







 本文深入探讨Spark SQL的架构,包括Parser、Analyzer、Optimizer和SparkPlanner的角色。讲解了如何从SQL语句转化为DAG操作,重点分析了基于规则的优化(RBO),如PushdownPredicate、ConstantFolding和ColumnPruning,以及它们如何提升查询性能。同时,文章提及了BroadcastJoin在小表查询中的应用,为后续的Cost-Based Optimization(CBO)奠定了基础。
本文深入探讨Spark SQL的架构,包括Parser、Analyzer、Optimizer和SparkPlanner的角色。讲解了如何从SQL语句转化为DAG操作,重点分析了基于规则的优化(RBO),如PushdownPredicate、ConstantFolding和ColumnPruning,以及它们如何提升查询性能。同时,文章提及了BroadcastJoin在小表查询中的应用,为后续的Cost-Based Optimization(CBO)奠定了基础。
原创文章,转载请务必将下面这段话置于文章开头处。
本文转发自技术世界,原文链接 http://www.jasongj.com/spark/rbo/本文所述内容均基于 2018年9月10日 Spark 最新 Release 2.3.1 版本。后续将持续更新
Spark SQL 架构
Spark SQL 的整体架构如下图所示
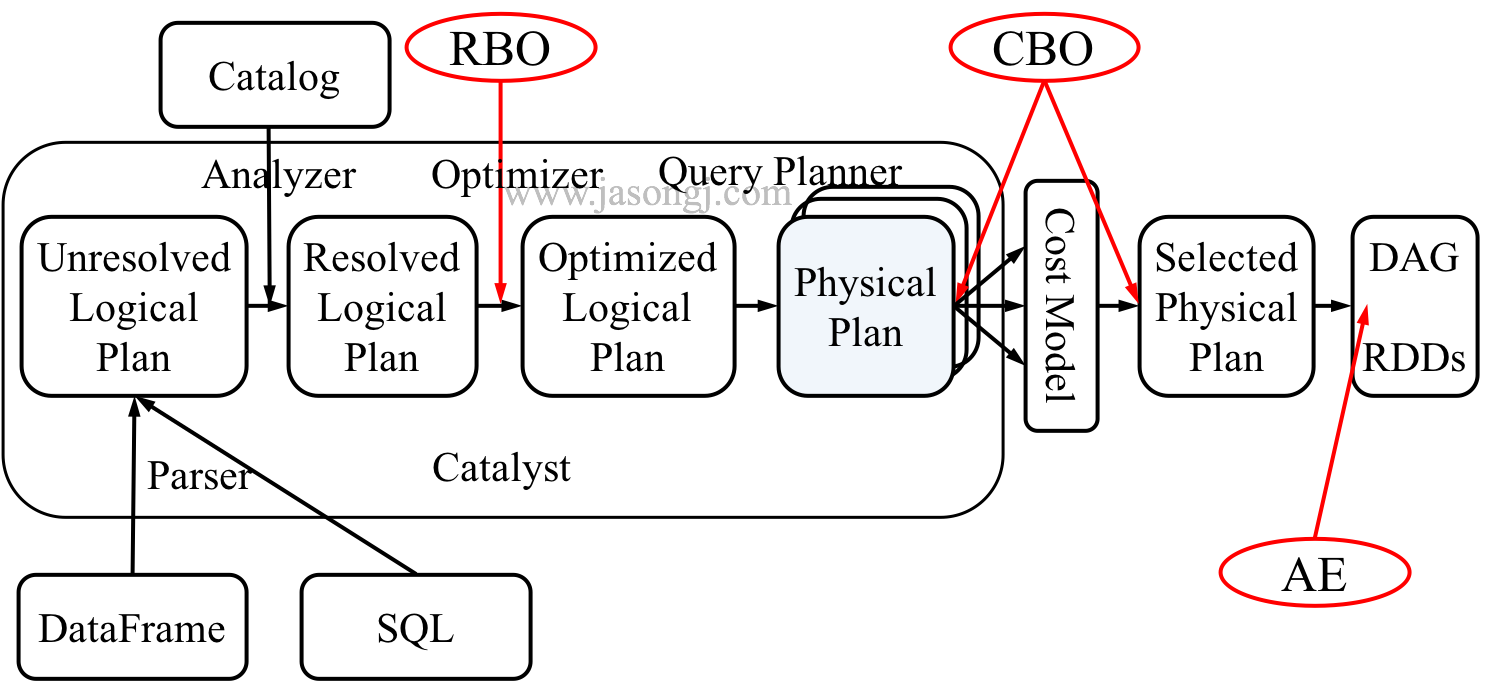
从上图可见,无论是直接使用 SQL 语句还是使用 DataFrame,都会经过如下步骤转换成 DAG 对 RDD 的操作
- Parser 解析 SQL,生成 Unresolved Logical Plan
- 由 Analyzer 结合 Catalog 信息生成 Resolved Logical Plan
- Optimizer根据预先定义好的规则对 Resolved Logical Plan 进行优化并生成 Optimized Logical Plan
- Query Planner 将 Optimized Logical Plan 转换成多个 Physical Plan
- CBO 根据 Cost Model 算出每个 Physical Plan 的代价并选取代价最小的 Physical Plan 作为最终的 Physical Plan
- Spark 以 DAG 的方法执行上述 Physical Plan
- 在执行 DAG 的过程中,Adaptive Execution 根据运行时信息动态调整执行计划从而提高执行效率
Parser
Spark SQL 使用 Antlr 进行记法和语法解析,并生成 UnresolvedPlan。
当用户使用 SparkSession.sql(sqlText : String) 提交 SQL 时,SparkSession 最终会调用 SparkSqlParser 的 parsePlan 方法。该方法分两步
- 使用 Antlr 生成的 SqlBaseLexer 对 SQL 进行词法分析,生成 CommonTokenStream
- 使用 Antlr 生成的 SqlBaseParser 进行语法分析,得到 LogicalPlan
现在两张表,分别定义如下
CREATE TABLE score (
id INT,
math_score INT,
english_score INT
)CREATE TABLE people (
id INT,
age INT,
name INT
)对其进行关联查询如下
SELECT sum(v)
FROM (
SELECT< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1434
1434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









