









第1章 数据仓库概念
数据仓库( Data Warehouse ),是为企业制定决策,提供数据支持的。可以帮助企业,改进业务流程、提高产品质量等。
数据仓库的输入数据通常包括:业务数据、用户行为数据和爬虫数据等
业务数据:就是各行业在处理事务过程中产生的数据。比如用户在电商网站中登录、下单、支付等过程中,需要和网站后台数据库进行增删改查交互,产生的数据就是业务数据。业务数据通常存储在MySQL、Oracle等数据库中。
用户行为数据:用户在使用产品过程中,通过埋点收集与客户端产品交互过程中产生的数据,并发往日志服务器进行保存。比如页面浏览、点击、停留、评论、点赞、收藏等。用户行为数据通常存储在日志文件中。
爬虫数据:通常是通过技术手段获取其他公司网站的数据。
ODS(原始数据层):备份
DIM(公共维度层):存储维度表数据
DWD(明细数据层):数据清洗、脱敏
DWS(汇总数据层):聚合
ADS(数据应用层):统计
流程:数据输入(业务数据等)——数据分析(Data Warehouse)——数据输出(可视化报表、用户画像)
第2章 项目需求及架构设计
2.2.2 系统数据流程设计
使用Nginx将数据发到Springboot服务器
业务到mysql
用户到logfile,然后通过flume采集,到Kafka然后到Hadoop
ads到MySQL进行可视化
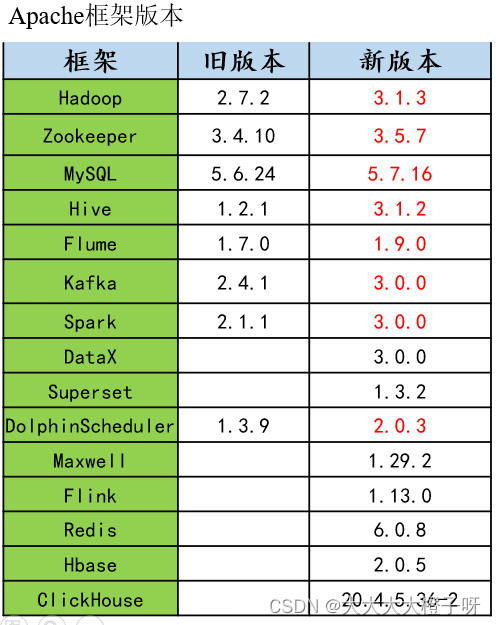
2.2.3 框架版本选型
2.2.6 集群资源规划设计
在企业中通常会搭建一套生产集群和一套测试集群。生产集群运行生产任务,测试集群用于上线前代码编写和测试。
1)生产集群
(1)消耗内存的分开
(2)数据传输数据比较紧密的放在一起(Kafka 、Zookeeper)
(3)客户端尽量放在一到两台服务器上,方便外部访问
(4)有依赖关系的尽量放到同一台服务器(例如:Hive和mysql)
2)测试集群服务器规划
| 服务名称 | 子服务 | 服务器 hadoop102 | 服务器 hadoop103 | 服务器 hadoop104 |
| HDFS | NameNode | √ | ||
| DataNode | √ | √ | √ | |
| SecondaryNameNode | √ | |||
| Yarn | NodeManager | √ | √ | √ |
| Resourcemanager | √ | |||
| Zookeeper | Zookeeper Server | √ | √ | √ |
| Flume(采集日志) | Flume | √ | √ | |
| Kafka | Kafka | √ | √ | √ |
| Flume (消费Kafka日志) | Flume | √ | ||
| Flume (消费Kafka业务) | Flume | √ | ||
| Hive | √ | √ | √ | |
| MySQL | MySQL | √ | ||
| DataX | √ | √ | √ | |
| Spark | √ | √ | √ | |
| DolphinScheduler | ApiApplicationServer | √ | ||
| AlertServer | √ | |||
| MasterServer | √ | |||
| WorkerServer | √ | √ | √ | |
| LoggerServer | √ | √ | √ | |
| Superset | Superset | √ | ||
| Flink | √ | |||
| ClickHouse | √ | |||
| Redis | √ | |||
| Hbase | √ | |||
| 服务数总计 | 20 | 11 | 12 |















 3764
3764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









