









第二版 mysql实时解析:
目前从第一版的hbase换到了第二版的kafka:
将traker与parser的交互组件的hbase替换为kafka。
其大体原因是:
1、对于解析的数据没必要永久存储,业务仅是需求回溯一周的数据,对数据的持久化保存特性并不做要求。
2、对于解析要求实时性,需要一个高吞吐量的组件来传递解析的数据,并且保证不重不丢。
整体结构设计:
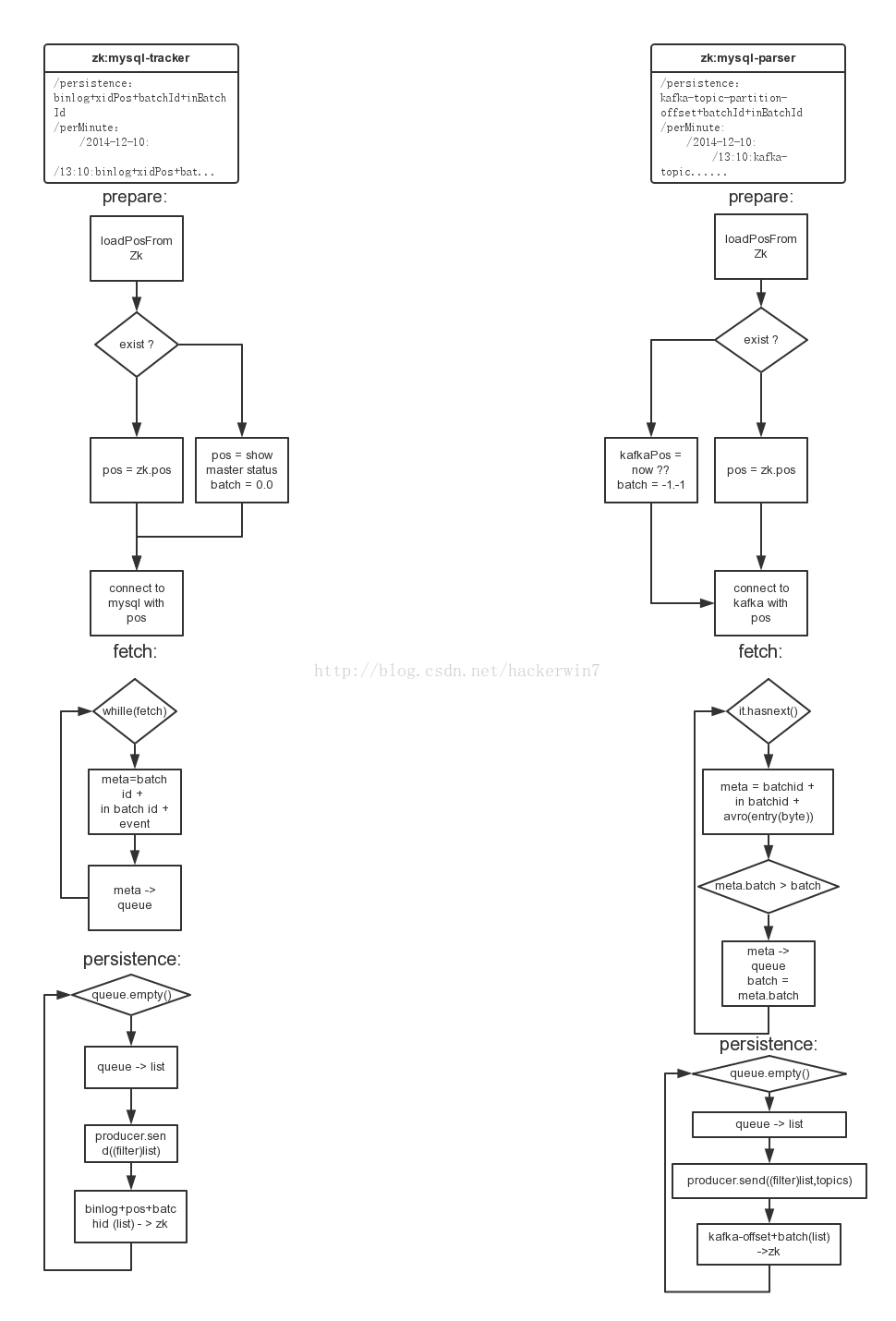
大致涉及到的外部组件有:mysql zookeeper kafka
性能测试:
基于单机式的测试目前tracker与parser的速度相近,每分钟 200万条数据。 具体情况视机器硬件配置等不同而波动。
结论:
基于提高程序吞吐量而升级了一版程序。
相关:
关于详细结构设计见 第一版 mysql实时解析程序 : http://blog.csdn.net/hackerwin7/article/details/39896173
github相关:
https://github.com/hackerwin7/mysql-tracker
https://github.com/hackerwin7/mysql-parser

















 683
683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









