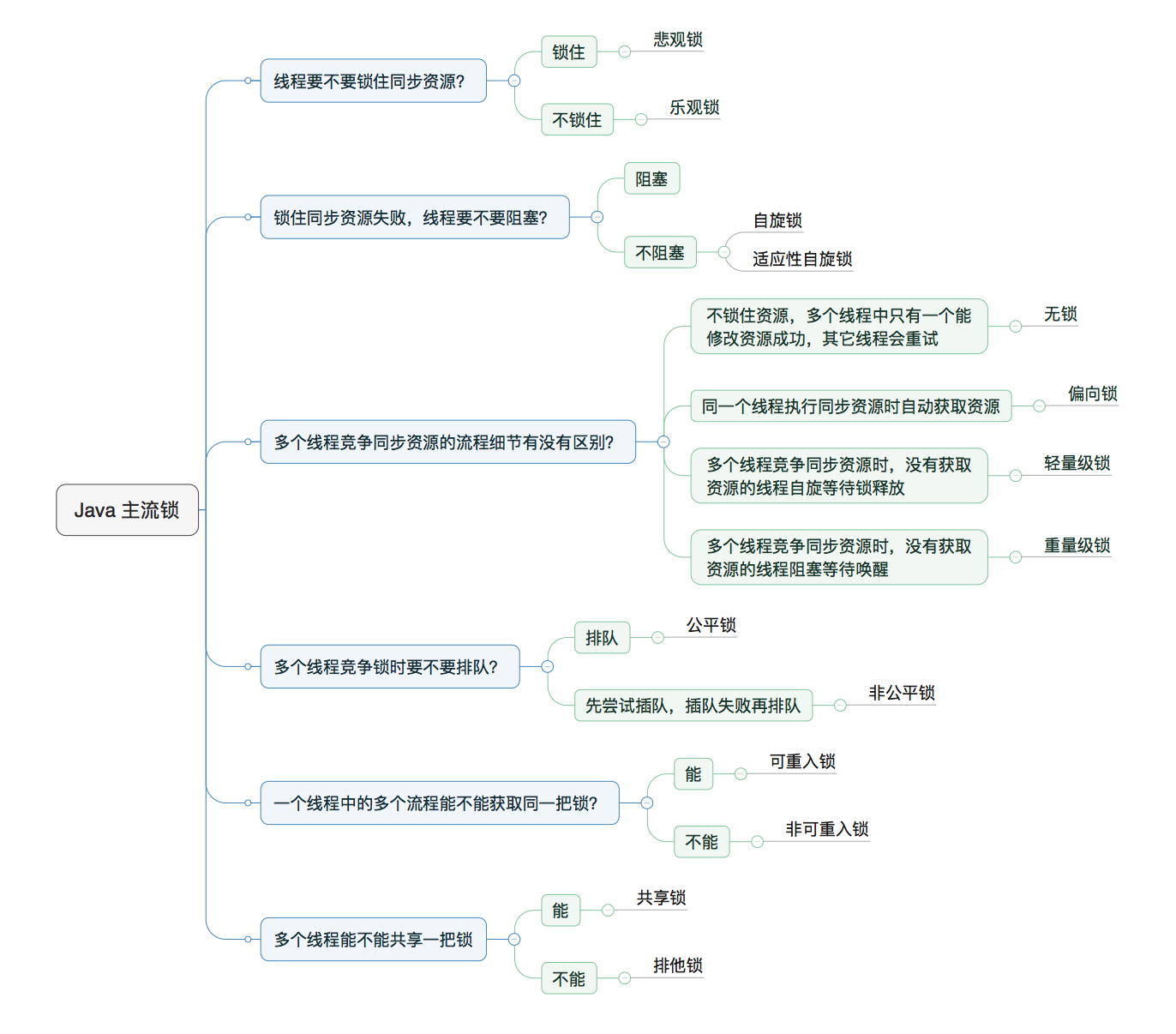
8.1 悲观锁 & 乐观锁
悲观锁: 认为自己在使用数据的时候一定有别的线程来修改数据,因此在获取数据的时候会先加锁,确保数据不会被别的线程修改。(ps:synchronized关键字和Lock的实现类)
乐观锁: 认为自己在使用数据时不会有别的线程修改数据,所以不会添加锁,只是在更新数据的时候去判断之前是否有线程更新个数据。如果该数据没有被更新,当前线程将自己修改的数据成功写入。如果数据已经被更新,则根据不同的实现方式执行不同的操作(例如报错或者自动重试)。(ps:CAS操作,具体见后文)
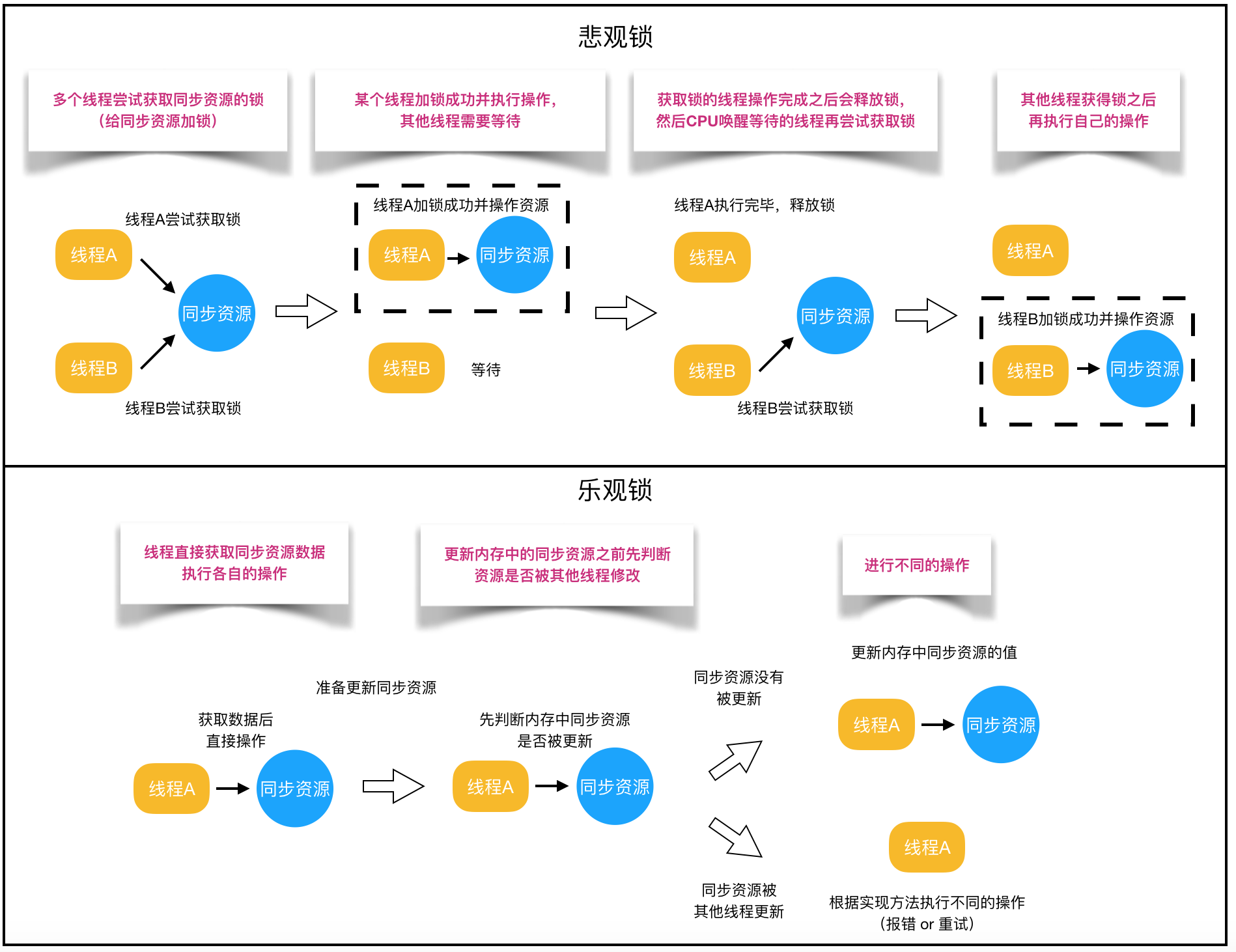
适用场景:
悲观锁适合写操作多的场景,先加锁可以保证写操作时数据正确。
乐观锁适合读操作多的场景,不加锁的特点能够使其读操作的性能大幅提升。
8.2自旋锁 & 适应性自旋锁
背景知识: 阻塞或唤醒一个Java线程需要操作系统切换CPU状态来完成,需要耗费处理器时间。如果同步代码块中的内容简单,状态转换消耗的时间有可能比用户代码执行的时间还要长。为了这一小段时间去切换线程,线程挂起和恢复现场的花费可能会让系统得不偿失。
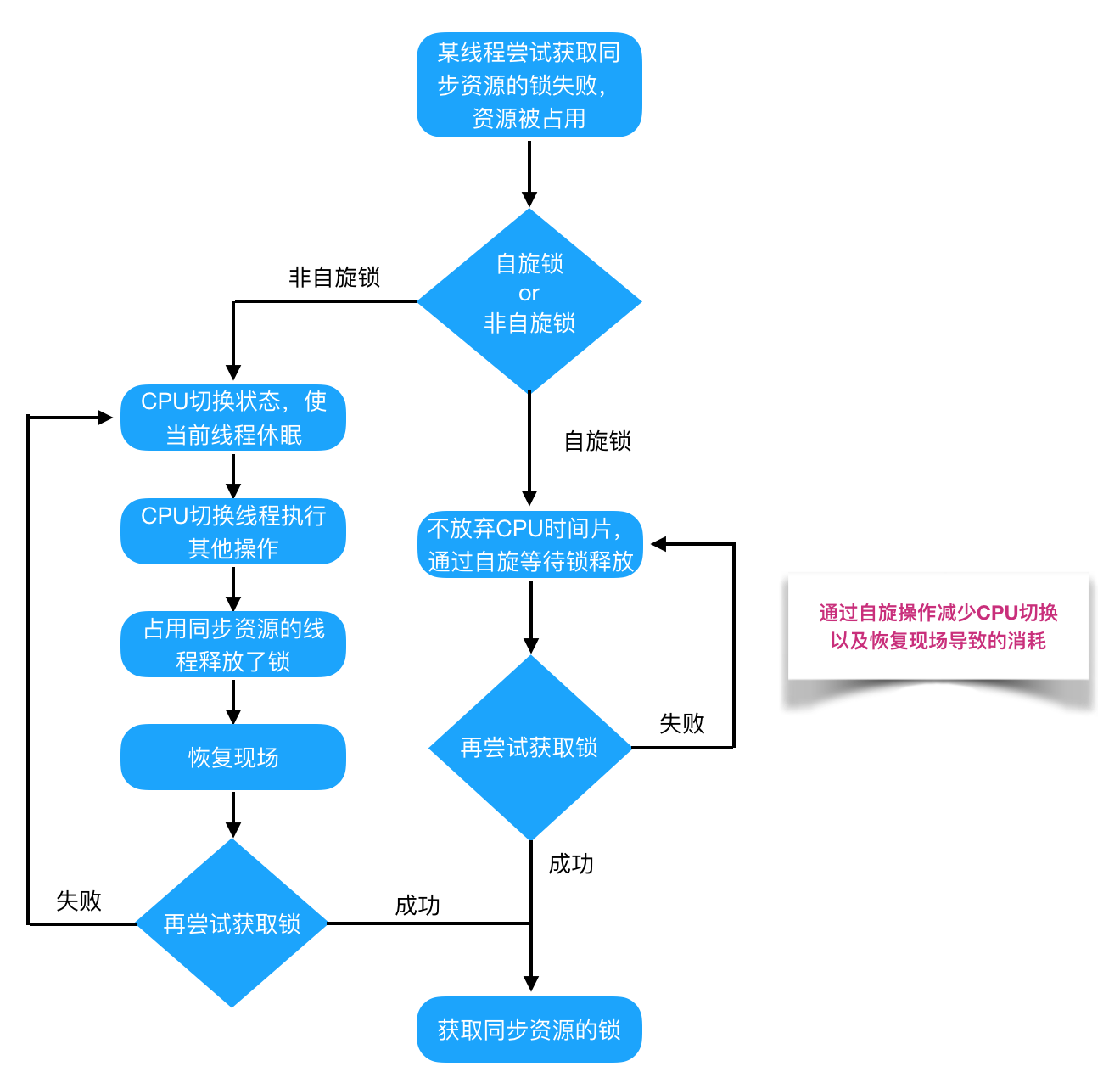
自旋锁: 就是该线程获取同步资源的锁失败,资源被占用时,不放弃CPU时间片,通过自旋等待其他线程释放锁,那么当前线程就可以不必阻塞而是直接获取同步资源,从而避免切换线程的开销。自旋锁的实现原理同样也是CAS。
(理解:相当于开车遇到红灯被阻塞,如果停车再重启可能很耗油,可以选择在原地循环转圈 ,然后等到绿灯再开进去,避免了关闭发动机再启动的消耗。)
缺点:如果锁被占用的时间很长,那么自旋的线程只会白浪费处理器资源。
适应性自旋锁: JDK 1.6中引入了自适应自旋锁。自旋的时间不再固定了,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定的。有了自适应自旋,JVM对程序的锁的状态预测会越来越准确。
8.3 无锁 & 偏向锁 & 轻量级锁 & 重量级锁
无锁: 程序不会有资源和锁的竞争,那么就不需要加锁。
偏向锁: 一段同步代码一直被一个线程所访问,那么该线程就会自动获取锁,从而降低了获取锁的代价。通过检测线程的私有变量Mark Word是否存储着指向当前线程的偏向锁来控制线程是否能进入同步块,这样在无线程竞争的情况下减少了不必要的轻量级锁的执行开销。需要注意的是,只有遇到其他线程竞争偏向锁时,持有偏向锁的线程才会释放偏向锁,线程不会主动释放。
轻量级锁: 当锁是偏向锁时,被其他线程所访问,偏向锁就会升级为轻量锁,其他线程通过自旋的形式尝试获取锁,不会阻塞,从而提高性能。
重量级锁: 等待锁的所有线程进入阻塞状态。
综上,偏向锁通过对比Mark Word解决加锁问题,避免执行CAS操作。而轻量级锁是通过用CAS操作和自旋来解决加锁问题,避免线程阻塞和唤醒而影响性能。重量级锁是将除了拥有锁的线程以外的线程都阻塞。
8.4 公平锁 & 非公平锁
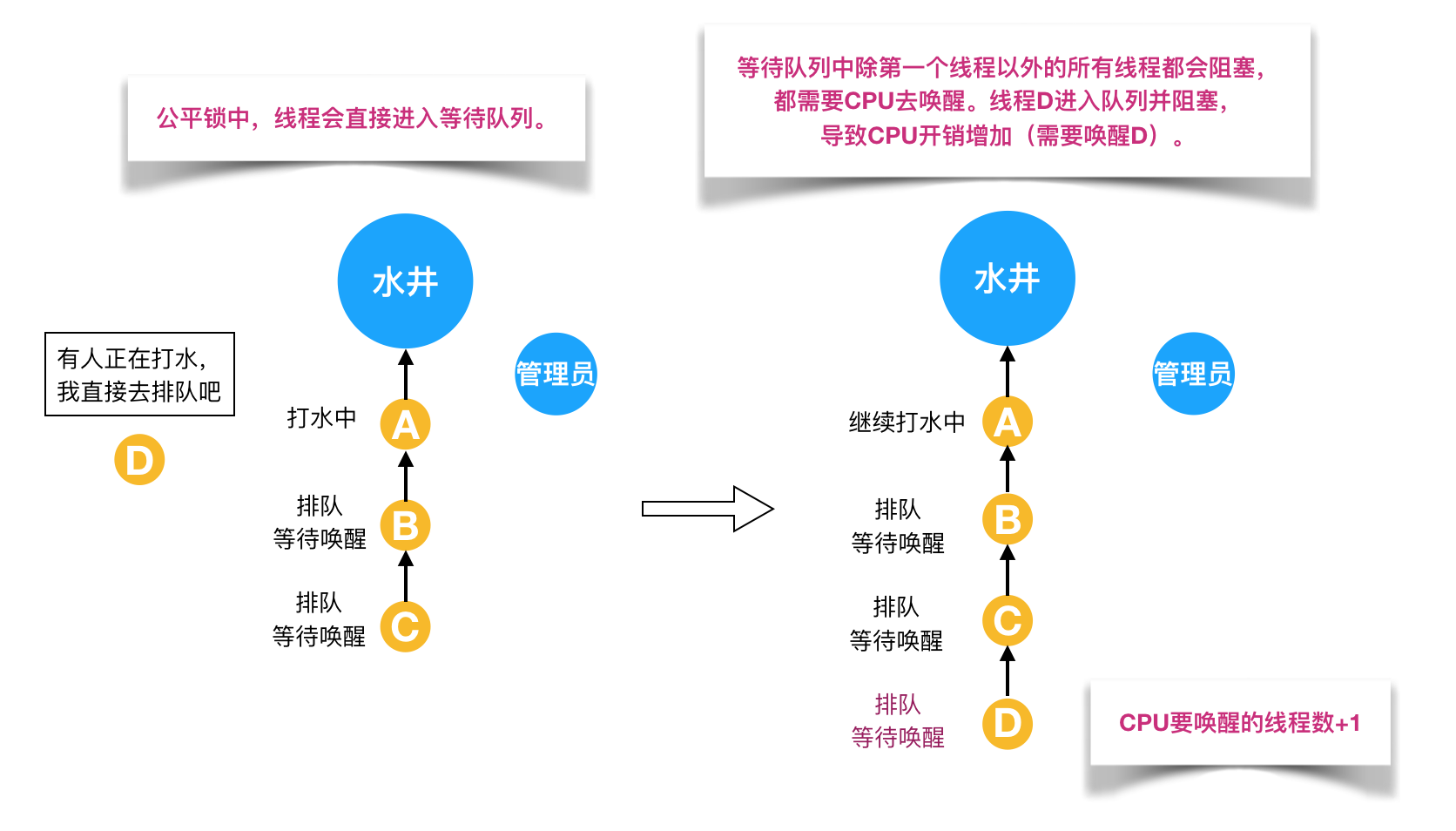
公平锁: 指多个线程按照申请锁的顺序获取锁,线程进入一个等待队列,队列中第一个线程能够获取锁。优点:可以保证等待锁的进程不会被饿死。缺点:整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,开销大。
非公平锁: 多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待。但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁,所以非公平锁有可能出现后申请锁的线程先获取锁的场景。 优点:线程有几率不阻塞直接获得锁,整体吞吐效率高。缺点:有些线程可能饿死或者等很长时间才能获取锁。
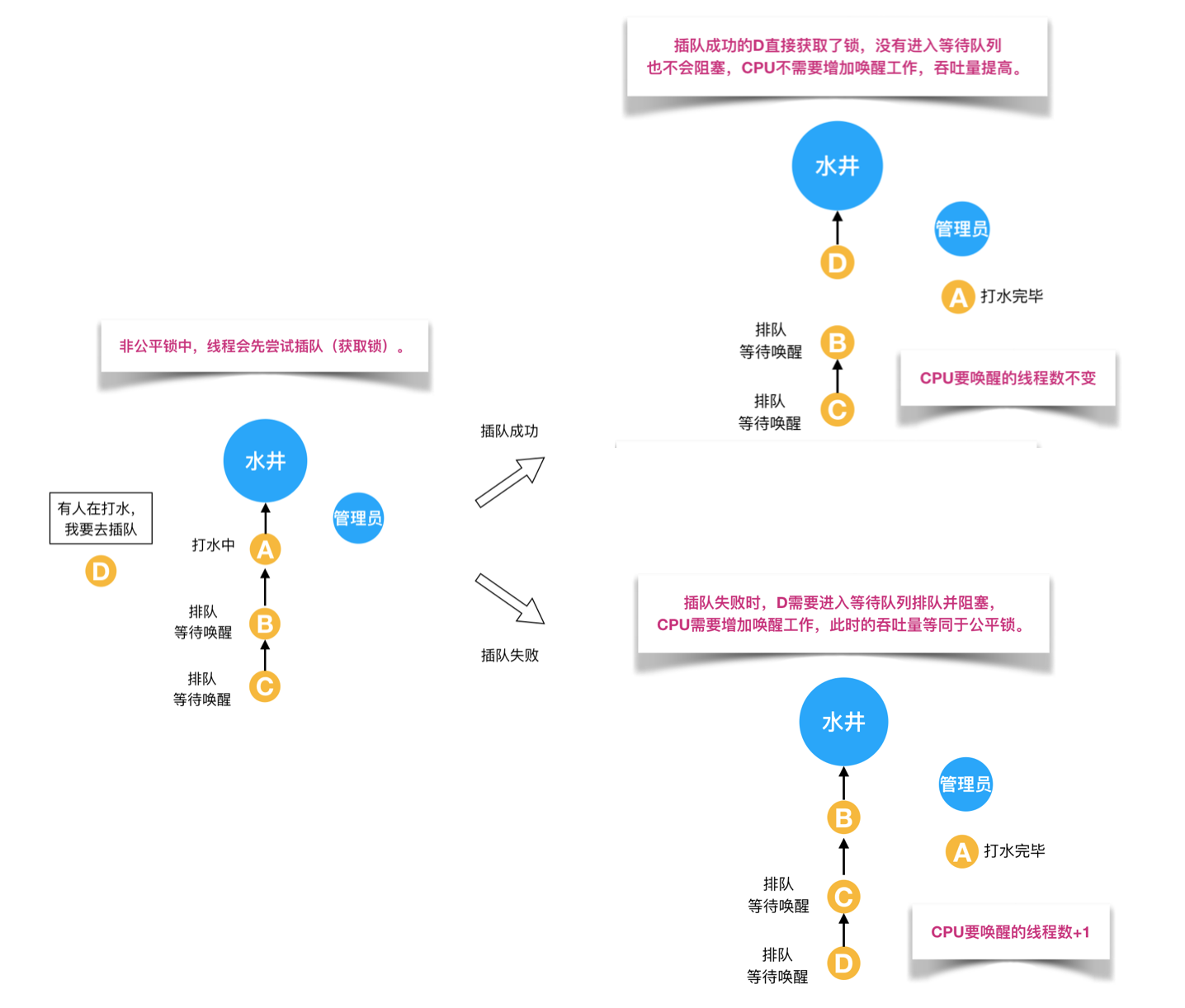
synchronized是非公平锁。
8.5 可重入锁 & 非可重入锁
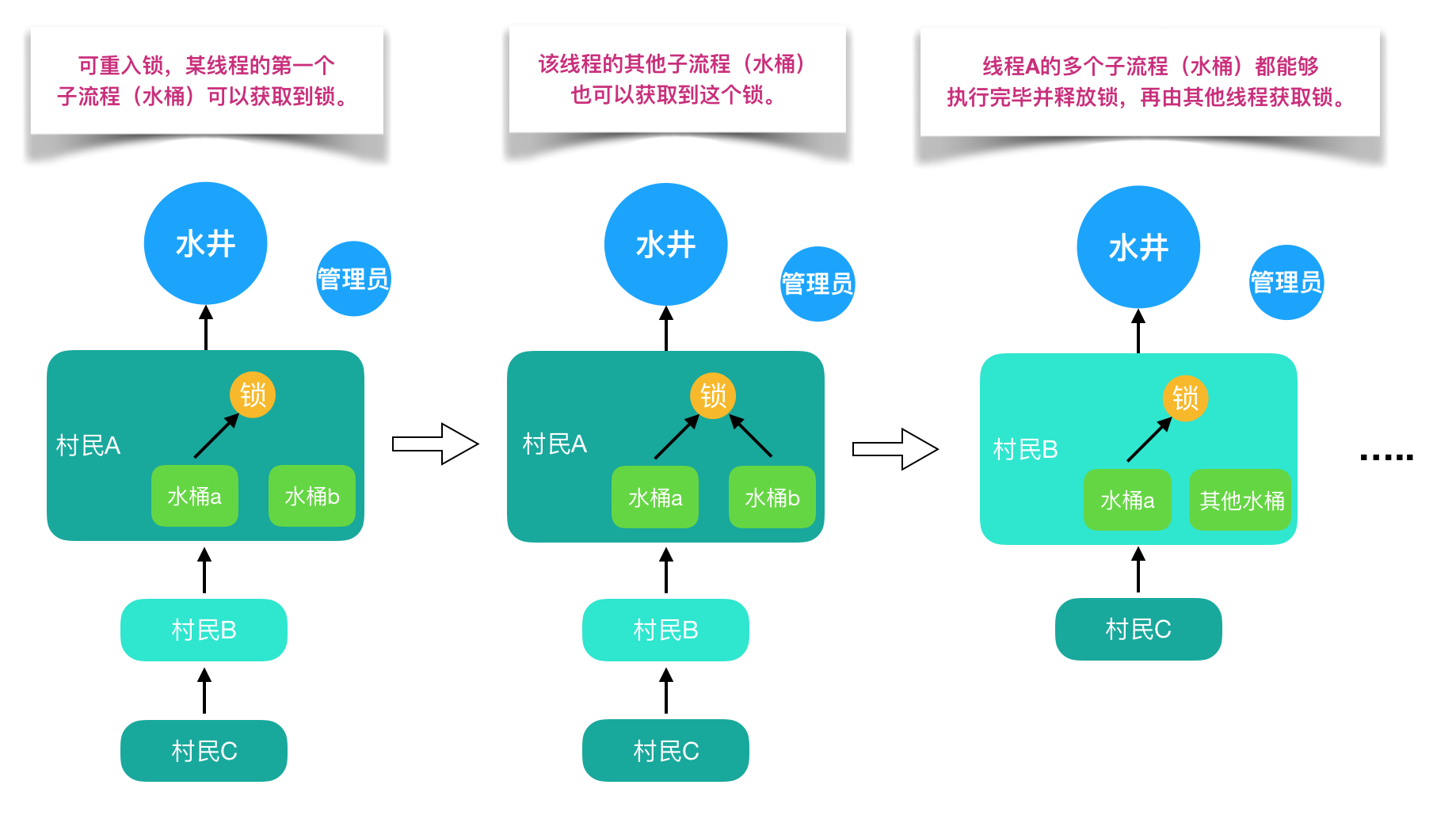
可重入锁: 也叫递归锁,同一个线程在外层方法获取到锁时,该线程内层方法也会自动获取到锁(前提是锁对象是同一个对象或者class)。ReentrantLock和synchronized都是可重入锁。优点:可一定程度上避免死锁
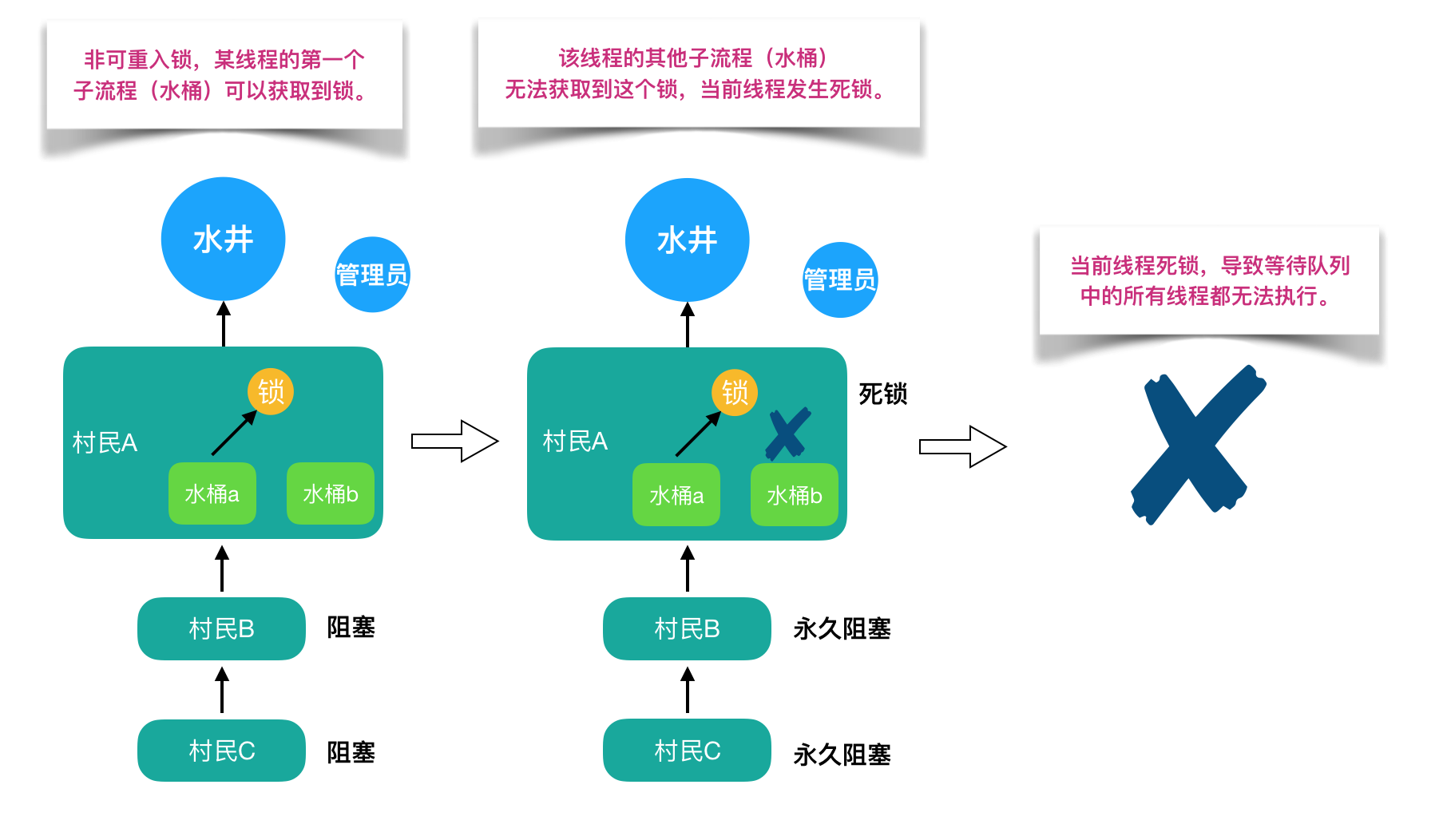
非可重入锁: 线程外层方法获取到锁时,内层方法需要等到外层方法释放锁后才能重新获取到锁。由于外层方法需要等到内层方法执行完后才能释放锁,所以内层方法永远无法获取锁,于是产生了死锁。
8.6 独享锁(排他锁) & 共享锁
独享锁: 也叫排它锁,该锁只能被一个线程持有。如果线程对一个共享数据加上排它锁后,其他线程则无法为该数据添加任何类型的锁。synchronized和Lock的实现类就是独享锁。
共享锁: 可被多个线程持有。一个线程对共享数据添加共享锁后,其他线程也可以对其添加共享锁,不能添加排它锁。获得共享锁的线程只能读不能修改数据。
ReentrantReadWriteLock有两把锁:ReadLock和WriteLock,读锁是共享锁,写锁是排他锁。读锁的共享锁可保证并发读非常高效;而读写、写读、写写的过程互斥,因为读锁和写锁是分离的。
9、深入理解Java多线程
9.1 Synchronized原理分析
9.1.1 加锁和释放锁的原理
先创建如下代码:
public class SynchronizedDemo2 {
Object object = new Object();
public void method1() {
synchronized (object) {
}
method2();
}
private static void method2() {
}
}
//编译源代码,生成.class文件
javac SynchronizedDemo2.java
//反编译,查看.class文件信息
javap -verbose SynchronizedDemo2.class
得到如下信息:
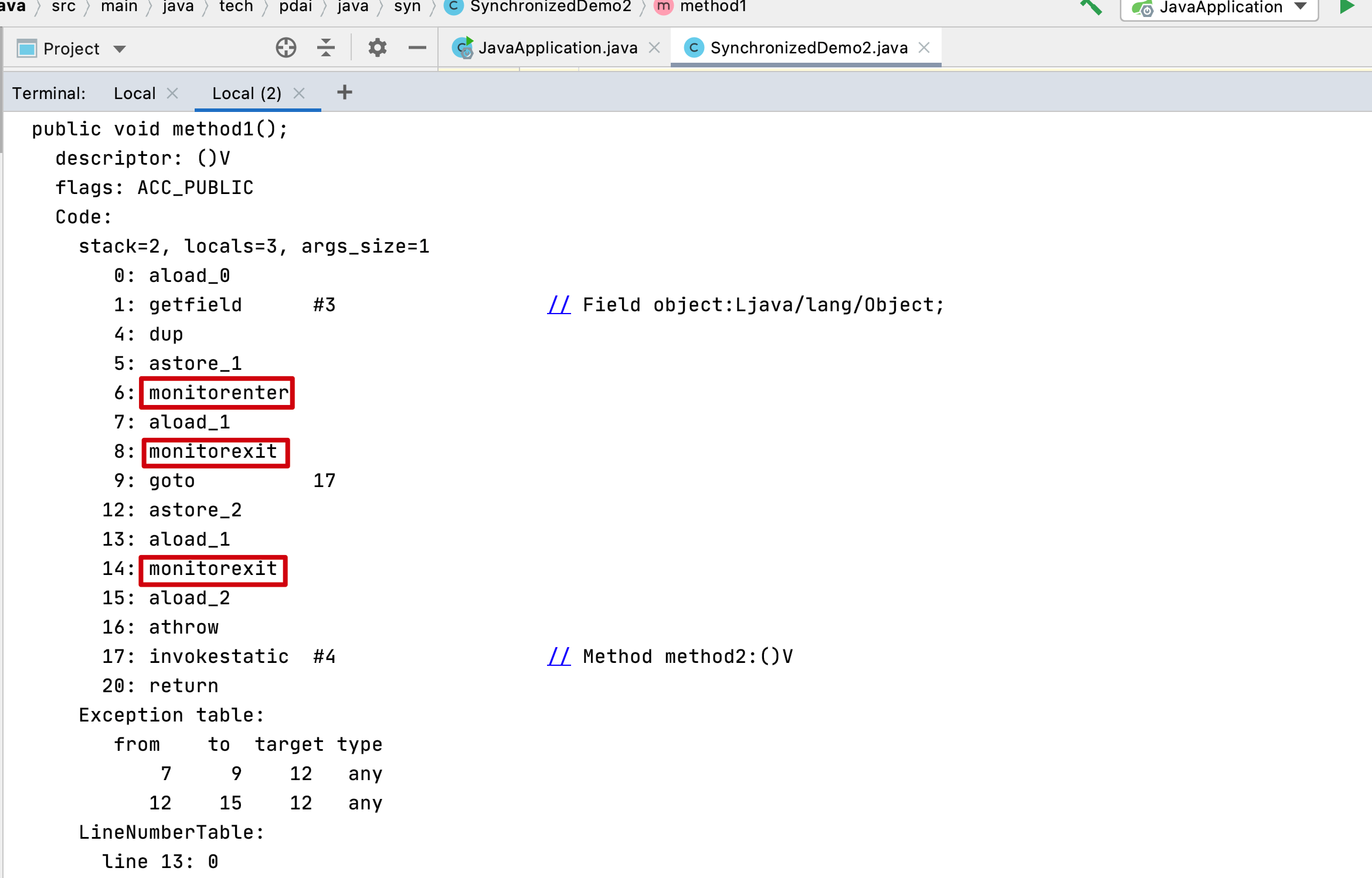
说明: Monitorenter和Monitorexit指令会使其锁计数器(monitor)加1或者减1。monitor在同一时间只能被一个线程获得,一个线程在尝试获得monitor锁的时候,monitorenter指令会发生如下3中情况之一:
1.monitor计数器为0,意味着目前还没有被获得,那这个线程就会立刻获得然后把锁计数器+1,别的线程再想获取,就需要等待;
2.如果这个线程已经拿到了这个锁,又重入了这把锁,那锁计数器就会累加;
3.这把锁已经被别的线程获取了,等待锁释放。
9.1.2 可重入原理
每一个可重入锁都会关联一个线程ID和一个锁计数器,如果锁计数器是0,代表该锁没有被占用,直接获取锁,将线程ID替换成自己的线程ID。如果锁计数器不是0,代表有线程在访问该方法。如果线程ID是自己,则不需要重新获得锁,锁计数器+1,执行同步代码。如果ID不是自己,则进行阻塞。
9.1.3 保证可见性的原理——Java内存模型和happens-before规则
happens-before原理:JVM会对代码执行进行重排序优化,为了防止优化对线程安全的影响,需要用happens-before原则定义一些禁止优化编译的场景。
- 规则一:程序的顺序性规则
一个线程中,前面的操作一定happens-before后面的任何操作。(注:可能有重排序优化,但是这些优化不会影响结果) - 规则二:volatile规则
volatile变量的写操作happens-before后续对它的读操作。 - 规则三:传递性规则
如果A happens-before B,B happens-before C,那么A happens-before C。 - 规则四:管程中的锁规则
对一个锁的解锁操作,happens-before后续对这个锁的加锁操作。 - 规则五:线程start()规则
如果线程A中通过.start()启动线程B,则.start()操作happens-before线程B中的所有操作。
var = 0;
Thread B = new Thread(()->{
// 主线程调用B.start()之前
// 所有对共享变量的修改,此处皆可见
sout(var); // 此例中,var==77
});
// 此处对共享变量var修改
var = 77;//happens-before start();start()hanppens-before 线程中的任意操作。
// 主线程启动子线程
B.start();
- 规则六:线程join()规则
线程A等待线程B执行,只有当子线程B执行完毕后,主线程A可以看到线程B的所有操作。也就是说,子线程B中的任意操作happens-before 线程A从ThreadB.join()操作成功返回。
9.2 volatile详解
9.2.1 volatile&单例模式
对于一个多线程单例模式:
public class Singleton {
public static volatile Singleton singleton;
private Singleton(){
//私有化构造函数
}
public static Singleton getSingleton(){
if(singleton == null){ //双重检查加锁(DCL)
synchronized (Singleton.class){
if(singleton ==null){
singleton = new Singleton();
}
}
}
return singleton;
}
}
虽然使用了双重检查加锁(DCL),也可能出现以外。java线程工作内存原理导致:由于每个线程拥有自己的一个高速缓存区——线程工作内存,线程中获取到的实例在线程执行结束后,需要放入主内存,在放入的间隙中线程已经释放了锁,这时有能有其他线程趁机产生一个新的实例也放回主存中,这就违背了单例模式。
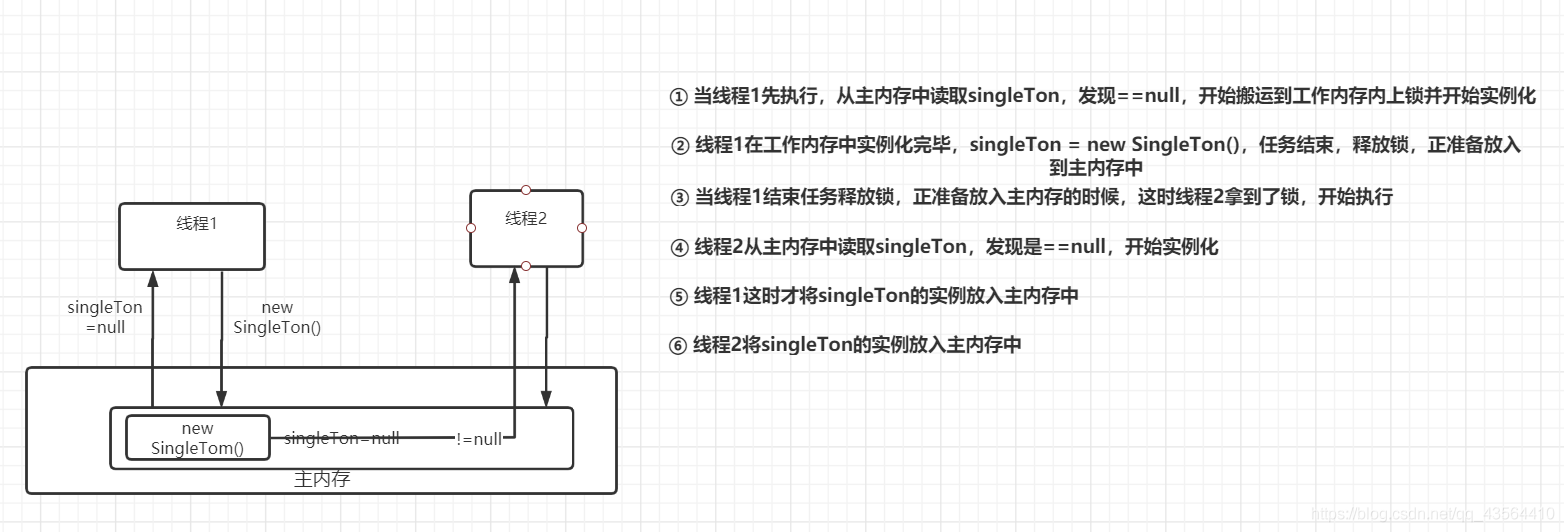
解决的办法:使用valotile使主内存中的对象对线程可见,来解决上述问题
以下是完美的多线程下的单例模式:
/**
* 双重检查锁+volatile
*/
class ThreadSingleTon2{
/**
* 使用volatile使主内存中的singleTon对线程可见
*/
private volatile static ThreadSingleTon2 singleTon = null;
private ThreadSingleTon2(){}
/**
* 双重检查锁 具体解释看代码注释
* @return
*/
public static ThreadSingleTon2 getThreadSingleTon(){
if(getThreadSingleTon()==null) {
//如果对象为空,则是第一次实例化,这时锁住对象
//给ThreadSingleTon.class加锁也可以
synchronized (singleTon){
//第二次判断是否为空,防止多线程操作时,在执行第一次判断后另一个线程完成了实例化
if(singleTon==null){
singleTon = new ThreadSingleTon2();
}
}
}
return singleTon;
}
/* 如果该对象被用于序列化,可以保证对象在序列化前后保持一致 */
public Object readResolve() {
return this.singleTon;
}
}
9.2.2 volatile实现可见性
可见性问题主要指一个线程修改了共享变量值,而另一个线程却看不到。引起可见性问题的主要原因是每个线程拥有自己的一个高速缓存区——线程工作内存。volatile关键字能有效的解决这个问题。
实例:
import java.util.Scanner;
public class VolatileTest {
//使用volatile修饰后,输入线程修改user.name时,监控线程能立马发现
//不使用它修饰时,可能修改好几次user.name,监控线程都发现不了
static volatile User user = new User("小明");
public static void main(String[] args) {
new Thread(()->{
while (true){
if(!user.getName().equals("小明")){
System.out.println("当前已不是小明,用户变更为"+user.getName());
break;
}
}
}).start();
new Thread(()->{
while (true){
Scanner scanner = new Scanner(System.in);
String s = scanner.next();
user.setName(s);
if(!user.getName().equals("小明"))break;
}
}).start();
}
}
class User{
private String name;
public User(String name){
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
9.2.3 volatile保证原子性(单次读/写)
volatile不能保证完全的原子性,只能保证单次的读/写操作具有原子性。先从如下两个问题来理解:
-
i++为什么不能保证原子性?
i++其实是一个复合操作,包括三步骤:读取i的值,对i加1,将i的值写回内存。volatile是无法保证这三个操作是具有原子性的。 -
共享的long和double变量的为什么要用volatile?
因为long和double两种数据类型的操作可分为高32位和低32位两部分,因此普通的long或double类型读/写可能不是原子的。(目前各种平台下的商用虚拟机都选择把 64 位数据的读写操作作为原子操作来对待,一般也不会出错)
9.2.4 volatile的实现原理
有序性实现原理: 基于内存屏障(Memory Barrier)和happens-before规则
内存屏障,也叫内存栅栏,是一个CPU指令。JMM为了保证读写一致性,插入特定类型内存屏障来禁止指令重排序,告诉编译器和CPU:无论什么指令都不能和这条Memory Barrier 指令重排序。
可见性实现原理: 通过Lock前缀指令和触发缓存一致性协议来实现
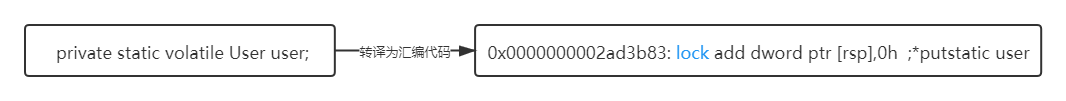
对volatiile修饰的变量执行写操作时,JVM会发送一个Lock前缀指令给CPU,CPU在执行完写操作后,会立即将新值刷新到主内存,同时因为MESI缓存一致性协议,会使其他线程中缓存该内存地址的数据无效,如果要使用该数据时就需要重新去主存中获取,从而保证了线程之间的可见性。
9.2.5 volatile的应用场景*(未做深入理解)
使用volatile的必须具备的条件:
1.对变量的写操作不依赖与当前值
2.该变量没有包含在具有其他变量的不变式中
3.只有在状态真正独立于程序内其他内容时才能使用volatile。
模式1:状态标志
也许实现 volatile 变量的规范使用仅仅是使用一个布尔状态标志,用于指示发生了一个重要的一次性事件,例如完成初始化或请求停机。
volatile boolean shutdownRequested;
......
public void shutdown() { shutdownRequested = true; }
public void doWork() {
while (!shutdownRequested) {
// do stuff
}
}
模式2:一次性安全发布(one-time safe publication)
缺乏同步会导致无法实现可见性,这使得确定何时写入对象引用而不是原始值变得更加困难。在缺乏同步的情况下,可能会遇到某个对象引用的更新值(由另一个线程写入)和该对象状态的旧值同时存在。(这就是造成著名的双重检查锁定(double-checked-locking)问题的根源,其中对象引用在没有同步的情况下进行读操作,产生的问题是您可能会看到一个更新的引用,但是仍然会通过该引用看到不完全构造的对象)。
public class BackgroundFloobleLoader {
public volatile Flooble theFlooble;
public void initInBackground() {
// do lots of stuff
theFlooble = new Flooble(); // this is the only write to theFlooble
}
}
public class SomeOtherClass {
public void doWork() {
while (true) {
// do some stuff...
// use the Flooble, but only if it is ready
if (floobleLoader.theFlooble != null)
doSomething(floobleLoader.theFlooble);
}
}
}
模式4:volatile bean 模式
在 volatile bean 模式中,JavaBean 的所有数据成员都是 volatile 类型的,并且 getter 和 setter 方法必须非常普通 —— 除了获取或设置相应的属性外,不能包含任何逻辑。此外,对于对象引用的数据成员,引用的对象必须是有效不可变的。(这将禁止具有数组值的属性,因为当数组引用被声明为 volatile 时,只有引用而不是数组本身具有 volatile 语义)。对于任何 volatile 变量,不变式或约束都不能包含 JavaBean 属性。
@ThreadSafe
public class Person {
private volatile String firstName;
private volatile String lastName;
private volatile int age;
public String getFirstName() { return firstName; }
public String getLastName() { return lastName; }
public int getAge() { return age; }
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public void setAge(int age) {
this.age = age;
}
}
模式5:开销较低的读-写锁策略
volatile 的功能还不足以实现计数器。因为 ++x 实际上是三种操作(读、添加、存储)的简单组合,如果多个线程凑巧试图同时对 volatile 计数器执行增量操作,那么它的更新值有可能会丢失。
如果读操作远远超过写操作,可以结合使用内部锁和 volatile 变量来减少公共代码路径的开销。
安全的计数器使用 synchronized 确保增量操作是原子的,并使用 volatile 保证当前结果的可见性。如果更新不频繁的话,该方法可实现更好的性能,因为读路径的开销仅仅涉及 volatile 读操作,这通常要优于一个无竞争的锁获取的开销。
@ThreadSafe
public class CheesyCounter {
// Employs the cheap read-write lock trick
// All mutative operations MUST be done with the 'this' lock held
@GuardedBy("this") private volatile int value;
public int getValue() { return value; }
public synchronized int increment() {
return value++;
}
}
模式6:双重检查(double-checked)
单例模式的一种实现方式,但很多人会忽略 volatile 关键字,因为没有该关键字,程序也可以很好的运行,只不过代码的稳定性总不是 100%,说不定在未来的某个时刻,隐藏的 bug 就出来了。
class Singleton {
private volatile static Singleton instance;
private Singleton() {
}
public static Singleton getInstance() {
if (instance == null) {
syschronized(Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
10、JUC原子类
10.1 CAS
线程安全的实现方法:
互斥同步:synchronized 和 ReentrantLock
非阻塞同步:CAS AtomicXXX
无同步方案:栈封闭,Thread Local,可重入代码
CAS:全称为Compare-And-Swap,是一条CPU原子指令,作用是先让CPU先进行两个值是否相等的比较,如果相同则更新旧值,不相同则不更新。CAS操作是原子性的,所以多线程并发使用CAS更新数据时,可以不使用锁。
原理代码:
paramObject–当前对象paramLong–内存地址paramInt–要增加的值
先取到当前对象的地址里面的值(保存原始值i),然后在比较看当前对象地址的值与i是否相同,如果相同则说明没有其他线程对i进行修改,于是使用i+paramInt更新地址中的值;如果不相同,则说明有线程修改了i的值,于是进入循环重新获取i的值,直到没有其他线程修改当前地址中的值时,才更新该地址中的值。
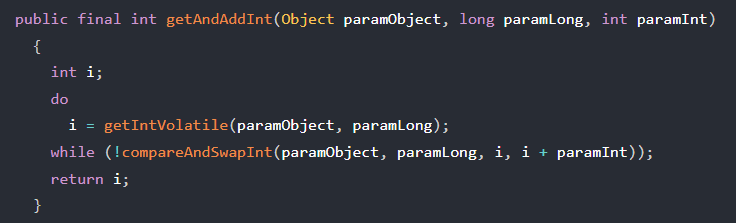
CAS使用示例:
如果不使用CAS,在高并发下,多线程同时修改一个变量的值我们需要synchronized加锁(注意:Lock底层的AQS也是基于CAS进行获取锁的)。
public class Test {
private int i=0;
public synchronized int add(){
return i++;
}
}
java中为我们提供了AtomicInteger 原子类(底层基于CAS进行更新数据的),不需要加锁就在多线程并发场景下实现数据的一致性。
public class Test {
private AtomicInteger i = new AtomicInteger(0);
public int add(){
return i.addAndGet(1);
}
}
CAS的优缺点
优点:CAS为乐观锁,解决并发问题通常性能更优。
存在的问题:
ABA问题:
CAS需要在操作值的时候,检查值有没有发生变化,比如没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时则会发现它的值没有发生变化,但是实际上却变化了。
解决方法:
1.在变量前面追加上版本号,每次变量更新的时候把版本号加1,那么A->B->A就会变成1A->2B->3A。
2.从Java 1.5开始,JDK的Atomic包里提供了一个类AtomicStampedReference来解决ABA问题。
循环时间长开销大:
自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。
只能保证一个共享变量的原子操作:
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁。
解决方法:
1.就是把多个共享变量合并成一个共享变量来操作。比如,有两个共享变量i = 2,j = a,合并一下ij = 2a,然后用CAS来操作ij。
2.从Java 1.5开始,JDK提供了AtomicReference类来保证引用对象之间的原子性,就可以把多个变量放在一个对象里来进行CAS操作。
10.2 AtomicInteger类
常用API:
public final int get():获取当前的值
public final int getAndSet(int newValue):获取当前的值,并设置新的值
public final int getAndIncrement():获取当前的值,并自增
public final int getAndDecrement():获取当前的值,并自减
public final int getAndAdd(int delta):获取当前的值,并加上预期的值
void lazySet(int newValue): 最终会设置成newValue,使用lazySet设置值后,可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
相比 Integer 的优势,多线程中让变量自增:
private volatile int count = 0;
// 若要线程安全执行执行 count++,需要加锁
public synchronized void increment() {
count++;
}
public int getCount() {
return count;
}
private AtomicInteger count = new AtomicInteger();
public void increment() {
count.incrementAndGet();
}
// 使用 AtomicInteger 后,不需要加锁,也可以实现线程安全
public int getCount() {
return count.get();
}
AtomicInteger 底层用的是volatile的变量和CAS来进行更改数据的。
- volatile保证线程的可见性,多线程并发时,一个线程修改数据,可以保证其它线程立马看到修改后的值
- CAS 保证数据更新的原子性。
10.3 JUC集合: ConcurrentHashMap类
为什么HashTable慢?
Hashtable之所以效率低下主要是因为其实现使用了synchronized关键字对put等操作进行加锁,而synchronized方法加锁是对整个对象进行加锁,也就是说在进行put等修改Hash表的操作时,锁住了整个Hash表,从而使得其表现的效率低下。
ConcurrentHashMap - JDK 1.7
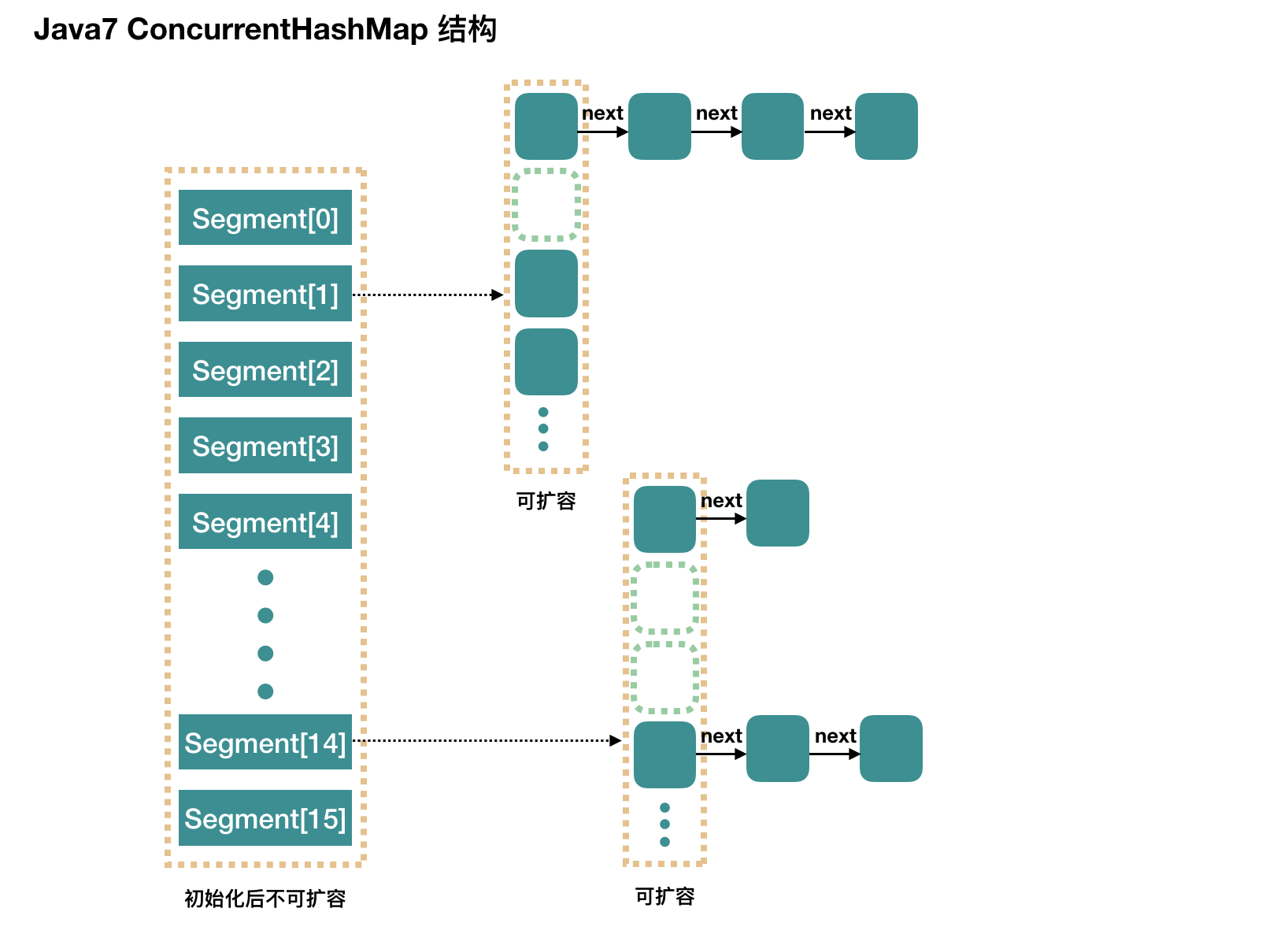
在JDK1.5~1.7版本,Java使用了分段锁机制实现ConcurrentHashMap。
原理:整个 ConcurrentHashMap 由一个个 Segment 数组组成,每个Segment元素,即每个分段则类似于一个Hashtable。这样每次put操作时先定位Segment,然后对这个segment进行加锁,segment数组的长度决定了可以同时并发的线程数。
ConcurrentHashMap - JDK 1.8
在JDK1.7之前,ConcurrentHashMap是通过分段锁机制来实现的,所以其最大并发度受Segment的个数限制。因此,在JDK1.8中,ConcurrentHashMap的实现原理摒弃了这种设计,而是选择了与HashMap类似的数组+链表+红黑树的方式实现,而加锁则采用CAS和synchronized实现。
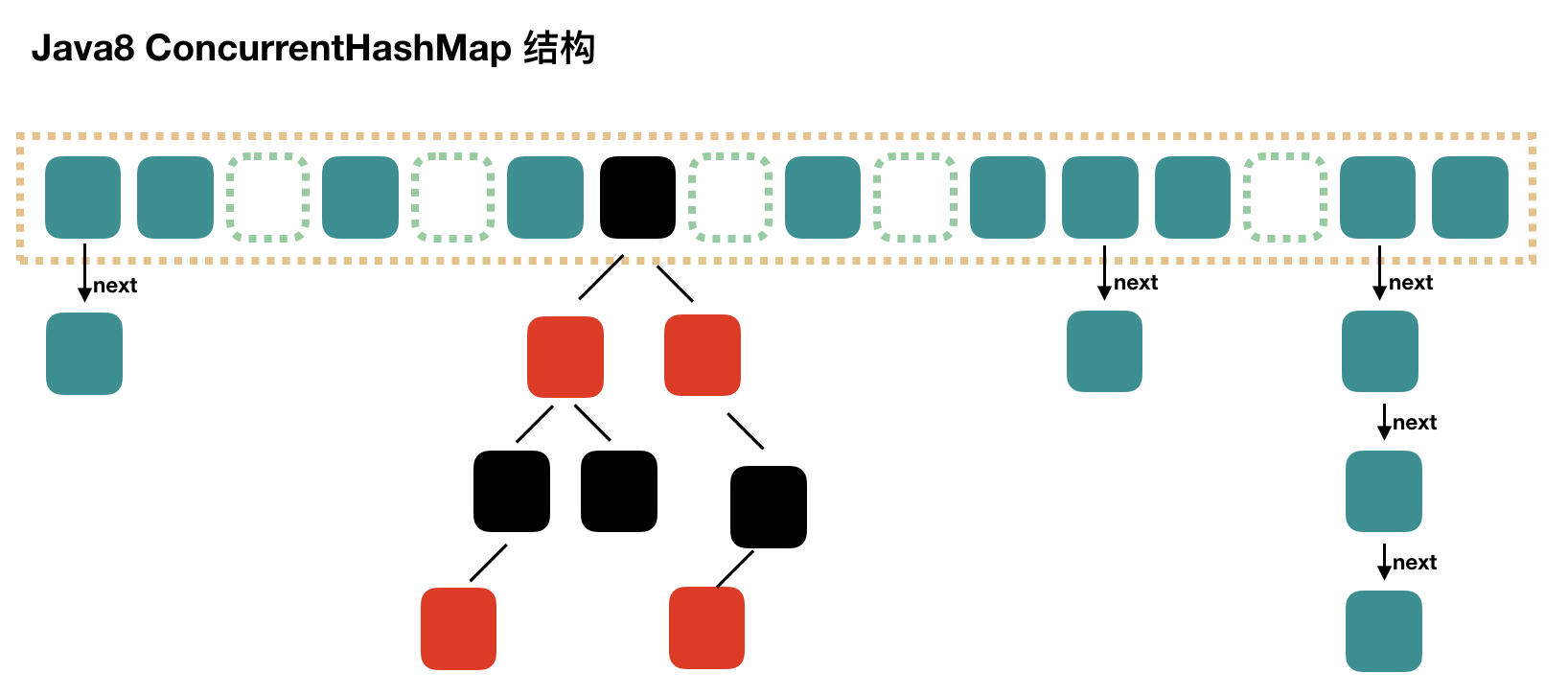
对比总结:
HashTable : 使用了synchronized关键字对put等操作进行加锁;
ConcurrentHashMap JDK1.7: 使用分段锁机制实现;
ConcurrentHashMap JDK1.8: 则使用数组+链表+红黑树数据结构和CAS原子操作实现
10.4 JUC集合:ConcurrentLinkedQueue类
说明: 一个基于链表的线程安全队列,此队列不允许使用null元素。
要想用线程安全的队列有哪些选择?
Vector,Collections.synchronizedList(List<T> list), ConcurrentLinkedQueue等
ConcurrentLinkedQueue使用实例:
import java.util.concurrent.ConcurrentLinkedQueue;
class PutThread extends Thread {
private ConcurrentLinkedQueue<Integer> clq;
public PutThread(ConcurrentLinkedQueue<Integer> clq) {
this.clq = clq;
}
public void run() {
for (int i = 0; i < 10; i++) {
try {
System.out.println("add " + i);
clq.add(i);
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class GetThread extends Thread {
private ConcurrentLinkedQueue<Integer> clq;
public GetThread(ConcurrentLinkedQueue<Integer> clq) {
this.clq = clq;
}
public void run() {
for (int i = 0; i < 10; i++) {
try {
System.out.println("poll " + clq.poll());
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class ConcurrentLinkedQueueDemo {
public static void main(String[] args) {
ConcurrentLinkedQueue<Integer> clq = new ConcurrentLinkedQueue<Integer>();
PutThread p1 = new PutThread(clq);
GetThread g1 = new GetThread(clq);
p1.start();
g1.start();
}
}
GetThread线程不会因为ConcurrentLinkedQueue队列为空而等待,而是直接返回null,所以当实现队列不空时,等待时,则需要用户自己实现等待逻辑。
HOPS(延迟更新的策略)的设计
tail和head是延迟更新的,这样做减少CAS更新的操作,无疑可以大大提升入队的操作效率。两者更新触发时机为:
tail更新触发时机: 当tail指向的节点的下一个节点不为null的时候,会执行定位队列真正的队尾节点的操作,找到队尾节点后完成插入之后才会通过casTail进行tail更新;当tail指向的节点的下一个节点为null的时候,只插入节点不更新tail。
head更新触发时机: 当head指向的节点的item域为null的时候,会执行定位队列真正的队头节点的操作,找到队头节点后完成删除之后才会通过updateHead进行head更新;当head指向的节点的item域不为null的时候,只删除节点不更新head。
ConcurrentLinkedQueue适合的场景:
1.具有并发情况下的队列
2.并发量较小的情况
10.5 JUC集合: BlockingQueue接口
BlockingQueue 通常用于一个线程生产对象,而另外一个线程消费这些对象的场景。下图是对这个原理的阐述:
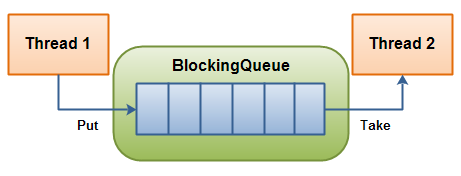
说明: 一个线程作为生产者,生产产品放入BlockingQueue队列中;另一个线程作为消费者,从BlockingQueue中取产品。当BlockingQueue容器满时(到达设置的临界值),生产者线程阻塞等待消费者线程消费;当BlockingQueue容器空时,消费者线程阻塞等待生产者线程生产。
BlockingQueue 的方法:
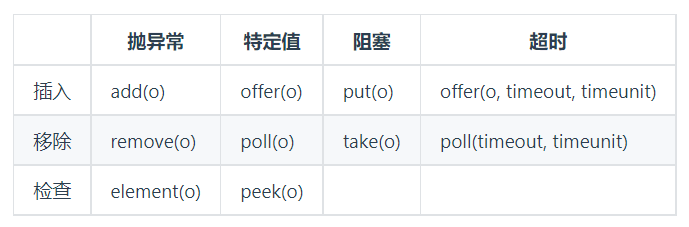
方法说明:
抛异常: 如果试图的操作无法立即执行,抛一个异常。
特定值: 如果试图的操作无法立即执行,返回一个特定的值(常常是 true / false)。
阻塞: 如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行。
超时: 如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。返回一个特定值以告知该操作是否成功(典型的是 true / false)。
10.6 JUC集合: BlockingDeque接口
在线程既是一个队列的生产者又是这个队列的消费者的时候可以使用到 BlockingDeque,其底层是一个双向链表,原理如下:
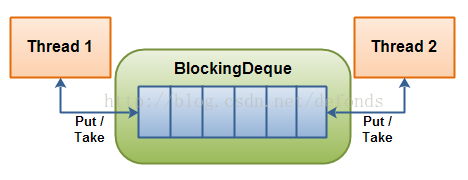
说明: 线程1和线程2两个线程既可以是生产者也可以是消费者,当BlockingDeque为空是,两个线程生产的行为会被阻塞进入等待;当BlockingDeque满时,两个线程消费的行为会被阻塞进入等待。
BlockingDeque 的方法:
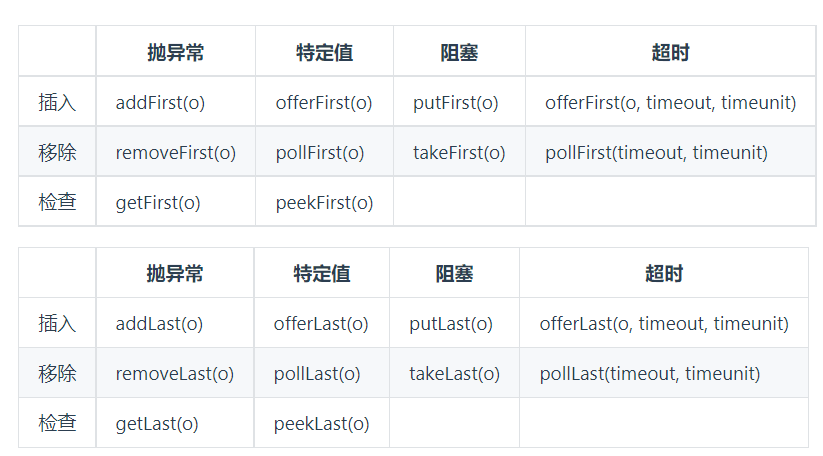
抛异常: 如果试图的操作无法立即执行,抛一个异常。
特定值: 如果试图的操作无法立即执行,返回一个特定的值(常常是 true / false)。
阻塞: 如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行。
超时: 如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。返回一个特定值以告知该操作是否成功(典型的是 true / false)。
10.7 线程阻塞接口的实现类
ArrayBlockingQueue:数组阻塞队列 ,实现了BlockingQueue接口,底层是数组
DelayQueue:延迟队列,实现了 BlockingQueue 接口,对元素进行持有直到一个特定的延迟到期。将会在每个元素的 getDelay() 方法返回的值的时间段之后才释放掉该元素。如果返回的是 0 或者负值,延迟将被认为过期,该元素将会在 DelayQueue 的下一次 take 被调用的时候被释放掉。
LinkedBlockingQueue:链阻塞队列 ,实现了BlockingQueue接口,底层是链表。可以选择一个上限。如果没有定义上限,将使用 Integer.MAX_VALUE 作为上限。
PriorityBlockingQueue:具有优先级的阻塞队列,所有插入到 PriorityBlockingQueue 的元素必须实现 java.lang.Comparable 接口。因此该队列中元素的排序就取决于你自己的 Comparable 实现。
SynchronousQueue :是一个特殊的队列,它的内部同时只能够容纳单个元素。实现了 BlockingQueue 接口
LinkedBlockingDeque:链阻塞队列 ,实现了BlockingDeque接口。
10.8 JUC线程池: ThreadPoolExecutor
线程池的作用:
1.降低资源消耗(线程无限制地创建,然后使用完毕后销毁)
2.提高响应速度(无需创建线程)
3.提高线程的可管理性
线程池的原理:
线程池是一个线程集合workerSet和一个阻塞队列workQueue。当用户向线程池提交一个任务(也就是线程)时,线程池会先将任务放入workQueue中,orkerSet中的线程会不断的从workQueue中获取线程然后执行。当workQueue中没有任务的时候,worker就会阻塞,直到队列中有任务了就取出来继续执行。
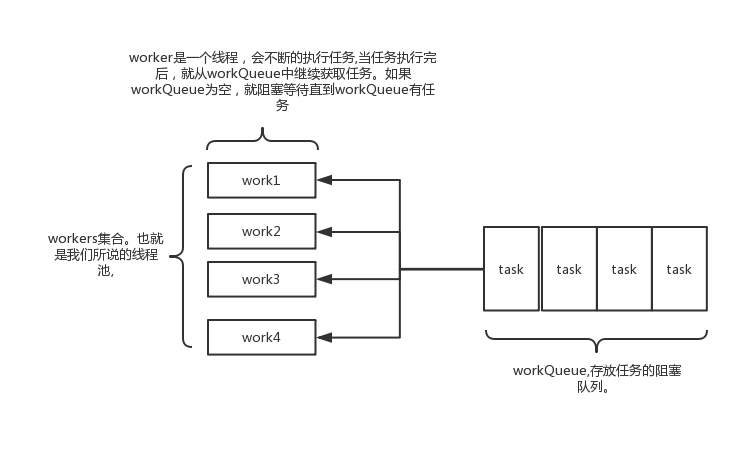
三种线程池类型:
newFixedThreadPool:线程池的线程数量达corePoolSize后,即使线程池没有可执行任务时,也不会释放线程。
newSingleThreadExecutor:初始化的线程池中只有一个线程,如果该线程异常结束,会重新创建一个新的线程继续执行任务,唯一的线程可以保证所提交任务的顺序执行。
newCachedThreadPool:在没有任务执行时,当线程的空闲时间超过keepAliveTime,会自动释放线程资源,当提交新任务时,如果没有空闲线程,则创建新线程执行任务,会导致一定的系统开销。
关闭线程池:
1.关闭方式 - shutdown :中断所有没有正在执行任务的线程。
2.关闭方式 - shutdownNow:停止所有正在执行或暂停任务的线程。
二、java IO
1、IO分类
从传输方式上分为:
字节流:

字符流:

字节流和字符流的区别:
1.字节流读取单个字节,字符流读取单个字符(一个字符根据编码的不同,对应的字节也不同,如 UTF-8 编码是 3 个字节,中文编码是 2 个字节。)
2.字节流用来处理二进制文件(图片、MP3、视频文件),字符流用来处理文本文件(可以看做是特殊的二进制文件,使用了某种编码,人可以阅读)。
从数据操作上IO可分为:
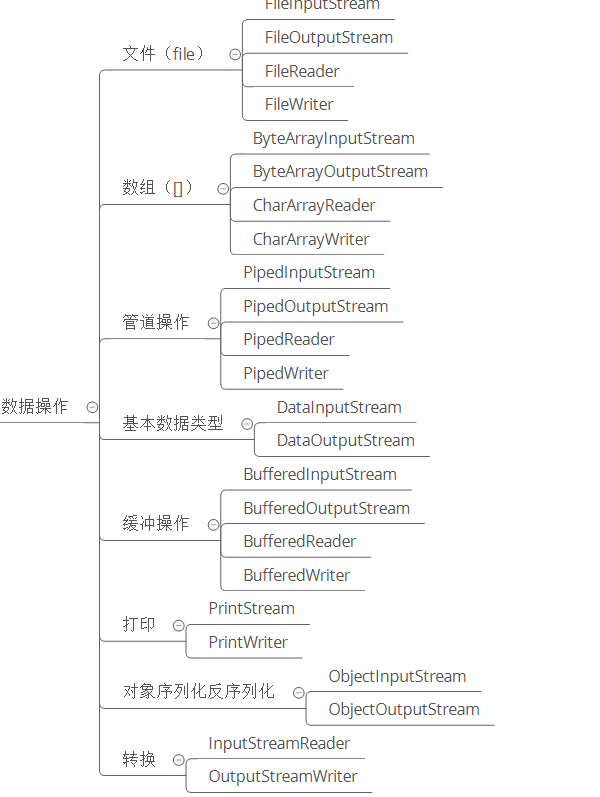
文件(file):
FileInputStream、FileOutputStream、FileReader、FileWriter
数组([]) :
字节数组(byte[]): ByteArrayInputStream、ByteArrayOutputStream
字符数组(char[]): CharArrayReader、CharArrayWriter
管道操作:
PipedInputStream、PipedOutputStream、PipedReader、PipedWriter
基本数据类型:
DataInputStream、DataOutputStream
缓冲操作: BufferedInputStream、BufferedOutputStream、BufferedReader、BufferedWriter
打印:
PrintStream、PrintWriter
对象序列化反序列化:
ObjectInputStream、ObjectOutputStream
转换:
InputStreamReader、OutputStreamWriter
2、Java IO采用装饰者模式
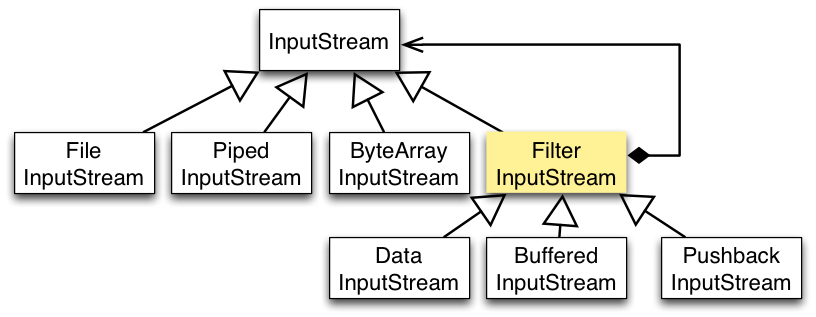
装饰者模式: 装饰者(Decorator)和具体组件(ConcreteComponent)都继承自组件(Component),具体组件的方法实现不需要依赖于其它对象,而装饰者组合了一个组件,这样它可以装饰其它装饰者或者具体组件。所谓装饰,就是把这个装饰者套在被装饰者之上,从而动态扩展被装饰者的功能。装饰者的方法有一部分是自己的,这属于它的功能,然后调用被装饰者的方法实现,从而也保留了被装饰者的功能。

以 InputStream 为例
1.InputStream 是抽象组件;
2.FileInputStream 是 InputStream 的子类,属于具体组件,提供了字节流的输入操作;
3.FilterInputStream 属于抽象装饰者,装饰者用于装饰组件,为组件提供额外的功能。例如 BufferedInputStream 为 FileInputStream 提供缓存的功能。
3、File类
3.1 常用方法
常用的获取功能的方法:
public String getAbsolutionPath( ) //返回绝对路径
public String getPath( ) //返回文件的路径名字字符串
public String getName( ) //返回File表示的文件或目录的名称
public long length( ) //返回File表示的文件的长度
判断功能的方法:
public boolean exists( ) //判断文件或者目录是否存在
public boolean isDirectory( ) //判断是否是目录
public Boolean isFile( ) //判断是否是文件
创建和删除的方法:
public boolean createNewFile( ) //该名称的文件不存在时,创建一个空文件,否则抛出异常
public Boolean delete( ) //删除该File表示的文件或者目录
public Boolean mkdir( ) //创建(单级)目录,多级目录会创建失败
public Boolean mkdirs( ) //创建(多级)目录,包括任何必须但不存在的父目录
注意:是文件或者目录,只与创建的方法有关
File file = new File(“D:\\a.txt”);
//创建的是一个名为“a.txt”的目录。是文件或者目录,只与创建的方法有关
file.mkdir( );
File类的遍历目录功能:
public String[] list( ) //返回一个String数组,表示File目录中的所有子目录/文件
public File[] listFiles( ) //返回一个File数组,表示File目录中的所有子目录/文件
注意:遍历的是构造方法给出的目录,如果路径不存在,或者该路径不是一个目录,会抛出空指针异常
3.2 文件过滤器
File[] listFiles( FilenameFiler filter )//遍历方法目录,得到每一个文件对象
//java.io.FilenameFiler接口,实现该接口的类实例可用于过滤器文件名
//重写接口中的抽象方法:
boolean accept(File dir,String name)
boolean accept(File pathname )//测试指定抽象路径名是否在某个路径名列表中
文件过滤器实例:
import java.io.File;
import java.io.FileFilter;
public class FileTest01 {
public static void main(String[] args) {
File file = new File("D:\\filetest");
System.out.println(file.exists());
getAllFile(file);
}
public static void getAllFile(File dir){
File[] files = dir.listFiles(new FileFilterimpl());
for (File file : files) {
if (file.isDirectory()){
getAllFile(file);
}else {
System.out.println(file);
}
}
}
}
class FileFilterimpl implements FileFilter{
@Override
public boolean accept(File pathname) {
return pathname.getName().endsWith(".txt");
}
}
4、字节流
4.1 输入流 inputstream
InputStream(接口)定义了所有子类共有的方法:
int read( ); //读取下一个字节,每次读取一个字节
int read( byte[] b ); //从流中读取一定数量的字节,存放在缓冲区b数组中
void close( );
FileInputStream(实现类)
构造方法: 创建一个对象,并将对象指向构造方法中要读取的文件
FileInputStream( String name );
FileInputStream( File file );
实例:
public static void main(String[] args) {
File file = new File("D:\\filetest\\a.txt"); //内容为:aaabbb
try {
InputStream inputStream = new FileInputStream(file);
int len = 0;
byte[] bytes = new byte[2]; //每次读两个字节
while ((len=inputStream.read(bytes))!=-1){
//read()返回的是int类型,这是由于java没有对应的【0·255】类型
//同时,如果是8位,可能出现8个1的字符(其补码为-1),这会和返回标志位冲突
//于是扩充为int
System.out.println(Arrays.toString(bytes));
}
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/*结果为:
[97, 97]
[97, 98]
[98, 98]
*/
4.2 输出流 outputstream
OutputStream(接口)定义的方法:
public void close( );
public void flush( ); //刷新,并强制任何缓冲的字节被写出
public void write( byte[ ] b );// 可以将字符串使用.getBytes()方法转换为字节数组,然后传入
public void write( byte[ ] b ,int off , int len );//从指定数组写入len字节,从off偏移量开始输出到流
public abstract void write( int b ); //将指定字节输出流
Fileoutstream(实现类)
作用:把内存中的数据写入到硬盘文件中
构造方法://参数是写入数据的目的地
FileOutputStream(String name) //目的地是一个路径名
FileOutputStream(File file) //目的地是一个文件
构造方法的作用:
1、 创建一个FileOutputStream对象
2、 会根据构造方法的参数,创建一个空的文件
3、 将FileOutputStream对象指向创建好的文件
FileOutputStream 追加/续写的构造方法:
FileOutputStream(String name,boolean append) //目的地是一个路径名
FileOutputStream(File file, boolean append) //目的地是一个文件
写入的原理: Java程序——>JVM——>OS——>OS调用写数据的方法——>写入文件
实例:
public static void main(String[] args) {
File file = new File("D:\\filetest\\a.txt");
try(OutputStream outputStream = new FileOutputStream(file)){
outputStream.write(new String("abc").getBytes()); //写入字节
outputStream.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
5、字符流
5.1 输入流 Reader
Reader抽象类,定义的共性成员方法:
int read( ); //读取单个字符,并返回,返回-1表示到达结尾
int read(char[] cbuf); //一次读入多个字符,并返回给数组
void close( );
FileReader实现类
构造方法:创建一个FileReader对象,并指向要读取的文件
FileReader(String filename);
FileReader(File file);
实例:
public static void main(String[] args) {
try {
Reader reader = new FileReader(new File("D:\\filetest\\a.txt"));
int len;
char[] chars = new char[1];
while ((len=reader.read(chars))!=-1){
System.out.println(chars);
}
} catch (IOException e) {
e.printStackTrace();
}
}
/*结果:
a
a
a
b
b
b
*/
5.2 输出流 Writer
Writer(抽象类)定义的共性成员方法:
void write (int c);//写入字符
void write (char[] cbuf) ; //写入字符数组
void write (String str);
void write (String str,int off,int len);
void flush ( ); //刷新缓冲
void close ( );
FileWriter 实现类
构造方法:创建一个FileWriter对象,并指向要写入的文件
FileWriter(String filename);
FileWriter(File file);
续写、添加(构造方法):
FileWriter(String filename, boolean append);
FileWriter(File file, boolean append);
注意:fileWriter.writer()是先把数据写到内存中,如果没有调用: flush ( )、close ( ),则数据并不会写入硬盘。如果使用close ( ),则流就不能再用了。
实例:
public static void main(String[] args) throws IOException {
Writer writer = new FileWriter(new File("D:\\filetest\\a.txt"));
writer.write("abccd");
writer.flush();
writer.close();
}
6、Properties集合
特点:
1.继承 Hashtable<Object,Object>,是双列集合,Key和Value默认为字符串
2.Properties是唯一一个和IO流相结合的集合:使用store()方法,把集合中的临时数据持久化写入到硬盘里存储;使用load()方法,把硬盘里的文件写入到集合中存储
Properties类中的方法:
Object setProperty(String key,String value); //调用HashTable中的put
String getProperty(String key); //通过key找到value,相当于Map集合中的get(key)
Set<String> stringPropertyNames( ); //返回列表中的键集
void store ( OutputStream out, String comments ); // comments为注释,不能存储中文字符
void store ( Writer writer, String comments); //可以存储中文字符
void load( InputStream instream ); //不能载入中文字符
void load( Reader reader ); //可以载入中文字符
实例:
写入:
public static void main(String[] args) throws IOException {
FileWriter writer = new FileWriter(new File("D:\\filetest\\a.txt"));
Properties properties = new Properties();
properties.setProperty("小米","雷军");
properties.setProperty("苹果","乔布斯");
properties.setProperty("锤子","罗永浩");
properties.store(writer,"save data");
writer.close();
}
/*D:\\filetest\\a.txt内容
#save data
#Sat Jun 25 21:42:13 CST 2022
小米=雷军
锤子=罗永浩
苹果=乔布斯
*/
读:
public static void main(String[] args) throws IOException {
FileReader reader = new FileReader(new File("D:\\filetest\\a.txt"));
Properties properties = new Properties();
properties.load(reader);
Set<Object> keySet = properties.keySet();
for (Object s :
keySet) {
System.out.println(s+":"+properties.get(s));
}
// Set<Map.Entry<Object, Object>> entries = properties.entrySet();
// Iterator<Map.Entry<Object, Object>> iterator = entries.iterator();
// while (iterator.hasNext()){
// Map.Entry<Object, Object> next = iterator.next();
// System.out.println(next.getKey()+": "+next.getValue());
// }
reader.close();
}
7、缓冲流(前几种流的增强)
返回时不再是一个字节一个字节返回,而是以一个数组的形式返回
1.java.io.BufferedOutputStream(extends outputStream)
构造方法:
BufferedOutputStream(OutputStream out);
BufferedOutputStream(OutputStream out, int size); //指定缓冲流内部缓冲区的大小
2.java.io.BufferedInputStream(extends InputStream)
构造方法:
BufferedInputStream(InputStream in);
BufferedInputStream(InputStream in, int size);
3.java.io.BufferedWriter(extends Writer)
构造方法:
BufferedWriter(Writer out);
BufferedWriter(Writer out,int size);
4.java.io.BufferedReader(extends Reader)
构造方法:
BufferedReader (Reader in);
BufferedReader (Reader in,int size);
特有方法:
String readline(); //读取一行数据,返回值不包含终止符
8、字符转换流
OutputStreamWriter类:
构造方法:
OutputStreamWriter( OutputStream out); //创建使用默认编码的OutputStreamWriter
OutputStreamWriter(OutputStream out,String charsetName);//创建使用charsetName编码的类
InputStreamReader类:
构造方法:
OutputStreamReader ( InputStream in); //创建使用默认编码的InputStreamWriter
OutputStreamReader (InputStream in,String charsetName);//创建使用charsetName编码的类
9、序列化流和反序列化流
原理:
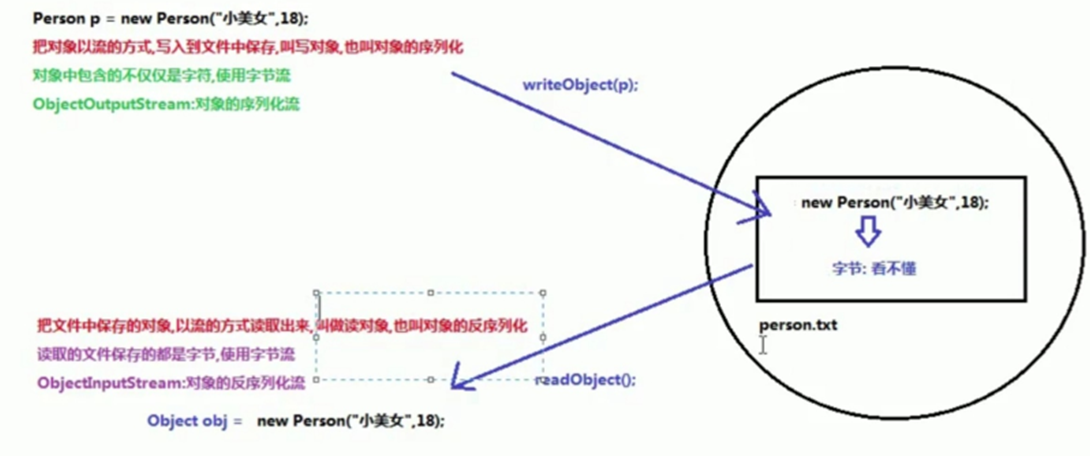
注意:
1.需要序列化的对象,必须实现Serializable接口,对对象进行标记;
2.被transient关键字修饰的成员变量,不能被序列化;
3.静态优先于非静态加载到内存中,所以被static修饰的成员变量不能被序列化。
1.ObjectOutputStream(extends OutputStream)——序列化对象
构造方法:
ObjectOutputStream(OutputStream out);
特有的成员方法:
void writeObject(Object obj);
2.ObjectInputStream(extends InputStream)——反序列对象
构造方法:
ObjectInputStream(InputStream in);
特有的成员方法:
void ReadObject( );
实例:
//序列化对象
public class ObjectOutputStreamTest {
public static void main(String[] args) throws IOException {
OutputStream outputStream = new FileOutputStream(new File("D:\\filetest\\b.txt"));
ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream);
Person person = new Person("小明","男",18);
objectOutputStream.writeObject(person);
objectOutputStream.flush();
objectOutputStream.close();
}
}
class Person implements Serializable {
String name;
String sex;
transient int age;
public Person(String name,String sex,int age){
this.name = name;
this.sex = sex;
this.age = age;
}
@Override
public String toString() {
return this.name+","+this.sex+","+this.age;
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
InputStream inputStream = new FileInputStream(new File("D:\\filetest\\b.txt"));
ObjectInputStream objectInputStream = new ObjectInputStream(inputStream);
Object o = objectInputStream.readObject();
System.out.println(o);
}
/*结果:
小明,男,0
*/
10、PrintStream打印流
PrintStream类:
特点:
1.只责数据的输出,不负责数据的读取;
2.与其他输出流不同,PrintStream不会抛出IOException异常;
构造方法:
PrintStream(File file);
PrintStream(OutStream out);
PrintStream(String filename);
实例:
public static void main(String[] args) throws FileNotFoundException {
PrintStream ps = new PrintStream(new File("D:\\filetest\\c.txt"));
System.setOut(ps);
System.out.println("打印字符串到c.txt文件中");
ps.close();
}















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









