






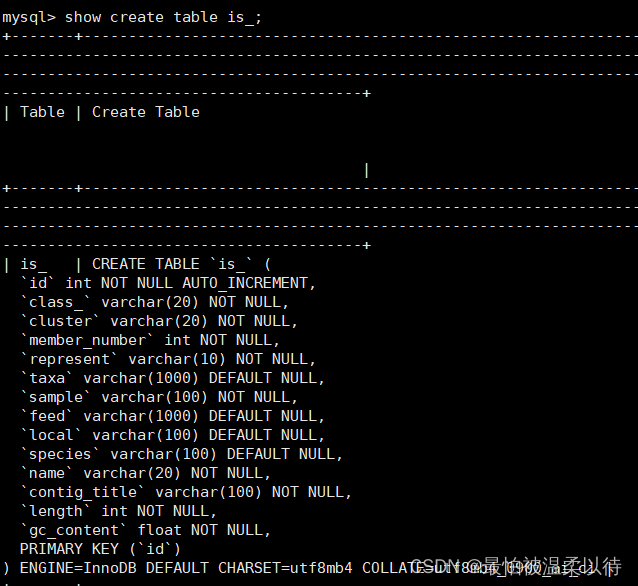
 当需要大批量数据上传到MySQL数据表时,使用INSERT语句会效率较低。文章推荐使用LOADDATAINFILE命令,如`loaddatainfileD:/ice.txtintotableiceignore1lines;`,此方法能快速导入位于D:/ice.txt的文件数据,并提示需忽略首行。注意确保数据文件的字段顺序与表结构匹配,以确保正确导入。
当需要大批量数据上传到MySQL数据表时,使用INSERT语句会效率较低。文章推荐使用LOADDATAINFILE命令,如`loaddatainfileD:/ice.txtintotableiceignore1lines;`,此方法能快速导入位于D:/ice.txt的文件数据,并提示需忽略首行。注意确保数据文件的字段顺序与表结构匹配,以确保正确导入。
当需要大批量数据上传到MySQL数据表时,使用INSERT语句会效率较低。文章推荐使用LOADDATAINFILE命令,如`loaddatainfileD:/ice.txtintotableiceignore1lines;`,此方法能快速导入位于D:/ice.txt的文件数据,并提示需忽略首行。注意确保数据文件的字段顺序与表结构匹配,以确保正确导入。
当需要大批量数据上传到MySQL数据表时,使用INSERT语句会效率较低。文章推荐使用LOADDATAINFILE命令,如`loaddatainfileD:/ice.txtintotableiceignore1lines;`,此方法能快速导入位于D:/ice.txt的文件数据,并提示需忽略首行。注意确保数据文件的字段顺序与表结构匹配,以确保正确导入。

















01-18
 2418
2418
2418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









