







 本文详细解读PHP中HashTable的结构和工作原理,包括数据结构、API及算法,帮助开发者更好地理解和使用HashTable这一关键组件。
本文详细解读PHP中HashTable的结构和工作原理,包括数据结构、API及算法,帮助开发者更好地理解和使用HashTable这一关键组件。
目录
1.前言
2.HashTable的总体结构及思路
2.1 哈希表的相关数据结构
2.2 哈希表的总体结构图
2.3 哈希表元素的析构
3.HashTable的相关API及算法
1.前言
看过PHP源码的童鞋都知道,源码里面除了zval这个最常用的结构外,另外一个就是HashTable啦。在《Extending and Embeding PHP》一书的第八章,专门就讲哈希表的一些实现,国内的作者写的一本《PHP核心技术与最佳实践》里面也有一章讲哈希表,不过里面的图画的太难看了,当时没看源码去看它的图根本就看的一头雾水。这里写写日志,加深理解。
2.HashTable的总体结构及思路
2.1 哈希表的相关数据结构
索引数组(Vectors)和链表(Linked Lists)各有各的特点,比如说索引数组能实现O(1)的查找,而链表在插入删除元素的时候更方便。哈希表其实就是索引数组和链表的综合体。
首先看下哈希表的一些相关结构体,主要有两个HashTable和Bucket。
/PHP_5_4/Zend/zend_hash.h
/**哈希表的头部结构**/
typedef struct _hashtable {
uint nTableSize; //哈希表的大小,这个不是实际有多少个元素,因为一般需要预留一些空间,防止每次操作都去申请内存
uint nTableMask; //哈希表的掩码,这个用在计算元素应放在哪个Bucket用,初始化后是nTableSize-1
uint nNumOfElements; //哈希表实际有多少个元素
ulong nNextFreeElement; //下一个可用的元素索引
Bucket *pInternalPointer; //遍历这个哈希表的时候用到的内部指针
Bucket *pListHead; //哈希表的队列头部
Bucket *pListTail; //哈希表的队列尾部
Bucket **arBuckets; //哈希表的实际元素数组指针
dtor_func_t pDestructor; //哈希表的元素析构函数指针
zend_bool persistent; //是否持续,用作pmalloc的persistent参数
unsigned char nApplyCount; //zend_hash_apply的次数,这个用来限制嵌套遍历的层数,源码里面是限制为3层,例如foreach里面又套了foreach...
zend_bool bApplyProtection;//是否开启嵌套遍历的保护
#if ZEND_DEBUG
int inconsistent; //debug时用来记录哈希表的状态,HT_OK,HT_IS_DESTROYING,HT_DESTROYED,HT_CLEANING
#endif
} HashTable;
/**大家注意一下结构体成员的命名开头的第一个字母,很容易发现,第一个字母代表了这个元素的类型,
n代表number,
p代表pointer,
ar代表array
这个办法蛮不错的。
**/
/**哈希表里面的每个元素是使用一个桶的结构来存储的**/
typedef struct bucket {
ulong h; //哈希值,索引数组的时候会用到这个值
uint nKeyLength; //key的长度,如果是关联数组,这个就是那个key串的长度,如果是索引数组,这个长度设置为0,因此可以根据这个来判断是关联数组还是索引数组
void *pData; //元素的实际内容块的指针,这个与pDataPtr结合使用
void *pDataPtr; //存进哈希表的元素是一个指针的话,那指针直接放这里,pData指向pDataPtr即可。这样就防止存进一个指针类型数据还去emalloc产生一些内存碎片。
struct bucket *pListNext; //指向哈希链表中下一个元素
struct bucket *pListLast; //指向哈希链表中的前一个元素
struct bucket *pNext; //相同哈希值的下一个元素(哈希冲突用)
struct bucket *pLast; //相同哈希值的前一个元素(哈希冲突用)
const char *arKey; //key串,关联数组用
} Bucket;2.2 哈希表的总体结构图
下面画个图理解一下哈希表的总体结构:
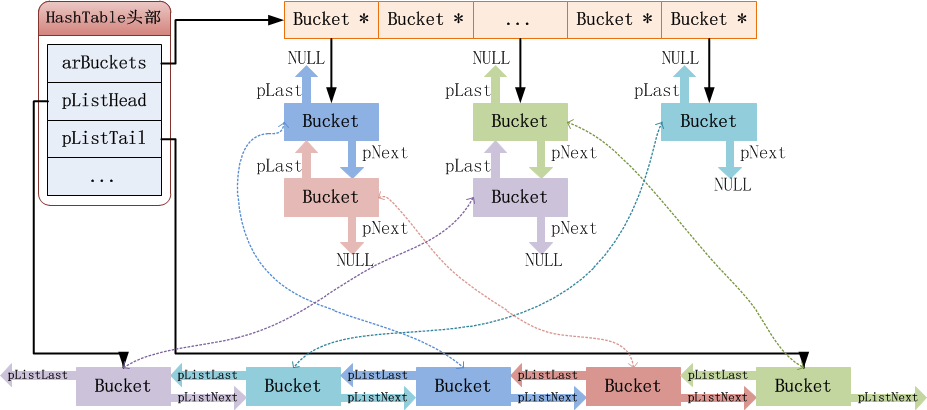
图中,左上角部分就是哈希表的头部啦,通过arBuckets结构体成员指向哈希表的指针数组,这些Bucket *指针初始化时一共有nTableSize个。
Bucket * 数组下面指向的就是一个一个实际的Bucket,那为什么下面这些bucket是个双向链表呢?这是为解决哈希冲突而设计的,如果两个元素的key哈希值相同,那么它们会分到同一个索引,那么就需要用双向链表把它们给链接起来了。
图底下是一个逻辑的队列。遍历一个关联数组的时候,如果没有一个逻辑的队列,那怎么去遍历数组呢?显然如果图右上角的从Bucket *数组一个一个去找元素,效率显然是比较低的,因为有很多是空的指针。这个逻辑队列的元素是右上角的所有元素组成的。相同颜色代表同一个bucket,用虚线连接。哈希表头部有两个成员pListHead和pListTail分别指向逻辑队列的头部和尾部。
读到这里,大家应该隐约能猜到,就是HashTable维护了两种双向链表,那么在哈希表的增加和删除元素的时候,就需要负责同时维护好这两种队列,保持一致性。
Bucket这个结构就不用画图了吧,比较简单,值得注意就是两个成员,pData和pDataPtr,这两个成员都是用来存储元素的实际数据用的,那么为什么需要两个呢?不是用一个指针指向一块内存地址不就得了?其实哈希表在添加元素的时候,会把传递的元素给copy一份(使用memcpy),如果拷贝的只是一个指针大小的数据,那么就没必要再使用pmalloc去分配内存了,直接放到pDataPtr里面去,然后pData指向pDataPtr就行了,这样就不会增加一些内存碎片。
2.3 哈希表元素的析构
哈希表元素的析构函数放在哈希表头部结构的pDestructor指针里,它的类型定义如下:
typedef void (*dtor_func_t)(void *pDest);一个哈希表里面的元素可以放各种类型,例如一个zval *指针,一个整数,一个字符串,一个哈希表等。那么问题来了,那写一个能处理各种类型的数据的析构函数岂不是得考虑各种情况,肯定得崩溃了!所以肯定不能这么干。有两个解决的思路:第一种就是使用哈希表时保证元素只有一种类型,这样写一个简单的析构函数就行了。第二种就是,把元素对应一个结构体,结构体包括数据指针和数据的析构函数指针,这样,存进哈希表的实际就是一个个结构体,pDestructor运行时,就去这个结构体里面找到析构函数指针,去把相应的内容的内存释放掉就行了。PHP源码里面在处理资源(Resource)的时候就是采用第二种方法。
3.哈希表的相关API和算法
api比较多,写在笔记里面,有时间再整理。有兴趣的看我的有道笔记吧 ->哈希表相关API

















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









