







Spark SQL Catalyst CBO
上文Spark SQL 内部原理中介绍的 Optimizer 属于 RBO,实现简单有效。它属于 LogicalPlan 的优化,所有优化均基于 LogicalPlan 本身的特点,未考虑数据本身的特点,也未考虑算子本身的代价。
Catalyst 优化器的逻辑优化过程包含两个环节:逻辑计划解析和逻辑计划优化。逻辑优化的最终目的就是要把 Unresolved Logical Plan 从次优的 Analyzed Logical Plan 最终变身为执行高效的 Optimized Logical Plan。
本文将介绍 CBO,它充分考虑了数据本身的特点(如大小、分布)以及操作算子的特点(中间结果集的分布及大小)及代价,从而更好的选择执行代价最小的物理执行计划,即 SparkPlan。
Spark CBO 原理
CBO 原理是计算所有可能的物理计划的代价,并挑选出代价最小的物理执行计划。其核心在于评估一个给定的物理执行计划的代价。
物理执行计划是一个树状结构,其代价等于每个执行节点的代价总合,如下图所示。
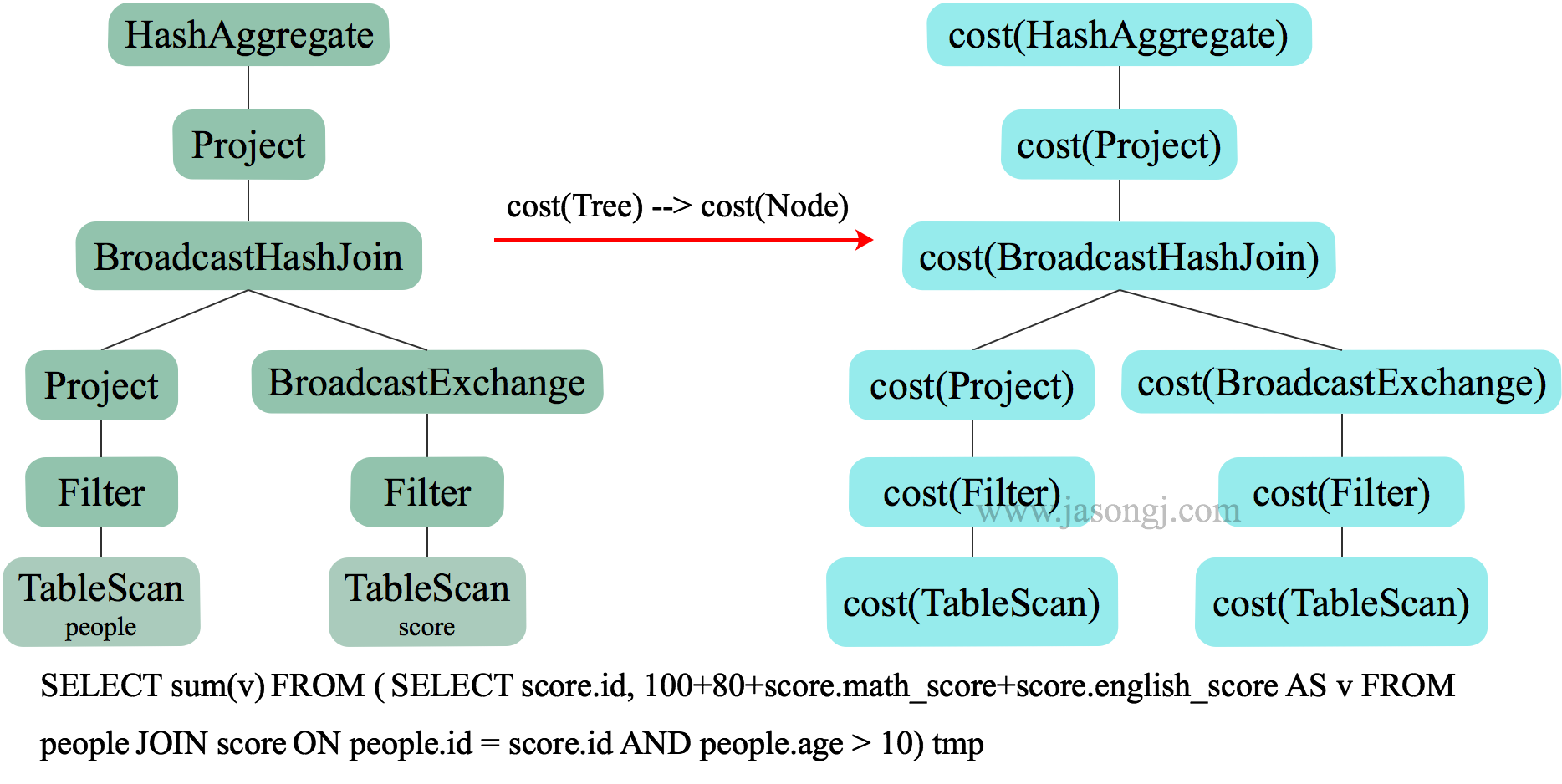
而每个执行节点的代价,分为两个部分
- 该执行节点对数据集的影响,或者说该节点输出数据集的大小与分布
- 该执行节点操作算子的代价
每个操作算子的代价相对固定,可用规则来描述。而执行节点输出数据集的大小与分布,分为两个部分:
- 初始数据集,也即原始表,其数据集的大小与分布可直接通过统计得到;
- 中间节点输出数据集的大小与分布可由其输入数据集的信息与操作本身的特点推算。
所以,最终主要需要解决两个问题
- 如何获取原始数据集的统计信息
- 如何根据输入数据集估算特定算子的输出数据集
具体来讲就是要根据代价,选择合适的物理计划,也就是合适的算子执行方式,在优化 Spark Plan 的过程中,Catalyst 都有哪些既定的优化策略呢?从数量上来说,Catalyst 有 14 类优化策略,其中有 6 类和流计算有关,剩下的 8 类适用于所有的计算场景,如批处理、数据分析、机器学习和图计算,当然也包括流计算。因此,我们只需了解这 8 类优化策略。
Statistics 收集
通过如下 SQL 语句,可计算出整个表的记录总数以及总大小
ANALYZE TABLE table_name COMPUTE STATISTICS;
从如下示例中,Statistics 一行可见, customer 表数据总大小为 37026233 字节,即 35.3MB,总记录数为 28万,与事实相符。
spark-sql> ANALYZE TABLE customer COMPUTE STATISTICS;
Time taken: 12.888 seconds
spark-sql> desc extended customer;
c_customer_sk bigint NULL
c_customer_id string NULL
c_current_cdemo_sk bigint NULL
c_current_hdemo_sk bigint NULL
c_current_addr_sk bigint NULL
c_first_shipto_date_sk bigint NULL
c_first_sales_date_sk bigint NULL
c_salutation  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









